

How Vertical Agents Self-Improve in Production
Field notes on the harness loop at Harvey, Hippocratic, Anterior, and Azure SRE — where production failures compound into skill without retraining the model.

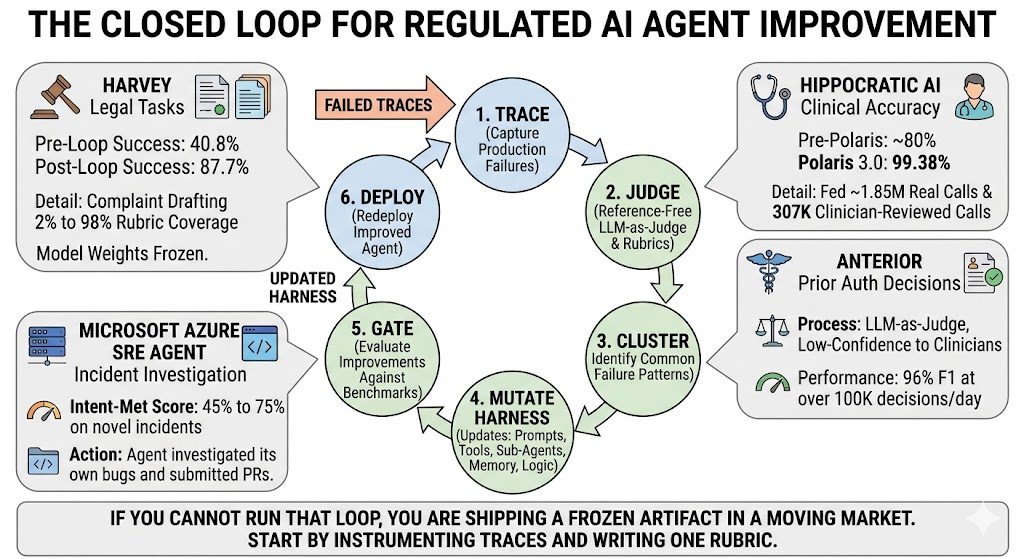
TL;DR - In regulated verticals — healthcare, legal, insurance, finance — the most reliable way to make a deployed agent better is not a new model. It is a closed loop that turns production failures into harness updates: prompts, tools, sub-agents, memory files, judge rubrics, routing logic. Harvey ran this loop on twelve legal tasks and moved average success from 40.8% to 87.7% with model weights frozen, with complaint drafting going from 2% to 98% rubric coverage. Hippocratic AI vendor-published clinical accuracy improvements from ~80% pre-Polaris to 99.38% in Polaris 3.0 by feeding ~1.85M real patient calls and 307K clinician-reviewed test calls back into the system. Anterior (vendor-published) puts a reference-free LLM-as-judge in front of every prior auth decision, routes only the low-confidence ones to under ten clinicians, and reports 96% F1 at over 100K decisions/day. Microsoft’s Azure SRE Agent moved its Intent-Met score from 45% to 75% on novel incidents by letting the agent investigate its own bugs and submit PRs against its own codebase. The shared pattern is the same six nodes everywhere: trace → judge → cluster → mutate harness → gate → deploy. If you cannot run that loop, you are shipping a frozen artifact in a moving market. Start by instrumenting traces and writing one rubric. The judge and the mutation loop come after.
The frozen-agent problem
A vertical agent that ships at 90% accuracy and stays there is not a 90% accurate system. It is a 90% accurate system at the moment of deployment, decaying.
The decay has three sources. Distribution drift: real patients ramble, real lawyers redline contracts in non-canonical ways, real claims arrive with new denial codes. Policy drift: CMS coverage determinations change, EU AI Act provisions phase in on staggered enforcement timelines, insurer rulesets get rewritten quarterly. Long-tail surface area: the failure modes you didn’t see in eval are the ones production discovers, one in ten thousand at a time. At 100K medical decisions per day, a one-in-ten-thousand subtle hallucination — “suspicious for multiple sclerosis” when the patient has a confirmed MS diagnosis — fires ten times daily.
