

Auctor’s Bet: Traceability Is the Architecture, Not a Feature
Enterprise software only creates value when it’s actually deployed, and deployment is overwhelmingly a labor problem, not a software problem.

TL;DR - Auctor emerged from stealth in April 2026 with $20M led by Sequoia Capital to build an “AI-native system of action” for the messy, ~$500B/yr labor market of enterprise software implementation — the work that actually gets Salesforce, SAP, ServiceNow, or Workday running in a customer’s environment. Reading their public material with an architect’s eye, the interesting choice isn’t the agent loop or the LLM tuning. It’s the bet that artifact lineage is the load-bearing primitive: every user story, SoW, design doc, and Jira ticket is anchored in a graph that walks back to the discovery call that originated it. Frontier models are commodity; the project-scoped artifact graph compounds. If you’re building agentic systems for any domain where decisions accumulate across stakeholders over months — legal, healthcare RCM, B2B sales, regulated change management — study this pattern before you architect your context layer.
A real problem, sized correctly
Enterprise software only creates value when it’s actually deployed, and deployment is overwhelmingly a labor problem, not a software problem. Sequoia’s Julien Bek frames the ratio crisply: every dollar of enterprise software pulls roughly six dollars of services behind it. Across the top ten ecosystems — ServiceNow, Salesforce, SAP, AWS, and the rest — that adds up to about nine million implementation consultants and more than half a trillion dollars in annual labor spend, growing at a double-digit pace.
The work itself is brutal. A single deployment can span hundreds of requirements, dozens of stakeholders, and months of negotiation between what a business says it needs and what the platform can actually do. BCG’s 2024 study of more than 1,000 large-scale tech programs found that more than two-thirds miss their time, budget, or scope targets. Auctor cites their own statistics in the same vein: 50% of projects miss deadlines, and 1 in 6 exceeds budget by more than 200% — vendor-cited numbers, but directionally consistent with independent research. The interesting question isn’t whether implementation is broken. It’s whether the brokenness is structural — and if so, where the structural fix actually lives.
The architecture
Auctor’s framing is that implementation work is a context coordination problem, not a productivity problem. In a Q&A with Tercera, CEO Will Sun draws a distinction between three categories of enterprise software:
System of record — the platform that holds data (CRMs, ERPs).
System of work — the platform where work happens (Jira, Confluence, Asana).
System of action — a platform that acts on the data, not just stores or displays it, while preserving the traceability and governance enterprise buyers require.
That last category is where Auctor positions itself. It’s a marketing term, but the technical substance behind it is real: rather than being a chatbot that surfaces documents from your existing systems, the system itself is the substrate where decisions accumulate, artifacts are generated, and downstream tools get synced. The company describes the loop in three layers — Capture, Contextualize, Create — which read like marketing copy until you realize each layer corresponds to a non-trivial engineering surface.
Here is what the artifact graph actually looks like inside an engagement, based on what Auctor has described publicly:
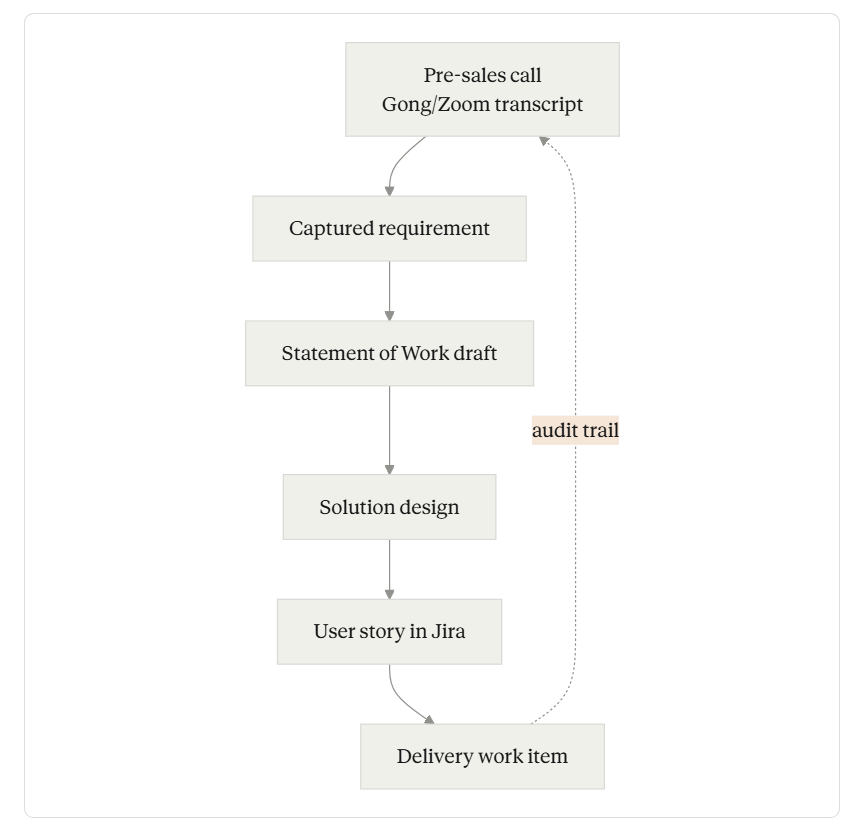
Artifact graph
The dotted line back to (A) is the actual product. The forward arrows are table stakes — anything with a decent prompt and a Confluence connector can generate a SoW from a meeting transcript today. The dotted line is where the engineering discipline lives.
