

Inside Mintlify’s Agent Stack
A teardown of the two-harness architecture — async sandboxes for writes, virtual filesystems for reads — and what it teaches about wrapping a model in production.

TL;DR - Mintlify just raised $45M at a $500M valuation on the bet that documentation has stopped being something humans read and started being infrastructure that agents query. Their own traffic data backs the bet: across 30 days and roughly 790M requests on Mintlify-powered sites, AI coding agents accounted for 45.3% of traffic versus 45.8% for browsers, with Claude Code alone generating more requests than Chrome on Windows.
Underneath the bet sits a three-part architecture worth studying. The write agent runs inside ephemeral Daytona sandboxes with a headless OpenCode session driven by Opus 4.6, triggered by Slack mentions, dashboard prompts, API calls, or YAML-defined Workflows in your repo. The read assistant does the opposite — it skips real sandboxes entirely in favor of ChromaFs, a virtual filesystem layered over their existing Chroma database, taking session creation from roughly 46 seconds to about 100 milliseconds. The public surface auto-generates llms.txt, llms-full.txt, and skill.md at the root, serves clean Markdown when you append .md to a page URL, and hosts an MCP server for every docs site it powers.
The architectural lesson isn’t that they built a doc agent. It’s that they built two harnesses with deliberately asymmetric constraints — async writes get full sandboxes, sync reads get a virtual filesystem — and the asymmetry is what makes the system economical at over 23 million queries a month. If you’re wrapping a model around a code repository for any reason, this is the reference implementation to study.
The 45% problem
Start with the data, because the architecture only makes sense once you accept the premise.
In April 2026, Mintlify’s co-founder Han Wang published a Cloudflare-header analysis covering 30 days of traffic across all Mintlify-powered docs sites. The headline number: AI coding agents had reached 45.3% of total requests, narrowly behind 45.8% from browsers. The distribution was lopsided. Claude Code alone produced 199.4M requests, ahead of Chrome on Windows at 119.4M. Cursor produced 142.3M. Together those two tools accounted for roughly 96% of identified AI agent traffic. Mintlify itself notes the real share is likely higher, since Codex traffic is invisible to user-agent header analysis and disappears into generic HTTP requests.
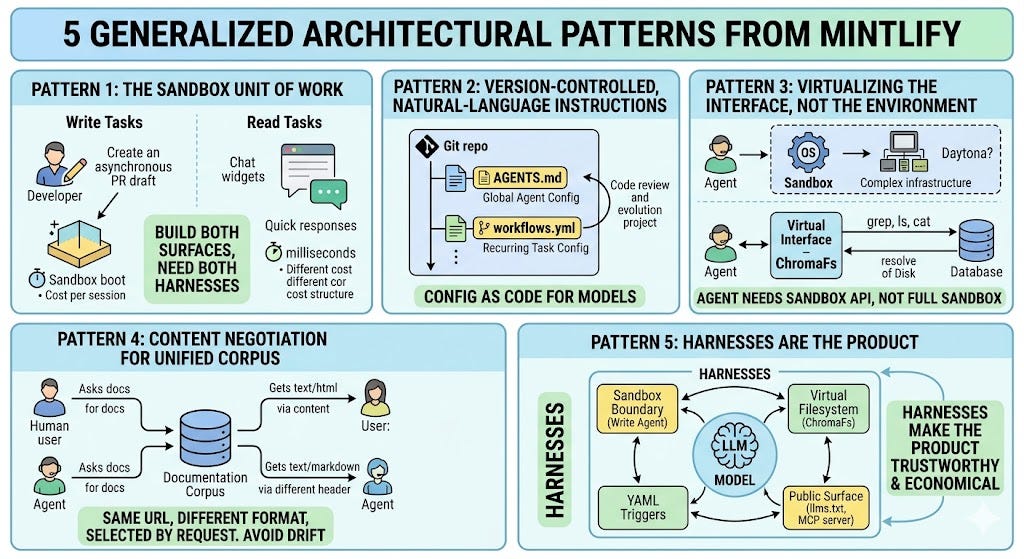
Architecture Patterns
If half your readers are agents pulling context to generate code, the design pressure on documentation flips. Browsers want navigation chrome, syntax highlighting, expandable sections. Agents want clean Markdown, exact strings, and stable URLs. The same content has to render correctly to both audiences, and — critically — has to stay current as the underlying product ships at agent-swarm speed.
That second pressure is the one that produced the agent stack. As Mintlify’s other co-founder Hahnbee Lee frames it, when a chatbot gives a wrong answer it is usually a documentation failure rather than a model failure, because the corpus the model retrieved against is out of date. The gap between what your docs say and what your product does compounds quarter over quarter unless something automated keeps the two in sync. Their answer is two distinct agents with two distinct harnesses, plus a public surface that exposes the maintained corpus to every other agent in the ecosystem.
