

Builder Spotlight - Armaan Agrawal ships like a forward-deployed engineer already
Seven production systems, one repeatable pattern, and the real-world skills most new grads don’t show up with.

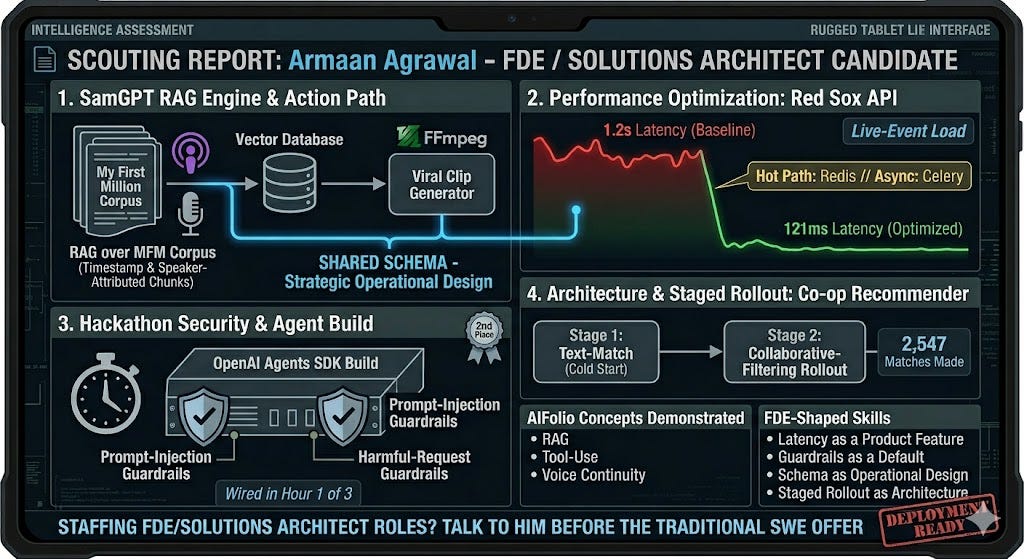
TL;DR. Armaan Agrawal (CS @ Northeastern, class of 2026) has a new-grad portfolio that reads like a scout report for forward-deployed engineering. SamGPT is a RAG engine over the My First Million corpus with timestamp and speaker-attributed chunks that bridge into a Viral Clip Generator via FFmpeg — the retrieval and action paths share a schema on purpose, which is the move a Solutions Architect makes. He wired prompt-injection and harmful-request guardrails into an OpenAI Agents SDK build in hour one of three at a hackathon and placed 2nd. His co-op recommender solved cold-start with a staged text-match → collaborative-filtering rollout that will be deployed to 2500 students. He’s demonstrating the concepts the AIfolio framework calls for — RAG, tool-use, voice continuity — but what makes the portfolio FDE-shaped is the real-world skills around those concepts: latency as a product feature, guardrails as a default, schema as operational design, staged rollout as architecture. If you’re staffing an FDE or Solutions Architect role, talk to him before he takes a traditional SWE offer.
The habit, stated
Most new-grad portfolios are a pile of frameworks. Armaan’s is a pile of systems shipped to specific users whose operational reality he understood. That sounds soft until you look at the architectural choices — they’re the ones you make when the user’s failure mode, not the rubric, is what you’re optimizing against.
AIfolio Projects
Forward-deployed engineering and solutions architecture are the same job at different scales: drop into a domain you didn’t grow up in, compose a working system out of heterogeneous pieces, land it with safety and observability already in it, and iterate on the signal instead of the stack. Most new grads learn this over two years of production pain. Armaan has already shipped it seven times.
The AIfolio framework names the concepts an AI-engineering portfolio should demonstrate — RAG pipelines, tool-use architecture, agent design, memory and voice continuity. Armaan hits those concepts. What’s more interesting is what he does around them: the habits that make the concepts production-viable instead of demo-viable. That’s what this piece walks through.
