

A Portfolio That Practices MRE
Vishnu Purohitham’s four shipped projects are a worked example of Model Reliability Engineering — and a soft hit on most of the AIfolio.

TL;DR - Most early-career AI portfolios show the AIfolio pillars — RAG, tool-use, multi-agent orchestration — and stop at “demo runs once.” Vishnu Purohitham’s GitHub is rarer because the projects come pre-equipped with the parts MRE calls harness engineering: fallback chains, validation gates, quality thresholds, graceful degradation. The context engineering layer is real too — a T5 fine-tuned on the 226K-article XSum corpus (or 300K-article CNN-DailyMail) on Northeastern’s H200 cluster, BLIP adapted with LoRA r=16, BGE-base-en-v1.5 embeddings at 768 dimensions, hybrid dense + keyword search. Three of four AIfolio pillars are touched. Persistent memory is the honest gap. The hire/study signal isn’t completeness — it’s that the harness wasn’t an afterthought. If you’re staffing AI engineers and you want a filter for MRE instincts, this is the kind of portfolio to compare against. If you’re building one, copy the disposition: harness with the model, not after it.
Why this builder is worth a closer look
There’s a recognizable shape to most AI engineering portfolios in late 2025 and 2026: a chatbot, a RAG demo, a “GPT wrapper for [niche],” and maybe one fine-tuning notebook. They show familiarity with the stack. They don’t show that the builder has internalized what production AI actually requires — the unglamorous infrastructure that sits around the model and decides whether the system survives contact with real input.
Vishnu Purohitham is a Northeastern-affiliated builder whose portfolio inverts that ratio. Across four shipped projects — one a graduate-class capstone, three from hackathons spanning local Northeastern events to MIT’s Bitcoin Expo — the same architectural commitments show up. It’s the consistency that’s interesting, not any single project.
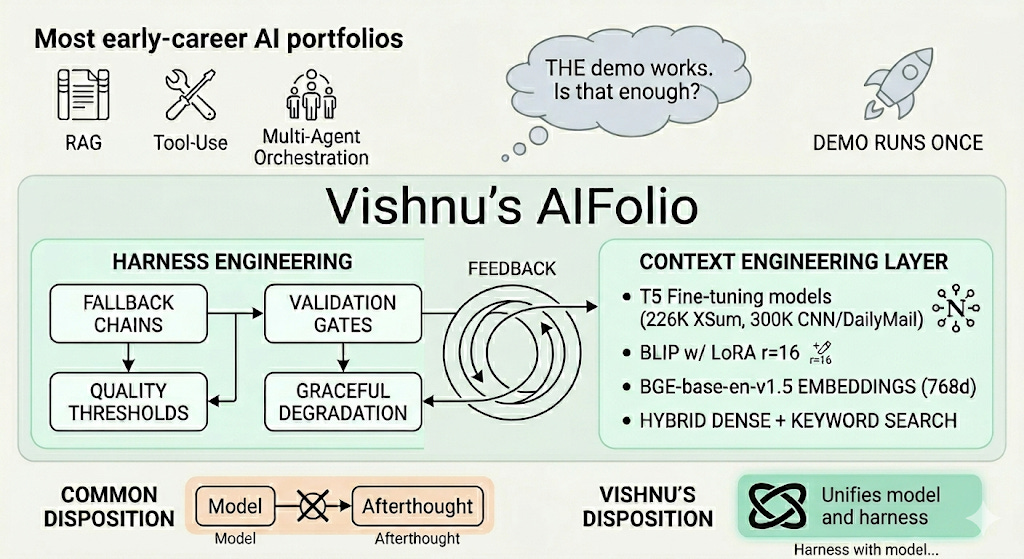
Vishnu’s AIFolio
This Builder Spotlight reads the work through two frameworks. The AIfolio framework gives us a way to talk about what an AI portfolio should contain — RAG with real evaluation, multi-agent orchestration, tool-use boundaries, persistent memory. Model Reliability Engineering (MRE) gives us a way to talk about how it should be built — split into context engineering (what the model sees at inference time) and harness engineering (the control layer governing what the user sees). Together they answer the question hiring managers actually care about: does this builder ship things, or does this builder ship things that hold up?
The four projects, in one paragraph each
InfoRetrieval v2 — A multimodal RAG system for personal knowledge management. Ingests URLs, PDFs, DOCX files, raw text, images, and Chrome bookmarks through a four-layer pipeline. Web scraping uses Playwright with a Trafilatura fallback. OCR runs EasyOCR first, then Tesseract if the first pass returns less than 20 characters. Summarization uses a T5 fine-tuned on either XSum (226K articles) or CNN-DailyMail (300K articles) on Northeastern’s H200 HPC cluster. Image captioning uses BLIP with a LoRA adapter (r=16, alpha=32). Storage is ChromaDB with hybrid dense + keyword search. Whole thing ships as a Docker Compose stack with a React frontend.
