

Claude Opus 4.7: The Production Engineer’s Breakdown
Four breaking changes, seven behavior shifts, two new control surfaces, and a quietly throttled cyber capability. What actually changed inside Anthropic’s new flagship — and what that means for anyone

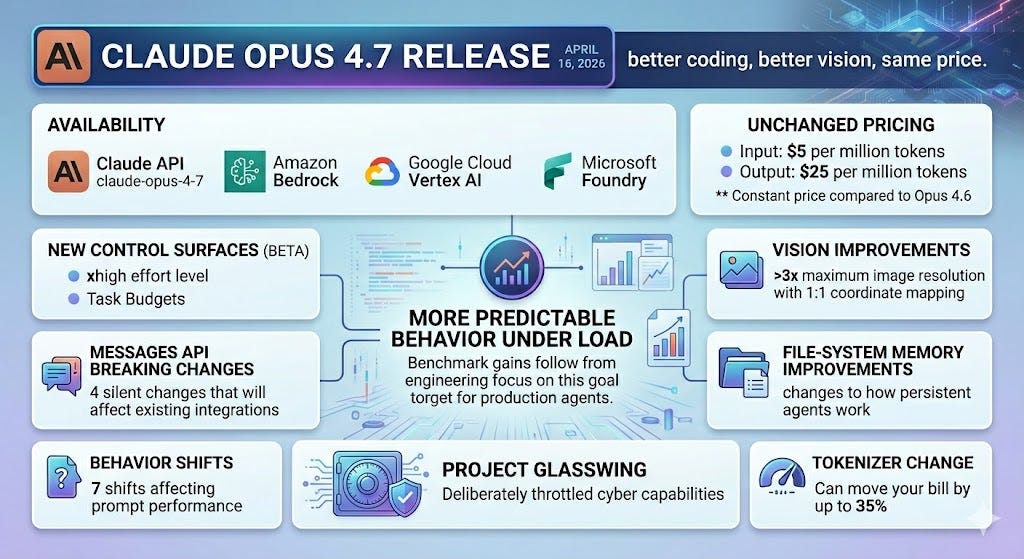
TL;DR - Anthropic released Claude Opus 4.7 on April 16, 2026, available via the Claude API as claude-opus-4-7, plus Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. Pricing is unchanged from Opus 4.6 at $5 per million input tokens and $25 per million output tokens. The marketing line is “better coding, better vision, same price.” That is true and it understates what shipped. Opus 4.7 introduces two new control surfaces (the xhigh effort level and task budgets in beta), four breaking changes to the Messages API that will silently affect existing integrations, seven behavior shifts that will affect how your prompts perform, more than 3x the maximum image resolution with 1:1 coordinate mapping, file-system memory improvements that change how persistent agents work, deliberately throttled cyber capabilities as part of Project Glasswing, and a tokenizer change that can move your bill by up to 35%. If you run agents in production, this release is less about a smarter model and more about a model engineered to behave more predictably under load. The benchmark gains follow from the engineering, not the other way around.
What you actually get
Strip out the marketing and the technical envelope is straightforward. According to Anthropic’s developer documentation, Opus 4.7 supports the 1M token context window, 128k max output tokens, adaptive thinking, and the same set of tools and platform features as Claude Opus 4.6. The 1M context window comes at standard API pricing with no long-context premium — a meaningful change for anyone who has been chunking aggressively to stay under the previous tier boundaries.
Opus 4.7
The model is generally available across Claude products and the API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. For business users, Opus 4.7 is available on Claude for Pro, Max, Team, and Enterprise users. Per Anthropic’s product page, pricing for Opus 4.7 starts at $5 per million input tokens and $25 per million output tokens, with up to 90% cost savings via prompt caching and 50% via batch processing.
The architectural lift over Opus 4.6 is concentrated in three places: a retrained tokenizer, a redesigned thinking-effort surface, and significantly improved high-resolution vision. Everything else in the release — the new tools, the breaking changes, the behavior shifts — flows from those three.
Two new control surfaces
The most consequential additions for engineers building autonomous workflows are the new effort level and task budgets. They change what “tuning a Claude integration” actually means.
The xhigh effort level
The new xhigh level sits between high and max. Per the effort documentation, Anthropic recommends starting with xhigh for coding and agentic use cases, with high as the minimum for most intelligence-sensitive workloads. The API default is high. In Claude Code, xhigh is now the default for all plans and providers on Opus 4.7.