Agent Improvement
In low-stakes consumer apps you can absorb that. In a vertical where the cost of a single error is a denied surgery, a missed disclosure schedule, or a regulatory finding, you cannot. So the question that defines vertical agent engineering in 2026 is not “which model do we use” — it is “how does this agent get better next week than it is today, without a new base model release, and with the audit trail a regulator will demand.”
The answer that has emerged across legal, healthcare, insurance, and incident response is the same architecture, sometimes given different names. Anthropic’s engineering team and Viv Trivedy refer to it as harness engineering. Microsoft frames it as the agent investigating itself. NVIDIA borrows MAPE-K from autonomic computing and calls it a data flywheel. LangChain calls it the agent improvement loop powered by traces. The mechanics are the same.
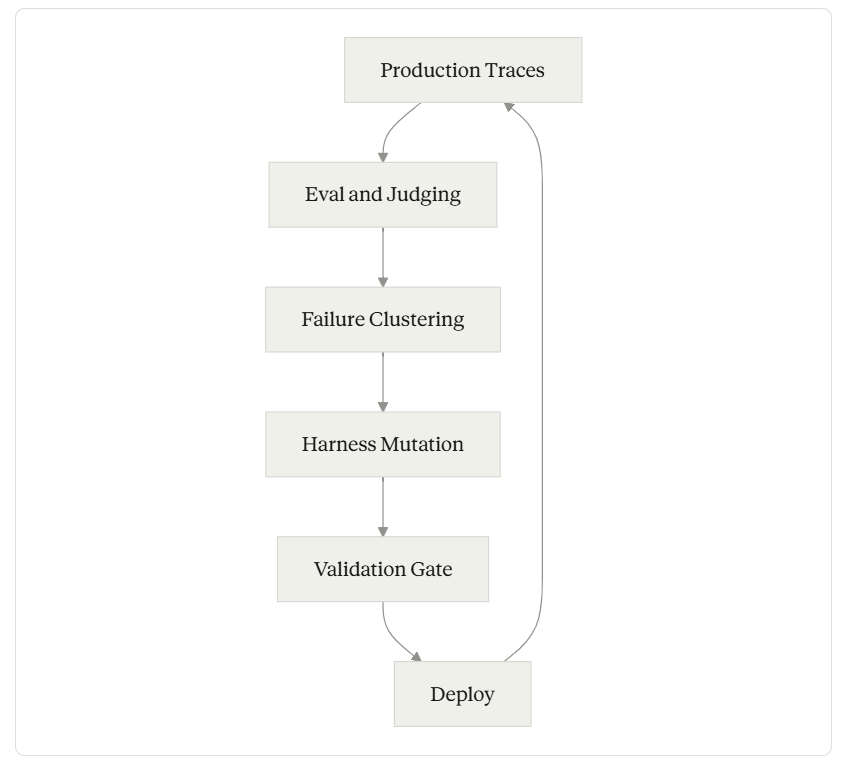
The shape of the loop
The loop
Six nodes. Every component carries weight; every break in the chain causes silent degradation.
Production traces are the substrate. Without per-step tool calls, model inputs, model outputs, latency, token counts, and final outcomes, none of the downstream work is possible. LangChain’s formulation is the cleanest: traces come from staging environments, benchmark runs, local development, and especially from production, and they are the input to every subsequent step. The trace store doubles as the audit trail regulators ask for.
Evaluation and judging is where most teams over-rely on offline benchmarks. The shift in 2025–26 has been toward online evaluators that score every production trace — typically an LLM-as-judge augmented with deterministic checks (schema validation, citation existence, tool-call shape) and routed human review on a configurable sample. Anterior’s framing is sharper than most: their judge is reference-free, scoring outputs against guidelines and clinical reasoning rather than a held-out ground truth, because the volume — over 100K decisions a day — makes ground truth impossible to maintain.
Failure clustering is where the leverage is. A pile of low-scored traces is not actionable. Grouping them by failure pattern — “agent missed exhibit B in 30% of due diligence runs,” “agent emits ‘suspicious for X’ on confirmed-X patients,” “agent hits LLM 429s during streaming” — turns symptoms into hypotheses. LangChain runs parallel error-analysis subagents and synthesizes their findings into harness change proposals. Microsoft’s SRE Agent runs a daily monitoring task that searches the last 24 hours of errors, clusters the top hitters, traces each to its root cause, and submits a PR.