Boston 311 AI Agent — A multilingual (English / Spanish / Portuguese) agent for Boston city services, built in under 36 hours at a Northeastern hackathon. The interesting choice isn’t the agent — it’s the orchestration. The agent fans out parallel tool calls across four live Boston Open Data sources (311 cases, weather, events, neighborhood trends) and streams reasoning back to the frontend over SSE. The visible reasoning panel isn’t a UX flourish; it’s a trust mechanism for users (older adults, non-English speakers) who would otherwise have no way to evaluate whether the answer is grounded.
Zero-Shot Video Annotator — A FiftyOne plugin built at the Voxel51 / Twelve Labs hackathon. The interesting design move: instead of training a classifier, it uses Twelve Labs Pegasus to generate natural-language descriptions of each clip, then matches those descriptions to a user-defined taxonomy via cosine similarity over Marengo embeddings (512-dim). Tested on a 691-clip workplace safety dataset across 8 behavior categories. Local API caching reportedly cut inference costs by 80%. Built-in human-in-the-loop review surfaces low-confidence predictions for manual sign-off.
PulseMesh — A smartphone-based environmental DePIN built at the MIT Bitcoin Expo 2026 Virtual Hackathon. Native Android app collects sensor data (air pressure, noise, light) in the background, with a built-in Lightning wallet for instant micropayments via the L402 protocol. Backend includes a four-stage validation pipeline that detects spoofed readings before data hits the buyer-facing marketplace. Privacy-first design aggregates locations to city-block level before sale.
Two are flagship-quality builds. Two are 36-hour hackathon outputs. The architectural commitments are identical.
Where the AIfolio shows up — and where it doesn’t
The AIfolio framework names four pillars an AI engineer’s portfolio should evidence: a RAG pipeline with real evaluation, a multi-agent system that solves a real problem, an MCP / tool-use integration with sensible boundaries, and a persistent memory architecture. We don’t score Vishnu’s portfolio against this — that turns a spotlight into an audit, and the AIfolio is a reference for the concepts present, not a checklist a builder has to pass. The interesting reading is which pillars Vishnu has built around and which one he hasn’t.
RAG with real evaluation is built around in InfoRetrieval v2 — and “evaluation” is the word that earns it the hit. The training pipeline reports ROUGE-1, ROUGE-2, and ROUGE-L on summarization, plus BLEU for captioning. Most “AIfolio RAG” demos skip the eval. This one ships it.
Tool-use with sensible boundaries is built around in two places. The Boston 311 agent fans out parallel tool calls across four data sources with the reasoning panel exposed to the user — boundary as transparency. Zero-Shot Annotator routes low-confidence predictions to a human reviewer instead of writing them blindly to the labelset — boundary as fallback. Different mechanisms, same disposition: the tool-use isn’t the whole answer, and the system knows it.
Multi-agent orchestration is approached, not fully delivered. The Boston 311 build is parallel tool-calling, not multi-agent in the canonical sense (no negotiation between agents, no planner-worker split). Worth naming honestly: the orchestration skill is real, the multi-agent label is generous.
Persistent memory is the honest gap. Nothing in the four projects builds a cross-session memory layer (Mem0, Letta, Zep, or a custom architecture). Worth being clear about — if Vishnu wanted to round out the AIfolio, this is the next project to ship.
The pillars are reference points for what’s present. The more interesting question is how what’s present has been built. That’s MRE.
What the projects look like through the MRE lens
MRE splits production AI work along two axes. Context engineering governs what the model knows at inference time — fine-tuning, RAG, embedding strategy, knowledge freshness, retrieval precision. Harness engineering governs what the user sees — guardrails, output validation, fallback paths, faithfulness checks, graceful degradation, auditability.
Most AI demos do the first. Vishnu’s projects do both. That’s the signal.
Context engineering, layer by layer
InfoRetrieval v2 is the project where the context engineering is most visible, and it’s done with care.
The summarizer isn’t FLAN-T5 off the shelf — it’s a T5-base fine-tuned for 3 epochs on XSum or CNN-DailyMail at batch size 16 and learning rate 3e-5, with beam search at 4 beams and a 1.2 repetition penalty for inference. The image captioner isn’t BLIP off the shelf — it’s BLIP with a LoRA adapter trained on Flickr8k at r=16, alpha=32, dropout 0.05. The embedder is BGE-base-en-v1.5 at 768 dimensions — a deliberate choice over default OpenAI embeddings, with retrieval running as hybrid dense + keyword search rather than pure cosine.
What’s worth naming: this isn’t fine-tuning for the sake of “I trained something.” Each model on the path has been picked or adapted to the role it plays in the pipeline. T5 because summarization is a sequence-to-sequence problem with strong public benchmarks. BGE because the embedder is a retrieval surface with its own SLO and the MTEB leaderboard is a real signal. Hybrid search because pure dense retrieval misses keyword-exact matches and the system has to handle both.
The Chrome bookmark sync and watchdog file consumer are the part most readers will overlook. These are context freshness mechanisms — automatic re-ingestion as new content lands. MRE treats freshness as a context-layer SLO; this project ships the plumbing for it.
