

Anthropic Just Proved That Agentic AI Needs Governance Harnesses — Not Just Better Models

I attended an event this week in Boston, hosted by Pillar, featuring Robert Brennan (CEO, OpenHands) and Nick Arcolano (Head of Research, Jellyfish), exploring how autonomous AI agents are redefining software development. The conversation kept circling back to the same unresolved question: once agents can write, review, and ship code autonomously — who governs what they are allowed to do?
That same week, Anthropic published a major engineering post on harness design for long-running agents. The timing made the connection impossible to ignore.
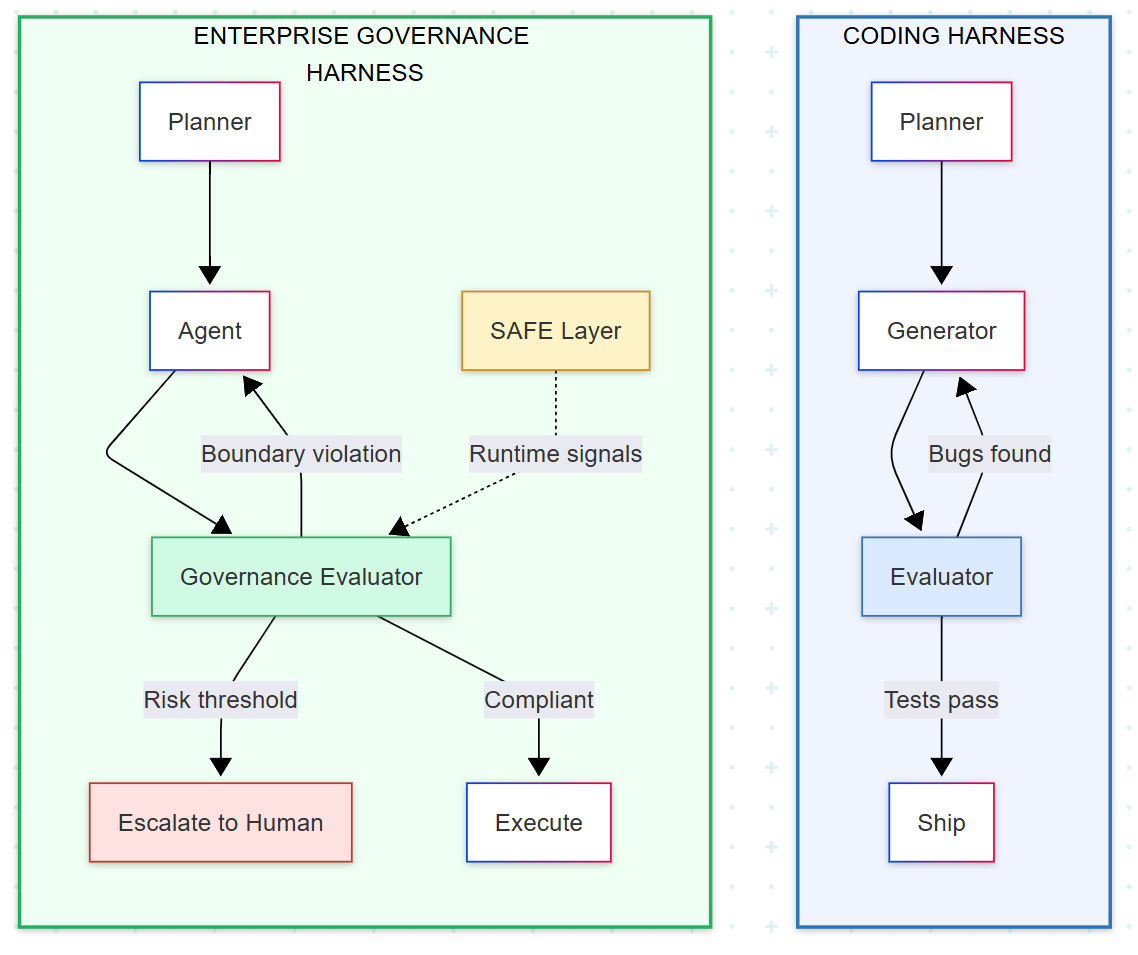
Anthropic’s post — Harness Design for Long-Running Application Development — describes a three-agent architecture: a Planner that expands a short prompt into a full product spec, a Generator that builds in structured sprints, and an Evaluator that interacts with the running application like a human QA engineer — clicking through features, testing endpoints, probing database states.
The Generator and Evaluator operate in a GAN-inspired adversarial loop. The Generator builds. The Evaluator breaks. The Generator fixes. Repeat until the Evaluator runs out of things to break.
This is a meaningful advance. But the conversations I had at the event reinforced something I keep seeing across enterprise AI deployments: Anthropic’s harness solves for correctness. It does not solve for authority, compliance, or operational risk.
Multiple engineering leaders I spoke with — from teams building agents, deploying agents, and measuring agent effectiveness — raised the same concern: the governance layer is the missing piece. The models are getting capable enough. The question is whether organizations can trust what the agents decide to do when humans are not watching.