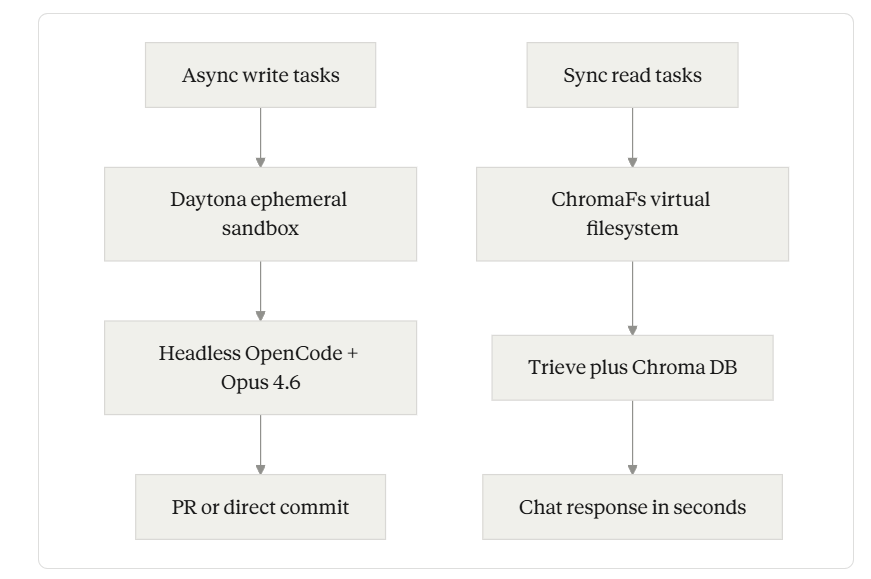
Two harnesses, two latency budgets. The write path optimizes for capability; the read path optimizes for cost-per-conversation.
Layer 1 — The write agent: a sandbox is the whole product
Most “AI doc writer” features on the market today are roughly one prompt, one model call, one diff. Mintlify’s write agent is structurally different. When you trigger it — by @mintlify-ing the bot in Slack, hitting Cmd+I in the dashboard, calling the agent API, or merging a PR that fires a Workflow — what runs on the other side is a headless OpenCode session driven by Opus 4.6, scoped to a fresh Daytona container that has the docs repo and any context repositories cloned in. The sandbox is the unit of work.
This decision is more load-bearing than it sounds. The Mintlify team is explicit about the reasoning: pointing a stateless model at a codebase produces, in their phrase, “chaos with a byline”. The agent needs a real environment to read code, plan changes, and edit files safely — not an API call decorated with retrieved chunks. So they gave it one. A trigger lands on a job queue, a worker provisions the container, and the result of the run is reported back through GitHub commit checks and the Mintlify dashboard. Inside the container, the agent runs through a fixed pipeline: it pulls in relevant material across the docs and the connected code repos, drafts a multi-step plan if the work calls for one, applies edits while honoring the project’s writing standards, runs a local Mintlify CLI build to confirm the docs still compile, and opens a pull request — direct commits to main are not on the menu.
Two design choices inside that loop are worth pulling out.
Slack-first, not terminal-first. The Mintlify agent originally shipped only in Slack and via API, with the dashboard surface added later in December 2025. The team’s stated reason: opening a terminal triggers a “mentally draining switch” that opening Slack does not, and documentation work is exactly the kind of task people procrastinate on. By living where the relevant context already lives — the PR thread that explained the change, the customer Slack message that surfaced the gap — the trigger surface matches the source of the work.
Behavior-as-code through AGENTS.md. The agent reads a config file at .mintlify/AGENTS.md in your repo, and appends its contents to its system prompt for every task it runs — whether the trigger comes from Slack, the dashboard, or the API. The path matters: Mintlify’s docs explicitly warn that placing the file at the project root exposes it as a public asset under /agents.md, since the .mintlify/ directory is not served on the docs site. What you put inside is style preferences, code standards, project-specific terminology — the kind of guidance a senior reviewer would otherwise repeat fifty times a year. It is the same pattern as Anthropic’s CLAUDE.md or the AGENTS.md spec emerging across the agent tooling space, and it makes agent behavior version-controlled and reviewable.