What changed beyond the new tier is how strictly the model respects effort. Per Anthropic’s migration guide, Opus 4.7 respects effort levels more strictly than Opus 4.6, especially at low and medium. At those lower levels, the model scopes its work to what was asked rather than going above and beyond. The practical implication is that a moderately complex task running at low effort will under-think rather than silently escalate. If you observe shallow reasoning on complex problems, raise effort to high or xhigh rather than prompting around it.
Two production-relevant data points worth knowing before you migrate. First, per a Hex testimonial in the launch post, low-effort Opus 4.7 is roughly equivalent to medium-effort Opus 4.6. Second, per Anthropic's launch post, on their internal agentic coding evaluation the net token usage across all effort levels improved versus Opus 4.6 — meaning the efficiency gains outweighed the tokenizer increase and the deeper thinking. Anthropic explicitly notes the evaluation runs autonomously from a single prompt and may not represent interactive coding patterns.
Task budgets (beta)
Task budgets are the more architecturally interesting new control surface, because they are the first time a Claude model is given visibility into its own remaining budget. Per the docs, a task budget gives Claude a rough estimate of how many tokens to target for a full agentic loop, including thinking, tool calls, tool results, and final output. The model sees a running countdown and uses it to prioritize work and finish the task gracefully as the budget is consumed.
The API surface is straightforward. Set the beta header task-budgets-2026-03-13 and add the following to your output config:
response = client.beta.messages.create(
model="claude-opus-4-7",
max_tokens=128000,
output_config={
"effort": "high",
"task_budget": {"type": "tokens", "total": 128000},
},
messages=[
{"role": "user", "content": "Review the codebase and propose a refactor plan."}
],
betas=["task-budgets-2026-03-13"],
)The minimum value for a task budget is 20k tokens. If the model is given a task budget that is too restrictive for a given task, it may complete the task less thoroughly or refuse to do it entirely. For open-ended agentic tasks where quality matters more than speed, Anthropic recommends not setting a task budget; reserve them for workloads where you need the model to scope its work to a token allowance.
What makes this design different from a hard cap is that the model is aware of it. A task budget is advisory — it is a suggestion the model is aware of, not a hard cap. This is distinct from max_tokens, which is a hard per-request ceiling that is not passed to the model at all. max_tokens is a guillotine — the model never sees it and gets cut off when it hits. task_budget is a clock — the model sees the countdown and adjusts behavior to land cleanly within the budget. For long-running agentic work where graceful degradation matters more than abrupt termination, this is a meaningfully better primitive.
Four breaking changes you might miss
These breaking changes apply to the Messages API only. If you use Claude Managed Agents, there are no breaking API changes for Claude Opus 4.7. The first two return 400 errors that flag the issue clearly. The third and fourth are silent — they surface as subtle behavior changes downstream if you skip the migration audit. All four are documented in the official What’s new in Claude Opus 4.7 reference.
Extended thinking budgets are removed. Setting thinking: {"type": "enabled", "budget_tokens": N} will return a 400 error. Adaptive thinking is the only thinking-on mode, and Anthropic reports their internal evaluations show it reliably outperforms extended thinking. The new pattern uses adaptive thinking with effort as the depth control:
# Before (Opus 4.6)
thinking = {"type": "enabled", "budget_tokens": 32000}
# After (Opus 4.7)
thinking = {"type": "adaptive"}
output_config = {"effort": "high"}There is also a subtler shift here. Adaptive thinking is off by default on Claude Opus 4.7. Requests with no thinking field run without thinking. Set thinking: {type: "adaptive"} explicitly to enable it.
Sampling parameters are removed. Setting temperature, top_p, or top_k to any non-default value will return a 400 error. The safest migration path is to omit these parameters entirely from requests and use prompting to guide the model’s behavior. The prior trick of setting temperature = 0 for “determinism” is also gone — per Anthropic’s own note, it never guaranteed identical outputs, and now it does not even run.
Thinking content is omitted by default. Thinking blocks still appear in the response stream, but their thinking field will be empty unless the caller explicitly opts in. This is a silent change — no error is raised — and response latency will be slightly improved. If your product streams reasoning to users, the new default will appear as a long pause before output begins. Set "display": "summarized" to restore visible progress during thinking.