RAG with schema foresight (SamGPT + Viral Clip Generator)
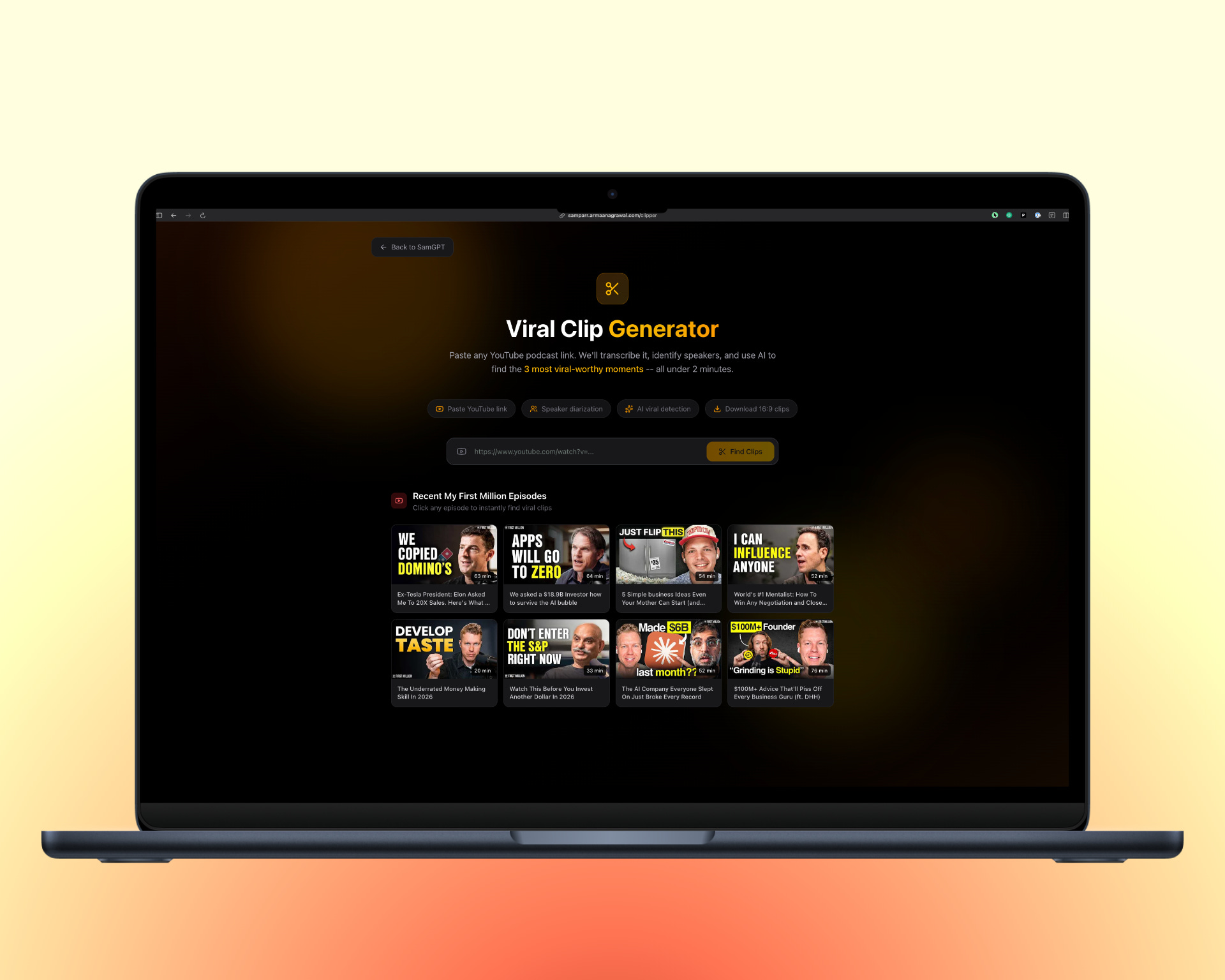
Viral clip generator
Stack: Whisper / ASR, speaker diarization, embeddings, vector search, FFmpeg, Next.js.
SamGPT is a RAG system over the My First Million podcast corpus: semantic search, query expansion, suggested prompts, YouTube deep links to the exact timestamp. The Viral Clip Generator is the adjacent tool: paste a YouTube URL, get the top 3 sub-2-minute cuts auto-extracted as 16:9 exports.
What makes this architecturally non-obvious isn’t the RAG itself. It’s the bridge between the two services.