Harness engineering as the standout signal
Harness engineering is where Vishnu’s portfolio separates itself from the median. The pattern repeats across all four projects: any layer where input variation can break the system has a backup path and a quality check that decides which path runs.
The minimal viable shape:
def extract(input_data):
primary_result = primary_extractor(input_data)
if quality_check(primary_result) >= THRESHOLD:
return primary_result, “primary”
fallback_result = fallback_extractor(input_data)
return fallback_result, “fallback”
InfoRetrieval v2’s web scraper runs Trafilatura first because it’s faster and lighter, and falls back to Playwright only if static extraction returns less than 50 characters. The OCR pipeline runs EasyOCR first and falls back to Tesseract if the first pass returns less than 20 characters, then returns a tuple of (text, method) where method is one of “easyocr”, “tesseract”, “combined”, or “none”. That last detail matters — auditability of which path actually ran is what makes the system debuggable three months later.
PulseMesh’s four-stage spoofing detection is the harness pointed at sensor data instead of extractor output, but it’s the same architectural move. Zero-Shot Annotator’s HITL review queue is the same move applied to model confidence — low-confidence predictions don’t get written silently, they get surfaced. The Boston 311 agent’s visible reasoning panel is the same move applied to user trust — the user can see what tools the agent called and decide whether to trust the answer.
What to call out: the validation layer isn’t decorative. It’s the part that lets the system know its own confidence, which is the precondition for graceful degradation. MRE treats this as the harness engineer’s primary deliverable. Vishnu ships it on a hackathon timeline.
Where the edges show
Every project has visible trade-offs. Calling them out is the difference between a profile and a puff piece.
InfoRetrieval v2 doesn’t scale past one machine. ChromaDB’s persistent client is single-process. The watchdog file consumer is async but in-process. None of this is wrong for a CS5130 capstone — but the architecture as written maxes out around one user with one Chrome bookmark file and one watched directory. Multi-user deployment would require a real DB tier, a job queue, and an actual auth layer. The README is honest about this; it doesn’t claim to be SaaS-ready.
The Boston 311 agent was built in 36 hours. That shows. Sub-2-second latency is impressive for a parallel-tool-calling agent, but error handling for stale data sources, partial tool failures, or rate-limited Open Data endpoints would all need real work for a public deployment.
Zero-Shot Annotator’s 80% cost reduction is from caching. The first annotation pass on any new dataset is expensive. The plugin is a good fit for “annotate this dataset once, then iterate on labels” — and a poor fit for “annotate streaming video as it arrives.” Worth knowing before you adopt it.
PulseMesh’s four-stage validation adds latency and a trust assumption. The validators themselves can be wrong. A determined spoofer with knowledge of the validation pipeline can defeat statistical detection. The architecture is correct for an MVP DePIN; it would need a slashing or reputation mechanism to survive at scale.
The persistent memory pillar isn’t built around at all. None of the four projects ship a cross-session memory architecture. For an AIfolio that’s “complete,” this is the next project. The honest read: three of four pillars touched, with strong harness engineering compensating for the gap.
None of these are dealbreakers. They’re the edges of work shipped fast against real constraints. The portfolio doesn’t try to hide them.
What readers can take away
For new AI engineers building portfolios:
The AIfolio pillars name what to build. MRE names how to build it. Both matter, and most portfolios over-invest in the first and under-invest in the second. A demo that hits all four AIfolio pillars but has no harness around any of them is weaker than three pillars built with real harness engineering.
Pick one project and ship the harness. The minimum viable harness has three pieces: a fallback path on the layer most likely to fail, a quality gate that decides which path runs, and a way to audit which path actually ran (logs, return tuples, method tags). The cost is small. The signal is large.
Context engineering doesn’t require an H200. T5-base on a Kaggle GPU works. The signal isn’t the compute — it’s that you can defend a dataset choice, an eval metric, and a hyperparameter. Without that, your context layer is indistinguishable from the median.
Show the trade-offs. A README that says “this maxes out at one user, here’s why, here’s what would change for multi-tenant” reads as more senior than a README that claims SaaS-readiness it can’t back up. The InfoRetrieval v2 README’s frank acknowledgment that BLIP falls back to CPU on Apple Silicon “due to operator support limitations” is the right tone.
For mid-level engineers reviewing portfolios: the cheapest filter for MRE instincts is does the harness exist at all. Run through the candidate’s repos and ask — where does primary extraction live, what happens if it fails, and how would I know which path ran? The absence of an answer is the answer.
For hiring managers: a portfolio that ships hackathon-grade builds with the same architectural rigor as classroom flagship projects is a stronger signal than either taken alone. It says the patterns are reflexive, not assignment-driven. That’s what you’re hiring for.
The most underrated skill in early-career AI engineering isn’t model selection or prompt design. It’s the discipline to architect around the model the same way you’d architect around any other unreliable dependency. Vishnu’s portfolio is interesting because every project assumes the unreliability and designs for it from line one — context engineering on the input side, harness engineering on the output side, with the AIfolio pillars showing up as the natural shape rather than the assignment. If you’re hiring, look for this. If you’re building, copy it.