The most interesting trigger surface is Workflows, where the YAML config gets explicit. A workflow file lives in your repo. The schema looks roughly like this:
---
name: 'Update API reference on backend changes'
on:
push:
- repo: 'your-org/backend'
branch: main
context:
- repo: 'your-org/docs'
- repo: 'your-org/openapi-specs'
automerge: false
---
When the backend repo merges a PR, scan the diff for changes to public API
endpoints, request/response schemas, or authentication behavior. Update the
matching API reference pages and code examples. Skip internal refactors.The structure is a trigger (cron job or push event), a list of context repos to clone in, an automerge flag, and natural-language instructions in markdown. When the trigger fires, the agent evaluates the conditions, runs the task, and either commits directly or opens a PR depending on configuration, so cost stays predictable. Documentation maintenance becomes a downstream event of shipping, not a separate task someone has to remember.
The whole arrangement maps onto a pattern emerging across serious agent products: give the AI a sandbox, version-control the instructions, keep humans in the review loop, and let the model do the actual work inside well-defined guardrails. The reviewer-on-PRs analogy is doing real work here. The agent is treated like a junior contributor with full repo access — capable, but reviewed.
Layer 2 — The read assistant: when a real sandbox is the wrong answer
If the write agent shows what it looks like to spend latency to gain capability, the read assistant shows the opposite trade-off — and it is the more architecturally surprising of the two.
The read assistant is the chat widget your readers use on a Mintlify-powered docs site. It now serves over thirty thousand conversations a day across hundreds of thousands of users. The natural design — and the one Mintlify started with — was the same shape that powers the write agent: spin up a sandbox, clone the docs repo, let the model run real grep, cat, ls, and find against the filesystem.
That design hit two walls. First, latency: p90 session boot time, including the GitHub clone and other setup, came in around 46 seconds — fine for an async write task where someone fires a Slack message and walks to get coffee, fatal for a reader staring at a loading spinner on a docs page. Second, cost. At nearly a million conversations a month, even a minimal sandbox setup at 1 vCPU, 2 GiB RAM, and a five-minute lifetime would have run north of $70,000 a year on Daytona’s per-second pricing, with longer sessions doubling the bill.
So the team built ChromaFs — a virtual filesystem that gives the agent the illusion of a real shell, layered over the Chroma database that already stored the docs as embedded chunks. Session creation collapsed from tens of seconds to roughly 100 milliseconds, and because ChromaFs reuses infrastructure they were already paying for, the marginal compute cost per conversation dropped to zero. The implementation runs on top of just-bash, a TypeScript reimplementation of bash from Vercel Labs that exposes a pluggable IFileSystem interface. just-bash parses commands, pipes, and flags; ChromaFs translates each underlying filesystem call into a Chroma query.
The mechanics are worth dwelling on, because they reveal how thoughtful harness design beats brute-force sandboxing.
The directory tree is bootstrapped from a single gzipped JSON document called __path_tree__ stored inside the Chroma collection. On startup, the server fetches and decompresses it into two in-memory structures — a set of file paths and a map from directories to their children. After that, ls, cd, and find resolve in local memory with zero network calls, and the tree is cached so subsequent sessions for the same site skip the fetch entirely. Per-user access control happens at tree-build time: ChromaFs prunes paths the user can’t see and applies a matching filter to all subsequent Chroma queries, with the result that pruned paths cannot even be referenced by the agent. Reading a page is a chunk-reassembly operation — cat /auth/oauth.mdx fetches all chunks with the matching slug, sorts them by chunk_index, and joins them into the full page. Writes throw EROFS, making the system stateless by construction.
The most clever piece is grep. A naive recursive grep over a virtual filesystem would be agonizing — every file would round-trip to the database. ChromaFs intercepts the grep call, parses flags with yargs-parser, and translates them into a Chroma query ($contains for fixed strings, $regex for patterns) that acts as a coarse filter to identify which files might contain a hit. The matched chunks are bulk-prefetched into a Redis cache, and the rewritten grep is handed back to just-bash for in-memory fine filtering. Large recursive queries finish in milliseconds.
Sitting beneath ChromaFs in the read path is Trieve, the RAG infrastructure company Mintlify acquired in July 2025. Trieve had been Mintlify’s search backbone since before the team finished its Y Combinator batch, and the acquisition brought retrieval ownership in-house at a moment when the assistant was already serving more than 23 million queries a month. Trieve’s stack — dense vector search, re-ranker models, sub-sentence highlighting, and date recency biasing on a single endpoint — does the heavy lifting underneath ChromaFs’s UNIX-style interface. Trieve also moved to an MIT license as part of the acquisition, so the same retrieval kernel is inspectable on GitHub.
The pattern in the read assistant is the part most teams underweight. Mintlify’s team observed that agents are converging on filesystems as their primary interface, because grep, cat, ls, and find are sufficient primitives for an agent to reason over arbitrary structured content. Most builders take that observation and reach for a real sandbox. Mintlify took the same observation and asked whether the interface could be virtualized while keeping the primitives real. For their workload, the answer was yes — and the cost curve in their post (sandbox cost grows linearly with conversation duration; ChromaFs stays flat) is a clean argument for why.