Updated token counting. Claude Opus 4.7 uses a new tokenizer that contributes to its improved performance on a wide range of tasks. Per the docs, this new tokenizer may use roughly 1x to 1.35x as many tokens when processing text compared to previous models, varying by content, and /v1/messages/count_tokens will return a different number of tokens for Opus 4.7 than it did for Opus 4.6. The 1.0–1.35x range is wide enough that “your bill went up 5%” and “your bill went up 30%” are both plausible outcomes — measure on real traffic before extrapolating. Anthropic suggests updating your max_tokens parameters to give additional headroom, including for compaction triggers.
Seven behavior shifts that will change how your prompts perform
These are not breaking changes in the API contract sense, but they will silently affect the quality of your existing prompts. The official behavior change list reads almost like a release note for an operations-focused fork:
Instruction following is now literal, particularly at lower effort levels. The model will not silently generalize an instruction from one item to another, and will not infer requests you didn’t make. The most common failure mode in early migration coverage: bullet-list “suggestions” that earlier Claude models treated as optional hints are now treated as hard requirements.
Response length calibrates to perceived task complexity, rather than defaulting to a fixed verbosity. Short queries get short answers. Complex queries get longer ones. If you have prompt scaffolding that forced specific response lengths, expect different behavior.
Fewer tool calls by default. The model uses tools less often than Opus 4.6 and uses reasoning more. Raising effort increases tool usage; per the migration guide, high or xhigh effort settings show substantially more tool usage in agentic search and coding.
More direct, opinionated tone. Less validation-forward phrasing and fewer emoji than Claude Opus 4.6’s warmer style. Whether this is what your end users want depends entirely on your product surface.
More regular progress updates during long agentic traces. If you’ve added scaffolding to force interim status messages, try removing it.
Fewer subagents spawned by default. Steerable through prompting.
Real-time cybersecurity safeguards. Newly added in Claude Opus 4.7, requests that involve prohibited or high-risk topics may lead to refusals. Legitimate security teams can apply to the Cyber Verification Program for reduced restrictions.
The cumulative effect across all seven is a model that does more of what you tell it to do and less of what it inferred you wanted. For teams with mature prompt libraries built against Opus 4.6, this is a real audit obligation. For teams writing new integrations, it is a meaningful reduction in “magical” behavior that you cannot test for.
Vision: the genuinely large step function
The vision upgrade is the single largest capability jump in the release. Per the docs, maximum image resolution increased to 2576px / 3.75MP, up from the previous limit of 1568px / 1.15MP. That is more than 3x the pixel count.
Two technical details matter beyond the headline number. First, the model’s coordinates now map 1:1 with actual pixels, so there’s no scale-factor math required for any computer-use agent that needs to point at specific UI elements. Second, the upgrades extend beyond resolution: low-level perception (pointing, measuring, counting) and image localization (bounding-box detection) both improved.
The biggest reported lift comes from XBOW, building autonomous penetration testing. Per their testimonial in the launch post, visual acuity moved from 54.5% on Opus 4.6 to 98.5% on Opus 4.7. That is the kind of step function that obsoletes architectural workarounds. If your computer-use or document-analysis agent has ever included logic to chunk, crop, or downsample images to compensate for the previous resolution ceiling, that code is now technical debt. One tradeoff to plan for: higher-resolution images consume more tokens — downsample images before sending if the additional fidelity is unnecessary.
File-system memory improvements
Per the docs, Opus 4.7 is better at writing and using file-system-based memory. If an agent maintains a scratchpad, notes file, or structured memory store across turns, that agent should improve at jotting down notes to itself and leveraging its notes in future tasks.
For teams that have built persistent agents — the kind that work across multiple sessions on long-running projects — this is a quietly significant improvement. The agent that previously needed extensive context restoration at the start of each session can now do more of that work itself by writing better notes and using them more effectively. Anthropic’s client-side memory tool gives you a managed scratchpad if you do not want to roll your own.
The downstream effect is fewer tokens spent on context restoration and more on actual work. Multi-session agentic workflows that previously felt like they were starting from scratch each time should feel more continuous.
Training and the cyber capability story
The most editorially interesting decision in this release is what Anthropic deliberately did not improve. Per the launch post, during training Anthropic experimented with efforts to differentially reduce Opus 4.7’s cyber capabilities relative to Mythos Preview. The model also ships with safeguards that automatically detect and block requests that indicate prohibited or high-risk cybersecurity uses.