The Gap Between Coding Agents and Enterprise Agents
A coding agent that goes off the rails produces bad code. A test fails. The evaluator sends it back. The cost of failure is a wasted compute cycle.
An enterprise agent that goes off the rails in a banking workflow might approve an unauthorized transaction. In a clinical triage system, it might recommend watchful waiting when a patient describes symptoms of anaphylaxis. In a government procurement system, it might commit funds beyond its authorization limit.
In these environments, the question is not just “did the agent produce the right output?” — it is “did the agent stay within its authorized role, ground its decisions in verified evidence, maintain integrity across a multi-step workflow, and stop when it should have stopped?”
Anthropic’s harness evaluates the product. Enterprise governance must evaluate the process.
Four Principles Missing from Current Harness Design
I am working with Paulo on developing a framework called SAFE — Scope, Anchored Decisions, Flow Integrity, and Escalation — that addresses this gap. It is designed for agentic systems where evaluation must act as a runtime control signal rather than a retrospective quality score.
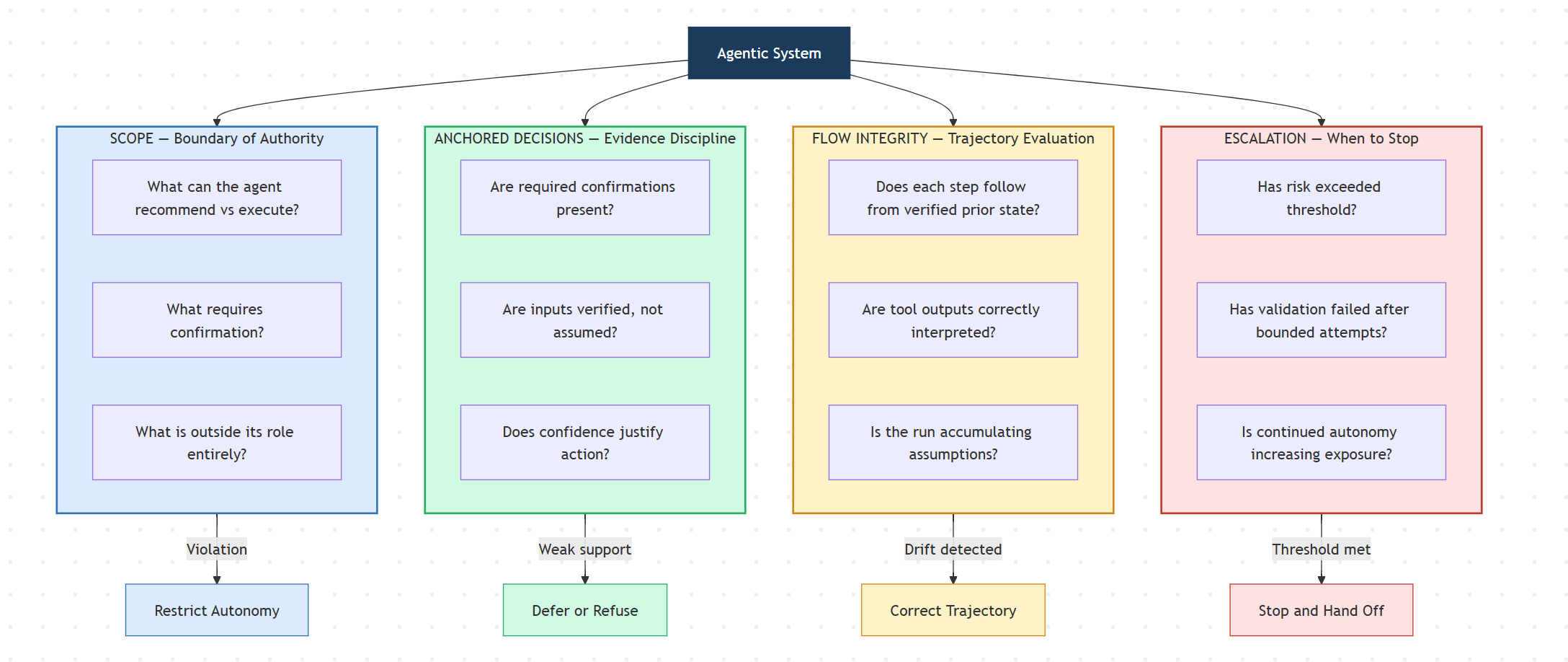
Scope defines the boundary of authority. In Anthropic’s harness, the Generator can do anything the codebase allows. In an enterprise harness, the agent needs an operational contract: what it can recommend versus execute, what actions require confirmation, and what falls entirely outside its role. Scope failures are rarely wrong answers — they are agents quietly expanding their authority because nothing stopped them.
Anchored Decisions governs behavior under uncertainty. Anthropic’s Evaluator checks whether features work. An enterprise evaluator must check whether decisions are supported — whether the agent had the verified inputs, confirmations, and evidence required before acting. A banking agent should not schedule a transfer against a pending deposit. A triage agent should not recommend home care when it lacks the clinical signals to rule out an emergency. As confidence decreases, autonomy must narrow.
