

Felix Is a Harness, Not a Model: How Rogo Built an Agent for High Finance
Rogo just raised $160M Series D led by Kleiner Perkins. The architecture behind their Felix agent is what AI engineers should be studying.

TL;DR - Rogo serves more than 35,000 professionals at over 250 institutions — Rothschild & Co, Jefferies, Lazard, Moelis, Nomura — with an AI agent called Felix that bankers email like a junior analyst and get back finished decks, models, and memos. The interesting part is not the model. Rogo’s own product team calls Felix their “agent harness” — a vertical scaffolding designed to be model-agnostic across GPT 5.5, Claude Opus 4.7, and Gemini. Felix is the playbook for vertical AI: the moat is the harness, the evals, the data integrations, and the deployment model — not which frontier LLM is wired in this quarter. If you are building a vertical agent, study how Rogo decomposed the problem before you pick a model.
What Rogo Actually Sells
A precision note first: when people say “banking” in this conversation, they don’t mean retail or commercial banking. Rogo sits inside high finance — investment banking, private equity, hedge funds, equity research, asset management. Rogo’s own product page explicitly calls out its three audiences: Banking, Private Markets, Public Markets. The workflows are deal-shaped: pitchbooks, comps, models, memos, CIMs, diligence trackers.
Rogo was founded by Gabriel Stengel and John Willett — both ex-investment-bankers (Lazard, J.P. Morgan, Barclays) — with Tumas Rackaitis. That founder profile matters because the company’s edge is not the LLM; it is the granular, painful familiarity with what a 2 AM CIM revision actually looks like.
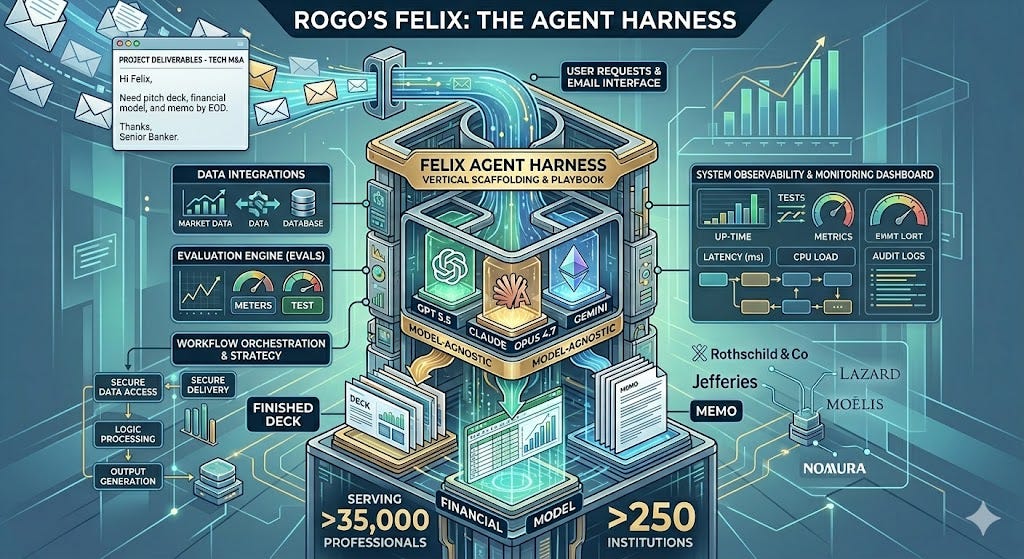
Felix Architecture
Yesterday’s $160M Series D, led by Kleiner Perkins with participation from Sequoia, Thrive, Khosla, and J.P. Morgan Growth Equity Partners, brings total funding past $300M. The capital is going toward two things that tell you what they actually believe: deeper data integrations and more forward-deployed bankers embedded inside client institutions.
Felix Is a Harness, Not a Model
The single most useful sentence Rogo has published this year shows up in their GPT 5.5 release note: “we’ve begun incorporating GPT 5.5 into our agent harness, Felix.” Read that twice.
Felix is not a fine-tuned model. Felix is the harness — the orchestration scaffold, tool layer, citation system, output formatters, audit trail, and policy controls — into which Rogo plugs whichever frontier model performs best on their internal benchmark this week. They are explicit that they are model-agnostic across OpenAI, Google, and Anthropic, and TAMradar’s coverage notes the platform supports GPT 5.5 and Anthropic Opus 4.7 concurrently.