This is the first generally available model carrying the Project Glasswing safeguard stack — Anthropic’s approach to staging powerful model releases by testing new safeguards on less-capable models before broader rollout of Mythos-class capabilities. Per Vellum AI’s benchmark analysis, on CyberGym, Opus 4.7 scores 73.1%, effectively flat against Opus 4.6’s revised 73.8%, while Mythos Preview scores 83.1% on the same benchmark but remains restricted to vetted partners.
For production teams, two takeaways. First, if you have legitimate security workloads — vulnerability research, penetration testing, red-teaming — the Cyber Verification Program is the path to reduced restrictions. Apply early; the program is new and the enrollment cycle is unclear. Second, the safeguard-first deployment pattern is likely to repeat. Anthropic states that what they learn from real-world deployment of these safeguards will inform their goal of a broad release of Mythos-class models, which means the next Mythos-class model will likely not arrive without similar testing on a less capable model first.
What the alignment evals actually say
The safety profile is honest about being incomplete. Per the launch post, Anthropic’s alignment assessment concluded that the model is “largely well-aligned and trustworthy, though not fully ideal in its behavior.” Mythos Preview remains the better-aligned model by Anthropic’s own evaluations.
Specifics worth knowing if you operate Opus 4.7 in user-facing contexts:
Honesty and resistance to malicious prompt injection attacks are improvements on Opus 4.6. For agents that consume web content, customer documents, or third-party tool output, prompt injection resistance is the most active reliability threat surface, and the improvement is meaningful.
The model is modestly weaker on overly detailed harm-reduction advice for controlled substances.
Per reporting by The Decoder on the system card, Opus 4.7 still refuses to assist in 33% of simulated AI safety research tasks, a significant drop from 88% with Opus 4.6. Still imperfect, but a categorical shift.
The system card distinguishes between factual hallucinations (wrong claims about the world) and input hallucinations (the model acting as if it has access to a tool or attachment that doesn’t actually exist), and Opus 4.7 performs better than or on par with Opus 4.6 across factual hallucination benchmarks.
The customer feedback in the launch post is consistent with these numbers. Hex reports the model correctly reports when data is missing instead of providing plausible-but-incorrect fallbacks, and resists dissonant-data traps that even Opus 4.6 falls for. Vercel notes the model is more honest about its own limits and even runs proofs on systems code before starting work — behavior they had not seen in earlier Claude models. Notion measured a 14% improvement at fewer tokens and a third of the tool errors, with the model continuing to execute through tool failures that previously stopped Opus cold.
None of these are intelligence claims. They are behavioral consistency claims. For anyone operating the model in production, behavioral consistency is the metric that drives or kills a deployment.
The cost story (with real numbers)
Pricing has not changed: $5 per million input tokens, $25 per million output tokens. Three things that have changed will move your actual bill:
The tokenizer. As covered above, expect 1.0–1.35x more tokens on the same text. The token efficiency of Claude Opus 4.7 can vary by workload shape. The first thing to measure on your traffic before any production rollout.
Higher effort means more thinking. Per the launch post, Opus 4.7 thinks more at higher effort levels, particularly on later turns in agentic settings — this improves reliability on hard problems but produces more output tokens. Anthropic’s own internal coding evaluation shows token usage improving across all effort levels for that specific workload, but the result is workload-dependent.
Counter-evidence from actual deployments. Per Box’s Head of AI Yashodha Bhavnani as reported by 9to5Mac, in Box’s evaluations Opus 4.7 had a 56% reduction in model calls and 50% reduction in tool calls. The Hex observation that low-effort 4.7 matches medium-effort 4.6 points the same direction. The honest read: per-token costs may rise; per-task costs often fall, because the model finishes work in fewer iterations. Whether your bill goes up or down depends on whether your workflow is throttled by tokens-per-call or by calls-per-task.
The practical playbook: instrument cost-per-completed-task, not just tokens-per-call, before you decide whether the upgrade is favorable for your specific workload.
Claude Code: /ultrareview, auto mode, and new defaults
For Claude Code users, three changes ship alongside the model:
/ultrareview slash command. A dedicated review session that reads through changes and flags bugs and design issues a careful reviewer would catch. Pro and Max Claude Code users get three free ultrareviews to try it out.