Layer 1: Capture
The capture layer is the ingest plane. Auctor lists integrations with Google Meet, Microsoft Teams, Zoom, Gong, Outlook, Google Calendar, Slack, Confluence, Google Drive, OneDrive/SharePoint, Salesforce, HubSpot, Jira, Linear, Azure DevOps, Rally, and Certinia. Reading this as a list of features misses the point. Reading it as a topology of where implementation context lives is closer to right.
The non-obvious move here is that real-time meeting transcription is treated as a first-class source, not a bolt-on. Auctor’s own materials describe agents that join discovery and refinement calls, transcribe live, and pull context from past projects to steer the conversation. The Valiantys case study describes this concretely: instead of consultants taking manual notes during fifteen-stakeholder discovery sessions and consolidating afterward, requirements, action items, and meeting summaries are produced as the discussion unfolds.
That sounds modest until you think about what a “captured requirement” has to mean to be useful downstream. It has to:
be timestamped and attributed to the speaker who voiced it
be tagged with the stakeholder role that gave it weight (PMO, architect, exec)
be linked to the meeting and the parent engagement
be deduplicated against earlier captures of the same intent
carry enough structure to be queryable later by an agent generating a SoW
This is the unglamorous schema work that turns “transcript + LLM” into something a delivery team can actually trust. Most teams underestimate how much of this is bespoke and how little of it is solved by a vector store.
Layer 2: Contextualize
The contextualize layer is where Auctor’s architectural bet shows up most clearly. In Will Sun’s own words, the very first capability he and his cofounders prototyped — the one that drew SI leaders in — was traceability. Not generation. Traceability.
The mental model he describes: a user story created months into a project should be walkable back to the original requirement, the SoW that scoped it, and the pre-sales conversation where the stakeholder first voiced the need. That walk has to survive consultant turnover, mid-project pod swaps, and the natural decay of “tribal knowledge” that erodes every long engagement.
There are a few engineering implications worth pulling out:
The graph is multi-modal. A node in this graph can be a transcript span, a section of a Word doc, a CRM field, a Jira ticket, a Confluence page, or a Slack message. Edges aren’t just “is-related-to” — they need to encode causal relationships (this requirement caused this user story to exist) and temporal ones (this requirement was superseded by that decision in last Tuesday’s call). Few off-the-shelf graph databases handle this cleanly without significant modeling work above them.
Project-scoped retrieval beats global retrieval. The Crossfuze case study describes Auctor’s account- and project-level repositories explicitly: queries are bounded to a defined scope rather than searching across everything the firm has ever ingested. This is a deliberate inversion of the “one big RAG corpus” pattern. For implementation work, it’s almost certainly correct — the consultant answering a Q in a SoW review wants context from this engagement, not the closest semantic match across 200 historical projects. Cross-project learning becomes a separate, opt-in surface — templates, playbooks, codified house standards — rather than something contaminating live retrieval.
Audit trail is the API, not a sidecar. Implementation buyers — especially in financial services, government, and healthcare — won’t trust an autonomous system unless they can ask, of any output, “what did this come from?” Bolting an audit log onto a generation pipeline after the fact rarely produces a satisfying answer. Designing the lineage as the primary data structure, with generation as a derived operation, is what makes the audit trail credible. This is the same discipline that production data engineering applies to lineage in dbt or feature stores; it’s still rare in agent systems.
Layer 3: Create
The create layer is where Auctor’s outputs land. Their own product page lists the artifact types: rough orders of magnitude, resource plans, statements of work, scopes, solution designs, process flows, user stories, and presentation decks. Each of these is a distinct generation problem with its own template, its own validation rules, and its own downstream sync target.
The interesting design decision is that generation is bounded by the project graph, not by raw model capability. A SoW draft isn’t generated from “what the model knows about SoWs”; it’s generated from the requirements, decisions, and constraints already in this engagement’s graph, with house-style templates from the SI’s own playbook layered on top. Crossfuze describes this as “first-pass content creation within clearly defined project contexts,” explicitly using Auctor for drafts that then go through their normal brand and review process.
That’s the right framing for any high-stakes generation task: the model produces a defensible draft, the human still owns approval, and the graph guarantees that nothing in the draft is stranded — every claim, number, and design decision can be traced to a source already in the system. It’s also a much better fit for fixed-fee delivery economics than “AI assistant pinging the consultant for help” — because the unit of work is the artifact, not the keystroke.
The harness, not the model
Sun is explicit on the model question: Auctor builds on frontier foundation models and tunes the system around how those models evolve, working with hundreds of consultants daily to know what works and what doesn’t. They are not building a foundation model. They are not even, as far as the public material reveals, fine-tuning one in a meaningful way. The bet is that the model is the commodity layer and the SI-specific harness — the schemas, the project-scoped retrieval, the artifact graph, the integrations, the templates, the governance — is where compounding value lives.