This separation is load-bearing. In the Model Reliability Engineering frame, the harness is one of the two reliability axes — the scaffolding you build around the model to make its behavior production-safe. The harness-vs-model split is the same separation MRE treats as one of its two reliability axes. Rogo's product team uses the word the same way. The implication for builders: when frontier labs ship a 4% improvement on your domain, you swap the engine; when they ship a 40% improvement two years from now, your harness is what survives.
Here is the rough shape of what’s inside Felix:
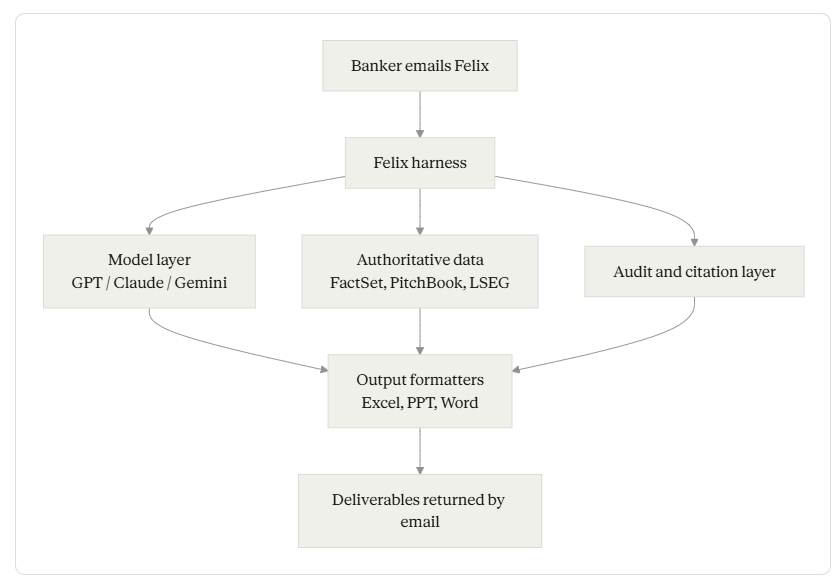
Detail belongs in the prose, not the diagram. Three components below carry the real weight.
The Email Interface Is the Real Interface
The product surface that ships with Felix is unusual: bankers send Felix an email the same way they would a colleague, get an acknowledgment in under a minute with an ETA, and receive PowerPoint, Excel, Word, and PDF deliverables back when ready. Iteration happens by replying to the email thread.
This is not a UX gimmick. It tells you something about how the team thinks about adoption. Investment bankers already live in Outlook. Asking them to adopt a new interface is a tax. Email-as-API removes the tax. It also imposes async semantics on the agent: a long-running task with intermediate status, observable state via the inbox, and a clean handoff back to the human reviewer. The harness has to absorb that asynchrony — request queuing, intermediate progress, partial results, source attribution surviving the round-trip — without leaking it back to the user.
The output substrate matters too. Felix returns work in Excel, PowerPoint, and Word formatted in the firm’s own templates and house style. A pitchbook that doesn’t match house formatting is not 90% done; it is 0% done. Vertical AI rises or falls on output substrate fidelity.
The Big Finance Benchmark: Vertical Evals Are the Moat
Rogo curates an internal evaluation set called the Big Finance Benchmark — real financial tasks designed by their ex-finance team. Tasks include valuing companies, benchmarking peers on specific metrics, and building theses across disparate documents. They are explicit that these come from real workflows, not synthetic prompts.
This is the unsexy infrastructure that compounds. When OpenAI ships GPT 5.6 next quarter, Rogo will know within a day whether it improves CIM drafting on real deals or just MMLU. That is the kind of judgment a horizontal benchmark cannot give you. Every serious vertical AI company will need its own version of this. If you are building one and you don’t have a domain-specific eval suite, you are flying without instruments.
Workflow Surface: What Felix Actually Does
The concrete capabilities Rogo has shipped span deal screening, CIM generation, buyer outreach, and data room diligence. Decomposed:
Deal screening. Filtering thousands of potential targets against thesis criteria.
CIM generation. Drafting Confidential Information Memoranda — the 50-to-100-page sell-side documents that anchor M&A processes.