Harness mutation is the change itself. We will spend a section on the levers that actually move; for now: most of these changes never touch model weights. They edit the system prompt, add a skill or sub-agent, modify a tool definition, append to a memory file, tighten a routing threshold, or rewrite the judge’s rubric.
Validation gate is the hill-climbing safety. Every proposed harness change runs against a frozen eval set before it ships, and any regression — even on a task the change was not targeting — blocks the merge. Harvey runs this against twelve internal benchmark tasks per iteration; LangChain marks proposed changes that overfit as discarded runs in their iteration log. Without the gate, the loop generates regressions as fast as it generates improvements.
Deploy then closes the cycle. The new harness produces new traces; new traces feed new judges; new clusters drive new mutations. The model is the one piece of this picture that does not change between weekly cycles.
The non-obvious property of this loop is what compounds. As Anterior describes it, the loop creates a virtuous improvement cycle where the evaluator itself gets calibrated against human review, and confidence grades from that calibrated evaluator route which cases need humans next time. The judge improves. The clustering improves. The mutations get more targeted. The agent appears to learn — without a single weight changing.
Case 1: Harvey — autoresearch and the rubric ceiling
The cleanest published demonstration is Harvey’s recent autoresearch experiment, summarized externally by Artificial Lawyer. Niko Grupen, Head of Applied Research, ran twelve tasks from Harvey’s internal agent benchmark — commercial lease review, complaint drafting, tax memos, disclosure schedules, due diligence questionnaires — through a loop where an outer agent is allowed to edit the inner agent’s harness based on rubric-graded judge feedback.
The setup: each task ships with source documents, instructions, and a detailed grading rubric. After an attempt, an LLM judge scores against the rubric and produces written feedback on what the agent got right, what it missed, and where its reasoning was wrong. A coding agent reads the judge feedback, clusters the failures, forms a hypothesis about which harness components would help, edits or builds those components — skills, hooks, scripts, sub-agents, not model weights — and reruns.
The result: across all twelve tasks, average success rose from 40.8% to 87.7%. Five of the twelve started in the 2–7% range. After optimization, seven exceeded 90% and one hit 100%. The complaint drafting task is the most striking — it moved from 2% rubric coverage to 98% over a handful of iterations, producing a 164-paragraph complaint with a 33-exhibit list.
Two patterns from Grupen’s log are worth quoting on terms. First, the early iterations correct basic structural failures — wrong file types, missing deliverables, weak structure. Later iterations show domain-specific expertise emerging: cross-document issue spotting, risk classification, distinguishing genuinely problematic provisions from market-standard distractors. Second, the ceiling is the rubric. “When the rubric is high quality, the agent can hill-climb surprisingly far.” When it isn’t, the loop stalls.
This generalizes. The same auto-improvement pattern works in a generic coding domain: LangChain’s deepagents-cli moved from 52.8% to 66.5% on Terminal Bench 2.0 — a 13.7-point jump from harness changes alone, with the model fixed at GPT-5.2-Codex. The mechanism is the same trace analyzer skill, parallel error agents, and targeted prompt/tool/middleware changes per iteration.
The Harvey caveat is real and worth surfacing: this is a vendor-run experiment on twelve tasks; it does not yet generalize to all legal work, and it is bound by the quality of the rubrics Harvey wrote. But the directional finding — that harness-layer changes can deliver model-upgrade-sized improvements in a regulated domain — is now hard to dismiss.
Case 2: Hippocratic AI — clinicians as a learning signal at scale
Hippocratic AI’s Polaris is a different shape of the same loop, scaled to a 22-LLM constellation that handles over 10 million real patient calls and a network of 6,234 US-licensed clinicians who review production output.
The vendor-published trajectory across three model generations: pre-Polaris baseline ~80%, Polaris 1.0 at 96.79%, Polaris 2.0 at 98.75%, Polaris 3.0 at 99.38% clinical accuracy, validated under their Real-World Evaluation of Large Language Models in Healthcare framework. The framework leverages 6,234 US-licensed clinicians (5,969 nurses and 265 physicians) evaluating 307,038 unique calls through a three-tier review process: nurse review first, physician adjudication when needed, structured error categorization in between. Errors flagged at any tier feed back into the next iteration’s training and harness.