This is a defensible bet, and not just for Auctor. The same reasoning applies to most vertical agent companies: every six weeks the underlying model gets cheaper and stronger, and any architectural choice that depends on a specific model’s quirks decays with it. The architecture that compounds is the one that gets more useful with better models, because the harness was the durable artifact all along. The frontier labs themselves have been making versions of this argument in their own engineering writeups: the loop, the tools, the context curation are where engineering effort earns its keep, not the model behavior of any given week.
The corollary is uncomfortable for some founders: if your moat is mostly model behavior, you don’t have a moat. You have a temporary advantage on a clock you don’t control. Auctor’s choice to plant their flag on the graph instead of the model is, on its face, the more durable bet.
Governance is engineering, too
Auctor’s security page is more interesting than the average vendor compliance recitation, mostly for one detail: zero data retention with upstream AI providers, meaning customer inputs aren’t stored or logged by the underlying model providers and aren’t used for model training. For services firms whose customers include financial institutions, government agencies, and Fortune 500s, this is a precondition for sale, not a nice-to-have. The rest is what you’d expect from a startup chasing enterprise contracts: AWS infrastructure, AES-256 at rest, TLS 1.3 in transit, SSO/SCIM via Okta/Azure AD/Google, SOC 2 Type II, ISO 27001, and regional data residency.
The governance story matters because it’s the gating constraint on the whole architectural play. An audit trail is only as trustworthy as the platform’s ability to demonstrate its handling controls to a procurement team. The system-of-action framing falls apart if the action can’t be retrospectively justified to a regulator or an internal audit function. Sun makes this point explicitly in the Tercera Q&A: action without accountability fails.
What’s unproven
Worth being honest about what we don’t know from the public material:
The 80% efficiency claim is vendor-cited. Auctor reports “up to 80% efficiency gains across phases like discovery and design.” The number comes from the company and the customers it has chosen to highlight; there’s no independent benchmark, and “efficiency gain” is doing a lot of definitional work. Take it as directional, not as a measured productivity figure.
The architectural details are not public. Everything above is reverse-engineered from product copy, founder interviews, case studies, and integration lists. We don’t have a public technical writeup describing the schema, the graph implementation, the retrieval strategy, or the agent loop. There may be — and probably are — significant differences between the architecture as described and the architecture as built.
Implementation work resists templating. The harder question for any “system of action” is whether the work it’s automating is genuinely templatable at scale. SoWs and user stories sit on a spectrum: the boilerplate scaffolding is highly templatable, the load-bearing scope language often isn’t. Auctor’s own framing — first drafts, with human approval — implicitly concedes this. The interesting test will be how much of the high-judgment work survives at the human layer five years from now. Sequoia’s framing of “intelligence vs. judgement” is the right map here.
Category competition is coming. “Agentic operating system for SI work” is a defensible position today partly because nobody else is positioned exactly there. That window won’t stay open. Several adjacent categories — meeting intelligence vendors, services automation tools, project management platforms — are within a roadmap or two of overlapping capability. The artifact graph is a real moat if it stays project-scoped and integration-rich, but it’s the kind of moat that needs to keep deepening.
What builders should learn
Three patterns are worth pulling into your own architecture, regardless of vertical:
Make lineage the primary data structure. If you’re building an agent system in any domain where decisions need to be defensible — legal, finance, healthcare, regulated B2B — design the artifact graph first and the generation pipeline second. Walking from any output back to the source it depends on should be a single graph traversal, not a forensic exercise. Most teams do this backward: they build the loop, ship a feature, then bolt on observability when a customer asks why the model said what it said.
Scope retrieval to the engagement, not the corpus. Cross-project learning is a different surface from in-project recall. Conflating them produces retrieval that’s almost-right in a hundred subtle ways and consistently wrong on questions like “what did this customer decide last Tuesday?” Project- or account-scoped repositories solve a real problem cheaply.
Bet on the harness. If the part of your system that depends on the current state of frontier models is more than a thin layer, your roadmap is exposed to the next model release. The durable engineering — the schemas, the scoping, the integrations, the templates, the lineage — is what compounds while the model layer keeps shifting underneath.
These aren’t novel patterns in isolation. The novel thing is treating them as load-bearing rather than as polish. In a domain that has resisted automation for thirty years, that decision is the architecture.
Have you seen this pattern — lineage-first, harness-bet — in production agent systems outside the SI space? Reply and tell me what you’re building. I read every response.
Further reading
Auctor product overview — the integration topology and the three-layer framing in the company’s own words
Will Sun’s Q&A with Tercera — primary-source view on the system-of-action concept and the founding traceability bet
Julien Bek, “Services: The New Software” — the strategic frame Auctor was funded against; useful even if you’re not in services
Sequoia’s partnership announcement — Bek’s investment thesis on Auctor specifically
BCG, “Most Large-Scale Tech Programs Fail” — the independent base rate for project failure that the whole category is sized against