Flow Integrity treats the entire trajectory as the object of evaluation. Anthropic’s progress file tracks what was built. In enterprise systems, you also need to track what was decided and why — whether each step followed from verified prior state, whether tool outputs were correctly interpreted, and whether the agent avoided the kind of assumption accumulation that compounds into operational risk across a multi-step run.
Escalation defines when the agent must stop. Anthropic’s harness loops until the Evaluator is satisfied. But in high-stakes domains, there are situations where the correct action is not to try again — it is to stop entirely and hand off. When a fraud detection agent cannot verify a user’s identity after bounded attempts, continued autonomous operation increases exposure. Escalation is not a failure mode. It is a control mechanism.
What This Means for Enterprise Teams
Anthropic’s finding that harness design matters more than model capability is validated by production experience. We have seen this across AI deployments across different industries: the governance layer around the agent determines operational safety far more than the model’s raw intelligence.
The practical implication for enterprise engineering teams adopting agentic AI:
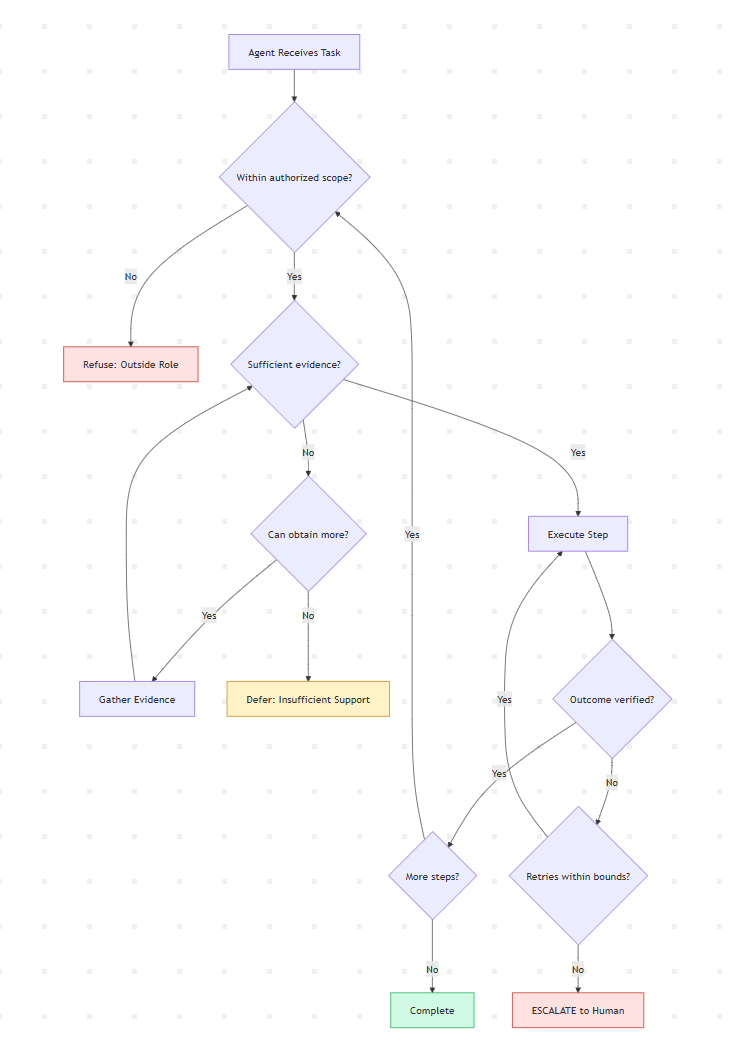
Your harness needs a governance evaluator, not just a quality evaluator. Anthropic’s Evaluator asks “does it work?” — enterprise systems also need an evaluator asking “should it have done this?” These are structurally different questions requiring different signals: authorization checks, evidence sufficiency thresholds, compliance rule validation, and explicit escalation triggers.
Context compaction destroys governance state. Anthropic notes that automatic compaction handles context growth. But compaction is lossy. Audit trails, compliance decisions, escalation history, and authorization state are exactly the kind of information that compaction may discard but governance requires. Enterprise harnesses need persistent governance memory that survives compaction — structured state that lives outside the context window.
Evaluation-as-control, not evaluation-as-scorecard. The most important shift in Anthropic’s work is treating the evaluator as an active participant in the build loop, not a post-hoc reviewer. The same principle applies to governance: evaluation signals should shape agent behavior in real-time, determining whether the agent proceeds, slows down, shifts to a safer mode, or stops.
The Frontier Is Governance, Not Generation
The conversations at the Pillar event and Anthropic’s engineering post point to the same conclusion from different angles. The people building agents (OpenHands), measuring their impact (Jellyfish), and designing their architectures (Anthropic) are all converging on a shared realization: model capability is no longer the bottleneck. Governance is.
Better models will keep arriving. The governance layer is what makes them safe to deploy.