The data model carries timestamped, speaker-attributed chunks all the way through retrieval. A user who finds a quote in SamGPT can jump to the video at the exact second, or pass the chunk to FFmpeg and get a shippable 16:9 cut. Retrieval and generation aren’t separate products wearing the same skin — they share metadata, and the shared metadata is the feature.
This is the Solutions Architect move. It would have been easier to build two independent tools and call it a suite. Instead he built one pipeline with two exits, and the marginal cost of the second exit was near zero because he designed the chunking schema for it upfront. Most AI engineers bolt that on later and lose half the data.
The portable real-world skill: your chunking schema is a product decision, not an infrastructure decision. Armaan’s schema already had timestamps and speaker attribution because he knew a second surface (clip extraction) would need them. That’s designing the system to be legible to the next tool you’ll build against it — the skill that separates an AI engineer from a solutions architect.
Tool-use architecture without MCP (Content Engine)
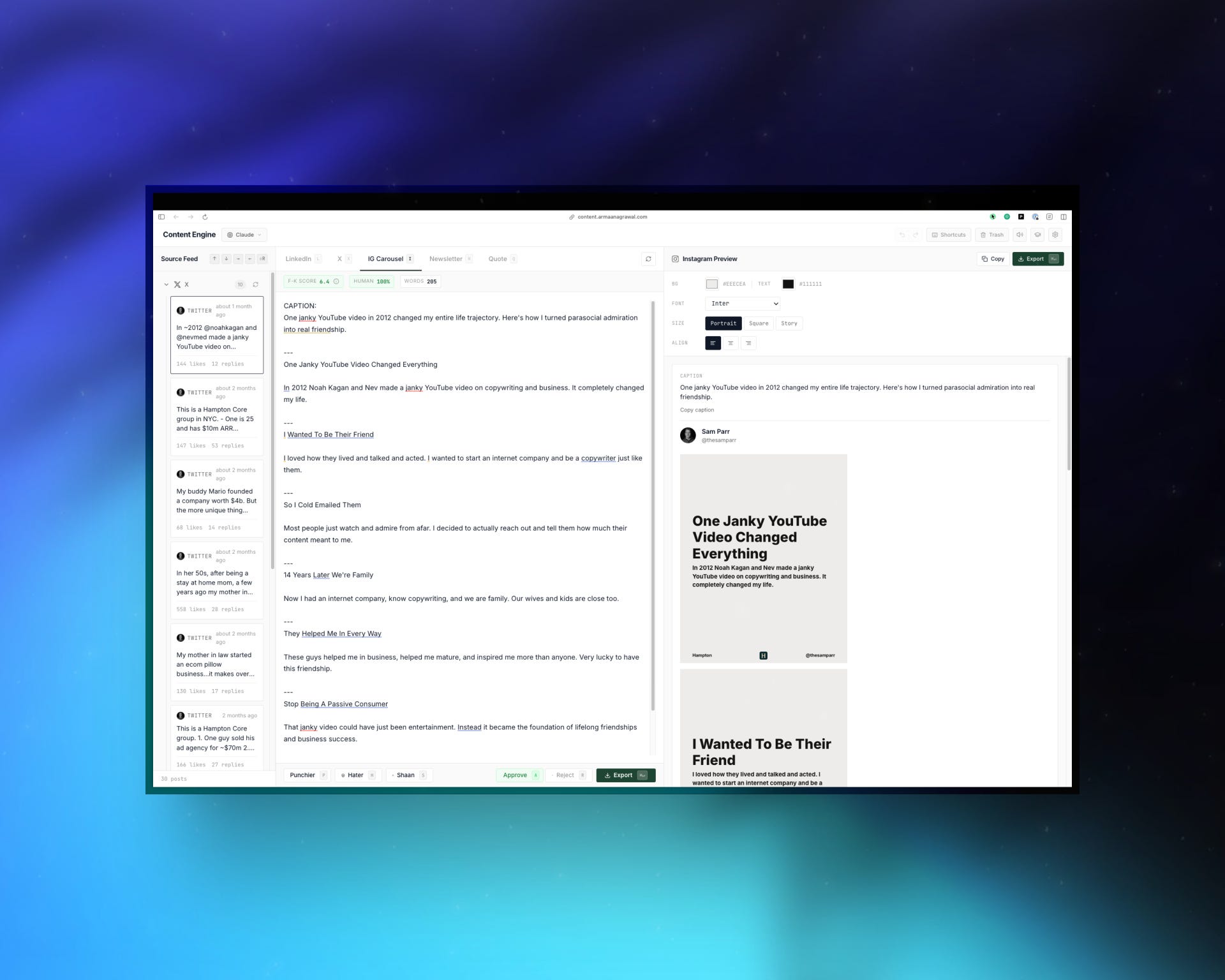
Content Engine
Stack: Next.js, content pipelines, carousel export, AI rewrite with tone presets, personalized to voice and style data.