Auto mode extended to Max. Auto mode is a permissions option where Claude makes decisions on your behalf, meaning longer tasks run with fewer interruptions and with less risk than skipping all permissions. Per 9to5Mac’s reporting, it was previously available for Teams, Enterprise, and API customers, and is now also available to Max plan subscribers.
xhigh is now the default in Claude Code across all plans and providers on Opus 4.7. Per the Claude Code docs, when you first run Opus 4.7, Claude Code applies xhigh even if you previously set a different effort level for Opus 4.6 or Sonnet 4.6. Sessions will use more thinking tokens by default, which produces higher-quality results at slightly higher cost. Override via /effort high if you preferred the old behavior.
Migration playbook
A concrete sequence for moving production workloads, distilled from Anthropic’s official migration guide:
Audit your existing prompts against the new literal instruction-following behavior on your top three workflows. Look specifically for bullet-list suggestions, imperative verbs used loosely, and any prompt that depends on the model “filling in” implied context.
Re-test integrations that set thinking: {"type": "enabled"} or any sampling parameter. Both will return 400 errors now. Migrate to adaptive thinking with effort as the depth control.
Measure tokenizer impact on a representative sample of real traffic before extrapolating cost. Code-heavy and prose-heavy workloads land at different points in the 1.0–1.35x band.
Set task_budget on long-running agentic workflows. Even if you do not yet need it as a cost guard, the discipline of declaring an upper bound forces clarity on what “done” looks like for autonomous runs.
If you are running computer-use agents, prioritize re-evaluating the vision pipeline. The 3.75MP ceiling and 1:1 coordinate mapping change architectural decisions that were made under earlier constraints.
If you have legitimate security workloads, apply to the Cyber Verification Program. The new safeguards will refuse some requests that Opus 4.6 handled.
For teams running Opus 4.6 at high or max as a reliability fallback, test Opus 4.7 one tier lower against the same evaluations. The cost-per-task math may justify staying at lower effort.
Bottom line
Opus 4.7 is the clearest signal yet that frontier model releases are bifurcating along a new axis. One axis is raw capability, where the field has visibly converged — on graduate-level reasoning measured by GPQA Diamond, as reported by The Next Web, Opus 4.7 scores 94.2%, GPT-5.4 Pro scores 94.4%, and Gemini 3.1 Pro scores 94.3%, with the differences within noise. The other axis is operational maturity: how predictably the model behaves under load, how cleanly it integrates with engineering controls, how honestly it reports its own limits.
Anthropic invested in the second axis. Self-verification before reporting, loop resistance, lower variance, fewer tool errors, honest uncertainty, task-aware budgets, literal instruction following, prompt injection resistance — the entire shape of this release is about the model being a better operational citizen, not a smarter conversationalist. The benchmark gains follow from that engineering. They do not lead it.
For anyone running agents in production, the upgrade is straightforward but the prompt audit is real. For anyone designing new agentic workflows, the launch post explicitly frames this as the model where users can hand off their hardest work with less supervision than before — a claim worth testing against your own evaluations rather than taking on faith.
The next model release will tell us whether this becomes the new norm. If it does, the era of treating frontier models as raw intelligence to be wrangled by external scaffolding is ending, and the era of treating them as engineered systems with first-class operational primitives is beginning.
Opus 4.7 is the strongest single data point so far that we are already in that second era.
Sources & further reading
Primary (Anthropic):
Introducing Claude Opus 4.7 — the official launch post, including all partner testimonials cited above
What’s new in Claude Opus 4.7 — developer documentation covering breaking changes, behavior shifts, and capability improvements
Migration guide: Opus 4.6 → Opus 4.7 — official upgrade guidance
Effort parameter documentation — recommended effort levels per workload type
Task budgets documentation — full setup and tuning guidance
Claude Code model configuration — Claude Code-specific defaults and overrides
Project Glasswing — context for the cyber capability staging strategy
Cyber Verification Program — application form for security professionals
Claude Opus 4.7 System Card — referenced throughout the launch post
Secondary (third-party reporting and analysis):
Vellum AI: Claude Opus 4.7 Benchmarks Explained — source for CyberGym scores cited above
The Decoder: Anthropic’s Claude Opus 4.7 makes a big leap in coding — source for the AI safety research refusal numbers from the system card
9to5Mac: Anthropic reveals new Opus 4.7 model — source for Box’s deployment numbers and auto mode availability details
The Next Web: Claude Opus 4.7 leads on SWE-bench and agentic reasoning — source for cross-model GPQA Diamond comparison
Subscribe to AI Engineer Weekly for technical breakdowns like this on every major model release, plus original analysis on production AI engineering. Forward to one engineer who would benefit.