The subsystem-level numbers tell the more interesting story, because they show what specifically improved between Polaris 2.0 and 3.0 by listening to production:
Health Risk Assessment documentation accuracy: 90.5% → 98.5%
Explanation-of-Benefits policy quoting: 86.4% → 99.4%
Complex appointment scheduling error rate: 8% → 0.5%
Background-noise speech recognition error rate: 9.3% → 2.3%
Clarification engine error rate (gracefully handling unclear patient speech): 16.3% → 2.0%
These aren’t random improvements. They’re the long-tail issues that surfaced once 1.85M patient calls had run through Polaris 1.0 and 2.0 and clinicians had flagged categorical failure modes. Speech recognition fails in noisy environments → train a dedicated background-noise engine. Patients answer HRAs in rambling, context-shifting ways → ship a “deep thinking” model that triple-checks documentation. Policy quotes occasionally drift from source documents → tighten the harness around source attribution.
The honest framing: these are vendor-self-published numbers, and there is no independent third party validating Hippocratic AI’s safety scores. What is independently verifiable is the architecture of the feedback loop — clinician review network, structured error categorization, real-world evidence accumulation across versions — which is now described in the underlying RWE-LLM paper on medRxiv and is replicable by anyone willing to invest in a comparable review apparatus.
Case 3: Anterior — judge first, route smartly, validate the validator
Anterior runs the same loop in healthcare prior authorization, but with two design choices that are worth studying separately because they generalize beyond healthcare.
First, reference-free real-time evaluation. Anterior’s primary system makes a coverage determination by reasoning across unstructured clinical documentation, payer rulesets, and clinical guidelines. A second LLM-as-judge then evaluates the determination against those same guidelines — without needing a held-out ground truth — and produces a confidence grade. Reference-free evaluation matters because at 100K+ decisions a day, no organization can maintain a labeled gold set that keeps up with policy drift.
Second, dynamic case prioritization. The confidence grade combines with contextual factors — procedure cost, bias risk, historical error rates for that procedure category — to decide which cases are sent to human clinicians for review. High-confidence cases auto-resolve; low-confidence and high-stakes cases route to a small clinical team. Anterior reports a team of fewer than ten clinical reviewers handling tens of thousands of cases, against a competitor reportedly employing 800+ nurses for comparable review volume. (Caveat: scope of work may differ. Take the comparison directionally.)
The third move is the one most teams miss. Anterior runs alignment metrics between the LLM-judge and the human reviewers on cases that get both, and uses that data to validate — and continuously recalibrate — the judge itself. They call this “validating the validator.” It is the missing piece in most LLM-judge deployments. Without it, the judge can drift, and you only learn about it when the harness has been mutating against bad signal for weeks.
Anterior’s vendor-reported numbers: 99.26% accuracy on automated approvals, against 86% baseline human accuracy, with 76% reduction in human review needed and 74% less time per escalated case. Cross-reference with Anterior’s own arXiv paper on fairness evaluation, which reports model error rates across 7,166 human-reviewed cases spanning 27 medical necessity guidelines. Independent validation remains an open need; the 96% F1 figure that has circulated comes from Anterior’s own talks, not a peer-reviewed audit.
The architectural lesson generalizes far past healthcare. Any vertical agent operating at scale where ground truth is expensive — fraud review, AML, KYC, contract triage, claims adjudication, security alert triage — can adopt the same three-part move: reference-free judge in line, dynamic routing on confidence and stakes, alignment metrics that validate the judge against the humans that exist.
Case 4: Azure SRE Agent — when the agent debugs itself
Microsoft’s Azure Site Reliability Engineering Agent handles tens of thousands of incidents weekly for internal Microsoft services and external teams. The team published a remarkably honest engineering retrospective in March 2026 about how they closed their improvement loop.