One source tweet, four output formats: LinkedIn long-form, IG carousel, newsletter, quote card. Three-pane UI: source feed on the left, tabbed editor in the middle (one tab per target format), live preview on the right.
Two choices worth calling out:
Format-specific editor tabs instead of a single “transform” button. Each target format has its own constraints, and he exposes them as first-class surfaces. This is the difference between treating output formats as parameters to one generator versus treating them as distinct tools that share an upstream source. The second is what a Solutions Architect picks when the user has real editorial control needs. It’s also the tool-use design pattern MCP formalizes — you don’t need MCP to pick it, you need the instinct that separates tool boundaries along user-decision boundaries.
Voice personalization. Most “AI rewrite” tools regress your writing toward a generic model voice. Armaan’s design carries personal-voice signal into every tab, so the four generated variants don’t all sound vaguely like a LinkedIn guru. The failure mode of cross-platform content tools is well-known: you write once, four generated variants all need a hand-rewrite, the tool saves you zero minutes. Closing that gap is a real-world skill the canonical AIfolio memory pillar hints at but most projects miss.
Latency as a product feature (Red Sox)
Stack: Django, Vue.js, Redis, Celery, PostgreSQL, Okta SSO, Docker. Live at Fenway Park, Jan–Sep 2024.
Live batting-lineup API for journalists during games. Previous method: a handwritten whiteboard. If the API went down mid-game, press couldn’t report the lineup before first pitch.
The number most new grads would chase is features. Armaan chased tail latency: 1.2s → 121ms, a ~90% cut, via Redis on the hot path and Celery for everything off-path. Two architectural choices inside that:
Cache on the read path, not everywhere. Redis in front of lineup reads means the request journalists actually make — “what’s the roster right now” — never waits on downstream services. Cache invalidation is keyed to lineup changes, so staleness lives in a narrow, owned window.
Celery for everything the user isn’t waiting on. Notifications, logging, eventual-consistency writes — off the request thread. The hot path becomes trivial to reason about because it does one thing.
None of this is AI engineering. It matters for an AI portfolio anyway, because the Retrofit Tax is what teams pay when they try to add observability, latency discipline, or governance to a system that was shipped without them. Armaan doesn’t retrofit. Production-shaped defaults go in the original design, where the cost of adding them is close to zero. That’s the posture that keeps his work from accruing tax as he scales it.
Guardrails in hour one, not hour forty (AgentOps hackathon)
Guardrails Setup
Stack: OpenAI Agents SDK. 3 hours. 2nd place.
Most hackathon demos ship a working prototype and skip safety entirely — the rubric doesn’t require it, and guardrails feel like production overhead. Armaan shipped input guardrails from line one, with prompt-injection blocks and harmful-request blocks both live in the demo.
Reading this as a minor detail misses what it signals. The OpenAI Agents SDK exposes guardrail primitives cheaply; almost nobody uses them on a hackathon timeline. Using them anyway is the same instinct as caching the Red Sox hot path: production-shaped defaults on demo-shaped timelines.
This is also where the behavioral-reliability work most AI engineers learn after their first incident shows up pre-incident. Validation gates, input filters, behavioral guardrails before a model’s output reaches the user — these are not optional for production systems, but they’re almost always added reactively. Reaching for them at hour one of a three-hour build is the instinct, and it’s not teachable under deadline.
For an FDE hiring manager, this is the cheapest-to-evaluate signal in the portfolio.