Layer 3 — The public surface: content negotiation as the unification trick
The third layer is the cheapest to describe and the easiest to overlook.
Every Mintlify-hosted docs site automatically generates a set of agent-readable artifacts at the root: llms.txt, llms-full.txt, and skill.md. The first two are an emerging convention for telling LLMs what content lives on a site and giving them a parseable bulk dump. The third is more interesting. As Mintlify describes it, skill.md is the action-layer manifest — it enumerates not just what the documentation contains but what an agent can actually invoke against the product, with required inputs and operating constraints attached to each capability. It is, in other words, the difference between an agent that can find information and an agent that can take action. Mintlify also exposes the /.well-known/agent-skills and /.well-known/skills paths — so any agent that knows the convention can find capabilities without hard-coded paths.
The unification trick that ties everything together is content negotiation. The same URL serves rich HTML to browsers and clean Markdown to agents — appending .md to any page URL returns a Markdown view of the same content, with no separate agent-facing site to maintain. This avoids the failure mode where teams maintain a “human site” and a separate “AI site” that drift out of sync; there is only one content store, with two rendering targets selected by the request.
Finally, every Mintlify site auto-hosts an MCP server, which lets coding agents like Cursor, Claude Code, and Windsurf query current documentation while a task is running. Authentication is supported when the docs site itself is gated — the MCP server respects whatever auth protocol the docs already use. The architectural significance is that retrieval is no longer something only the docs site itself can do. Every external agent that supports MCP gets a structured handle into your corpus, on the same terms as Mintlify’s own assistant.
What the architecture teaches
A few patterns are general enough to lift out of Mintlify’s specific case and apply elsewhere.
First, the sandbox is the unit of work for write tasks, but the wrong unit for read tasks. Most builders default to one or the other. Mintlify’s own bill clarifies the trade-off: a sandbox that boots in tens of seconds and costs a fraction of a cent per session is fine for asynchronous PR drafting, and ruinous for a chat widget. If you’re building both surfaces, expect to want both harnesses.
Second, version-controlled, natural-language instructions are the right encoding for agent behavior. Workflows YAML and AGENTS.md are the same idea applied at different scopes — one configures a recurring task, the other configures the agent globally. Both live in the repo, both go through code review, both evolve with the project. This is what “config as code” looks like when the configured component is a model.
Third, virtualizing the agent’s interface, not its environment, is often the better move. ChromaFs is the cleanest example: a real grep, a real ls, a real cat — but resolved against a database, not a disk. The agent doesn’t need a sandbox, it needs the sandbox’s API. Once you internalize that, a lot of “we need a Daytona for this” becomes “we need an IFileSystem shim for this,” with two orders of magnitude less infrastructure.
Fourth, content negotiation is the right unification primitive when you’re serving humans and agents from the same corpus. Maintaining parallel “human docs” and “AI docs” is how you guarantee they drift. Same URL, different format, selected by the request — and the cost of supporting the agent surface drops to near-zero.
Finally, harnesses are not edge cases, they’re the product. If you remove ChromaFs from the read assistant, the bill blows up. If you remove the sandbox boundary from the write agent, you stop being able to safely run on customer codebases. If you remove the auto-generated llms.txt and MCP server, the 45.3% of agent traffic loses its grip on the corpus. The model is doing model work in the middle, but everything around it — the sandbox, the virtual filesystem, the YAML triggers, the public surface — is what makes the product trustworthy and economical.
What to do with this
Three concrete moves for practitioners building anything adjacent to this space.
If you operate a documentation site, run it through Mintlify’s free Agent Score tool, which checks twenty-nine signals of agent-readability and tells you where the gaps are. The data is right there: half your traffic is agents you cannot see, and most teams are still building only for browsers. If you’d rather audit on your own, start by checking whether curl -L https://yourdocs.com/some-page.md returns clean Markdown or a 404 — that one HTTP request tells you whether you’re on the agent map at all.
If you’re building any agent that needs to read or modify a code repository, start with the harness, not the prompt. Decide your latency budget before you decide your model. If the answer is “tens of seconds and the agent edits files,” the Mintlify write agent — sandbox, headless OpenCode, version-controlled config — is your reference. If the answer is “milliseconds and the agent only reads,” the ChromaFs pattern (virtualize the interface, not the environment) is your reference.
And if you’re shipping a product that other agents will need to understand — an API, an SDK, a developer tool — treat your documentation as a programmatic interface that happens to also be human-readable. Auto-generate llms.txt and skill.md, expose an MCP server, serve clean Markdown via content negotiation. The asymmetric world Mintlify is betting on already exists. The teams whose docs are agent-readable get evaluated. The teams whose docs aren’t get skipped.