Buyer outreach. Generating personalized contact lists and initial communications.
Data room diligence. Synthesizing across the document piles that buyers and bankers wade through.
Comps and models. Building Excel spreadsheets with historical financials and forward forecasts.
Pitchbooks and memos. Decks for a CEO meeting, memos for an investment committee.
SiliconANGLE’s coverage notes that Felix can also offer to keep a report current — for example, an analyst covering Apple can have the agent re-run the report each time the company reports earnings. Scheduled, recurring agent runs are part of the surface.
The data substrate behind these tasks is extensive. TAMradar lists integrations with PitchBook, LSEG, Cap IQ, FactSet, Fitch Solutions, and Third Bridge, plus internal CRM and SharePoint connectors. Auditable outputs are positioned for SOC 2, ISO 27001, GDPR, and EU AI Act compliance — the table-stakes regulatory surface for institutional finance.
Sisyphus: The Other Harness
The most under-covered part of Rogo’s stack is a second internal agent called Sisyphus — an autonomous offensive-security agent that pen-tests Rogo’s own infrastructure once or twice a day, calibrated to deployment cadence. It runs structured campaigns across authentication abuse, authorization bypass, injection, SSRF, and LLM-specific exploit categories, and it chains findings to validate exploitability rather than just flagging signals.
Two numbers from Rogo’s own writeup are worth remembering. One week after a third-party penetration test, Sisyphus identified 18 additional exploitable vulnerabilities in a single afternoon, most chained, all remediated within hours. And on calibration: high-confidence findings now carry a >95% true-positive rate after the team tuned the recon phase and compared the agent’s triage against their human security team.
This is the harness for the harness. If your vertical agent platform handles consequential workflows, “we get pen-tested twice a year” is not a posture; it is a vulnerability window. Sisyphus is what the security side of vertical AI starts to look like.
Forward-Deployed Bankers: The Human Harness
Rogo’s go-to-market is structured around an embedded role they call Forward Deployed Bankers — ex-bankers from top firms who sit inside client institutions and onboard teams from analyst to managing director. The new capital is funding expansion of this team from New York into London.
This is not professional services in disguise. It is closer to what Palantir built for defense and intelligence: domain-fluent humans who translate between the workflow and the platform, calibrate the agent’s outputs to firm-specific style, and surface workflow gaps that become product. They understand model formatting and how a positioning section actually reads. Without them, the harness loses ground truth on what “good” looks like inside each firm’s house style.
For builders: the lesson is that adoption inside regulated, high-status industries is bottlenecked on trust transfer, not feature parity. The forward-deployed model is expensive and it is a moat.
What’s Actually Being Transformed
Bankers do not get replaced; their pyramid does. Rogo’s Series D announcement is explicit that leading firms are “restructuring workflows, rethinking staffing pyramids, and deploying autonomous agents that work asynchronously across every transaction.” A managing director at one client described Felix as having tripled team output with no headcount additions. That is the shape of the transformation: same senior judgment layer, compressed junior layer, agent layer doing the asynchronous grunt work, forward-deployed bankers tuning the seams.
Rogo’s two recent acquisitions tell you where they are aiming next. Plux AI — a UK firm tracking complex financial market developments — adds European market coverage. Offset, an AI agent company whose tech automatically updates financial models when new information arrives, plugs directly into the live-model side of the harness.
Five Lessons If You Are Building a Vertical Agent
The harness is the moat, not the model. Build it so frontier-model upgrades are a config change, not a rewrite.
Domain-specific evals beat horizontal benchmarks. Curate real tasks from real practitioners. Run them every model release.
Output substrate must match the destination workflow. A correct answer in the wrong format is the wrong answer.
Forward deployment changes adoption math. Domain-fluent humans embedded in the customer org are a feature, not overhead.
Security needs its own harness. When agents do consequential work, periodic pen tests leave a window. Continuous adversarial testing is the new floor.
What to Do This Week
Pick one workflow you’ve watched a domain expert do that you suspect an agent could absorb. Don’t model it yet. Instead, write down four things: the data sources they pull from, the output format they hand back, the audit trail they leave, and the colleague they email when they get stuck. Those four are your harness specification. The model goes in the middle of that, and you can swap it out next quarter.
If your current agent prototype only handles one or two of those four, you have not built a harness yet. You have built a wrapper.