Schema as operational product design (Feedshare)

Feedshare
Stack: SwiftUI, Firebase, iOS. 100+ campus users.
The framing — “campus free food shouldn’t die in a group chat” — constrains the whole system. The schema isn’t “post + comments.” It’s:
Photo-first feed (you don’t walk across campus on a text description)
Map pins (location is a first-class field, not a comment)
Multi-photo upload, up to 5 (proof, not hype)
Room + headcount fields (so you know whether it’s worth the walk before you leave)
Every field on the post form corresponds to a decision the user makes: is this real, where is it, is it still there, is it worth the walk. The schema is the product.
This distinguishes FDE work from generic backend work. The post schema isn’t generic — it encodes the decision-making workflow of the specific user on the specific campus. Firebase gets him there fast because the real work isn’t the backend; it’s figuring out what data the user’s decision actually requires and refusing to collect anything else. Shipping to 100+ students on a campus with real food-waste pressure means the hypothesis has already been validated in the field.
Cold-start as staged architecture, not a hack (co-op recommender)
While at NExT Consulting, he built a co-op recommender for Northeastern students — planning to be used by 2,500 in intro university classes. New students have no history, the classical cold-start trap that kills most recommendation systems before they ship.
His rollout: text matching first (profile-to-role matching for the cold-start population), then shift to collaborative filtering once interaction data accumulates. “Good matches from day one, better over time.”
This is the staged-architecture move a Solutions Architect picks. You don’t wait for data to deploy the system, and you don’t stay on cold-start forever. You design the data pipeline so the transition is a config change, not a rewrite. For a new grad to pick the staged approach on a real user-impact system is unusual — most new engineers either over-engineer the eventual collaborative-filter stack and ship late, or ship the text-match version with no path off it and accumulate the tax later.
Why this maps to FDE / Solutions Architect work
Forward-deployed engineering is:
Understand a domain you didn’t grow up in faster than the customer thinks is possible.
Compose a working system from heterogeneous pieces (their stack + yours).
Land it with safety, observability, and latency budgets already wired in.
Iterate on the signal, not the stack.
Armaan has already run this pattern across five unrelated domains: chemical plant telemetry, a baseball press box, campus food logistics, long-form podcast content, and an AI agent under safety scrutiny. The domains are portable. The habit is portable.
The concepts an AI-engineering portfolio needs to demonstrate — RAG, tool-use, voice continuity, agent design — are necessary. The real-world skills that make those concepts production-viable are what’s rare: schema foresight, tail-latency discipline, pre-incident guardrails, schema-as-product thinking, staged rollout. Armaan’s portfolio has both layers. That’s the thing most new-grad hires don’t come with.
Solutions Architect work has a narrower shape — more “compose a durable reference architecture for customers” than “ship a one-off” — but the underlying disposition is identical. Pick the production-shaped default, not the demo-shaped one. Design the data model for the surface you’ll build next. Treat latency and guardrails as product features. Refuse to accrue Retrofit Tax.
How to reach him
Portfolio: armaanagrawal.com — worth reading in order, it’s structured as seven chapters
GitHub: github.com/airman416 — SamParrBot (SamGPT) and Content-Engine are the deepest reads
LinkedIn: linkedin.com/in/agr1
Target roles: Forward Deployed Engineer, Solutions Architect
For readers building their own AIfolio: the pattern that repeats across his work is cheaper to adopt than you’d think. Ship guardrails in hour one, not hour forty. Design your RAG chunking schema around the second surface you’ll build, not the first. Stage your cold-start into a config change instead of a rewrite. Cache the read path before you need to. None of that is senior-only work. It’s just the production-shaped default most engineers don’t pick until the first incident teaches them to — and the reason their portfolios end up carrying Retrofit Tax instead of compounding.
The "guardrails in hour one" observation is the sharpest signal here. Most engineers treat safety as a post-ship concern. Reaching for input validation on a 3-hour hackathon timeline isn't discipline it's default wiring. That's the thing you can't fake on a deadline.
The chunking schema point resonates too designing retrieval metadata for the second surface before the first one ships is exactly the kind of decision that looks obvious in hindsight and gets retrofitted in most production RAG systems.
I write about production AI systems and distributed backends same territory. Worth a subscribe here too.