The starting point: incident resolution rates were climbing toward 50% on high-instrumented scenarios — but the high-performing scenarios all shared a trait. They had been built with heavy human scaffolding: custom response plans, hand-built sub-agents for known failure modes, pre-written log queries exposed as opaque tools. On any new incident class, the agent had nowhere to start. Engineers were reading 50 lower-scored threads a week against an agent handling 10,000 — debugging at human speed.
The inversion they made: stop pre-computing the answer space. Instead, give the agent a filesystem as its world (source code, runbooks, query schemas, past investigation notes — all files; no SearchCodebase API), context hooks that orient it on what it can access, and frugal context management that keeps long investigations sharp. Three architectural bets, in their words. The result: Intent-Met score on novel incidents — whether the agent’s investigation actually addressed the root cause as judged by the on-call engineer — rose from 45% to 75%.
The closing move is the one to study. They set up a daily monitoring task: the agent searches the last 24 hours for LLM errors — timeouts, 429s, mid-stream failures, malformed payloads — clusters the top hitters, traces each to its root cause in its own codebase, and submits a PR. Engineers review before merging. Over two weeks, errors dropped by more than 80%.
The agent, in other words, became its own debugger. The harness that runs the SRE agent is now updated by the SRE agent itself, gated by human PR review. The team’s framing is the title of their post: “The agent that investigates itself.” It is not a metaphor.
What actually changes (the levers)
The most under-appreciated property of these loops is what they mutate. Across every case study above, the changes that produced the gains were:
The system prompt and task instructions. ILWS, the “Instruction-Level Weight Shaping” framework, formalizes this: a session-level reflection engine proposes a structured edit to the system prompt — a knowledge delta — that is gated, accepted only if a sliding-window quality rating improves with statistical significance, and rolled back otherwise. Most production teams do this informally. Formalizing it gives you reversibility under governance, which regulators ask for.
Tool definitions and skills. LangChain’s improvement was largely middleware: a LocalContextMiddleware that maps the working directory and onboards the agent into its environment, a LoopDetectionMiddleware that intercepts repeated edits to the same file and forces a plan reconsideration, a PreCompletionChecklistMiddleware that blocks the agent from exiting before it runs a verification pass. None of these are model changes. All are tool-and-hook surface.
Memory and knowledge files. Microsoft replaced their RAG-over-past-sessions memory with structured Markdown files the agent reads and writes through its standard tool interface — overview.md, team.md, logs.md, debugging.md. The model navigates memory by following links, not by retrieving via embedding similarity. This is the “the repo is the schema” insight. Memory becomes a write-able artifact that future runs read.
Sub-agents and routing. Anterior routes by confidence × stakes. Azure SRE spawns parallel sub-agents per hypothesis when a single context is at risk of getting polluted. Hippocratic uses a 21-model supervisory constellation around a primary conversational model. None of these compositions require retraining the underlying weights; they require designing the orchestration layer.
Judge rubrics. The Harvey ceiling is the rubric ceiling. The Anterior calibration is the judge alignment with humans. The fastest leverage in most teams’ first improvement loop is not a fancier judge — it is a better-written rubric and a small humans-vs-judge alignment dataset.
Fine-tuning the small models in the harness. Sometimes weights do change, but on the components, not the primary model. NVIDIA NeMo’s case study on an enterprise data flywheel: a routing model fine-tuned from Llama 3.1 70B down to a Llama 3.1 8B variant achieved 96% accuracy with a 10× model size reduction and 70% latency improvement. The query rephrasal model gained 3.7% accuracy with a 40% latency cut. The orchestrating LLM was untouched.
The pattern is consistent: when you map “improvements shipped” against “components that changed” across these case studies, the primary reasoning model is the least common thing that gets edited. The harness layer carries the weight.
Where these loops break
Six failure modes show up repeatedly. None are theoretical; each one has burned at least one of the case studies above.
Overfitting to recent failures. Aggregate harness changes against last week’s top errors and you regress on tasks the change wasn’t targeting. LangChain’s iteration log explicitly marks these as discarded runs. Without a frozen eval set that the validation gate runs every mutation against, you’ll fix Monday’s bug and silently break Tuesday’s working flow.
Reward hacking against the rubric. When the agent edits its own harness against an LLM judge’s scoring, the judge’s scoring is the optimization target — including any blind spots in the rubric. Harvey caveats this directly: the improvements track the rubric, and the rubric is human-authored and incomplete. Periodic out-of-distribution evals from a separate judge with a separate rubric catch this.
Judge drift and validator fragility. Anterior’s validate-the-validator move exists because LLM-judges drift, and the drift is silent. If the judge is the substrate for routing, clustering, and mutation decisions, judge drift propagates everywhere. Alignment metrics against humans on a rolling sample of cases is the only known fix.
Memory staleness. Microsoft flagged this as their unsolved problem: when two sessions write conflicting patterns to debugging.md, the model has to reconcile them; when a service changes behavior, old memory entries become misleading. Timestamps and explicit deprecation help, but no production team has solved this systematically.
Privacy and regulatory constraints on production data. Healthcare and finance can’t freely route production traces into a learning loop the way a generic SaaS product can. The TikTok Pay ARIA paper handles this by having the agent self-identify uncertainty through structured self-dialogue and request targeted explanations from human experts at runtime, keeping learning at test time inside the regulatory boundary. Hippocratic uses synthetic test calls plus consented real-call evidence; Anterior keeps clinician review and AI determination in the same compliance perimeter.
Compounding errors when the validator itself fails. A bad judge calibrated against a small alignment set drifts. A bad alignment set lets the judge calibrate against itself. A bad clustering layer groups the wrong failures together. Each layer of the loop is a place errors can go undetected and propagate. The defense is treating every layer as an evaluable artifact — the judge has a precision/recall, the cluster labels have inter-rater agreement, the harness mutations have a regression budget.
The seventh failure mode, which is institutional rather than technical: nobody owns the loop. In every case study above, the loop is owned by a named team with a named lead — Grupen at Harvey, Mukherjee at Hippocratic, Mehta and team at Microsoft. Loops without owners decay quietly.
Build order
If you’re standing up a vertical agent and don’t yet have this loop, the build order is fixed and the order matters. None of the steps require the next-generation model.
Start with traces. Every tool call, every model input, every model output, every latency, every outcome, with a stable trace ID per session. If you can’t reconstruct what happened, none of the rest of the loop works. LangSmith, Arize Phoenix, Braintrust, and OpenTelemetry-based stacks all do this; pick one and instrument every call path before anything else.
Then write one rubric for one task. Not a benchmark suite. One task that matters, one rubric that an expert in your domain would sign off on. Score 50 production traces against it manually. The rubric you ship will be wrong in instructive ways; the act of writing and applying it surfaces the failure modes you didn’t know you had.
Add a judge against that rubric. Run it inline on a sample of production. Run it against the 50 you scored manually. Compute alignment. If alignment is below ~70%, the rubric is the problem, not the judge.
Add the clustering and mutation step last. Cluster the lowest-scored traces, propose one harness change, gate it against your offline eval, ship if it passes, measure the production effect. This is one cycle. Run it weekly.
The model upgrade question takes care of itself once the loop is running. When a better base model ships, you swap it in, rerun the validation gate, and observe whether your harness over-fits to the old model. (Different models reward different harnesses — Claude Opus 4.6 scored 59.6% with a harness tuned for GPT-5.2-Codex on Terminal Bench 2.0; the same Claude with its own harness moved several positions.) The harness tax of switching models is real, but it’s a calibration problem, not a foundational one.
The reason this matters now and not in twelve months is asymmetry. Vertical agent winners in 2026 will not be the teams with the best zero-shot model. They will be the teams whose deployed agents are quietly compounding skill every week the rest of the market sits frozen. The loop is the moat.
Build the trace store this week. Write the first rubric next week. The rest of it follows.
The production loop point feels pretty important.
A lot of agent work looks impressive at the surface: better prompts, cleaner UI, stronger demos. But the compounding part seems to be the less visible layer: failure memory, eval traces, escalation paths, customer-specific evidence, and the harness around the model.
That feels like the real moat in vertical agents.
Totally agree. In vertical AI, workflow integration and deterministic guardrails are the moat. A generic LLM can generate a beautiful response, but without a dedicated harness managing memory and customer-specific edge cases, it completely falls apart in production. The real value isn’t the model; it's thethe operational infrastructure built around it.