

Model Bills Are the New Headcount
Inference costs are replacing salaries as the fastest-growing line item at AI startups. Nobody has a discipline for managing them. That’s about to change.

TL:DR - At a growing number of AI startups, the monthly model inference bill has surpassed individual engineer salaries as the most scrutinized cost on the P&L. This isn’t a temporary artifact of early adoption — it’s the permanent economic structure of AI-native businesses. Yet most teams manage inference costs the way early startups managed cloud bills: reactively, after the damage is done. The emerging discipline of Model Reliability Engineering (MRE) treats model behavior and model cost as two sides of the same operational problem, giving teams a framework to monitor, optimize, and control inference economics alongside output quality. If your model bill is growing faster than your revenue, you don’t have a pricing problem — you have an engineering problem.
The New P&L
In 2024, when founders discussed their burn rate, the conversation was almost entirely about payroll. “We’re a team of twelve, burning $180K per month.” The model API line item — if it existed at all — was a rounding error. A few hundred dollars for prototyping.
In 2026, that conversation has inverted at AI-native companies. A team of four might burn $50K per month on salaries and $25K–$40K per month on inference. The model bill isn’t a rounding error — it’s the second-largest expense after payroll, and at some companies, it’s approaching the first.
This creates a cost structure that’s fundamentally different from traditional software businesses in three ways.
First, the marginal cost of serving a customer is non-trivial. In traditional SaaS, the marginal cost of an additional user is essentially zero — server costs are negligible per user. In AI-native products, every user interaction triggers model inference that costs real money. A complex query might cost $0.05–$0.50 in model calls. At scale, this adds up fast.
Second, costs are partially unpredictable. Traditional infrastructure scales predictably — you know roughly what a new server instance costs. Model costs depend on input complexity, output length, which model handles the request, retry rates, and dozens of other factors that vary by user and use case.
Third, cost and quality are directly coupled. In traditional software, you can usually cut costs without affecting user experience — optimize a query, compress an asset, cache a result. In AI systems, cheaper often means worse. Routing to a smaller model saves money but may degrade output quality. Shorter prompts cost less but may produce less reliable results. Every cost optimization decision is simultaneously a quality decision.
Why Cloud-Era Thinking Doesn’t Work
Most engineering teams default to treating model costs the way they treat cloud infrastructure costs. Set up billing alerts, review the dashboard monthly, optimize the biggest spenders when the bill gets uncomfortable.
This approach fails for AI inference because it addresses the wrong problem. Cloud cost optimization is primarily about resource utilization — right-sizing instances, eliminating waste, reserving capacity. The decisions are mostly independent of the product’s behavior.
Inference cost optimization is inseparable from product behavior. When you change how a model is called — the prompt, the model choice, the context window size — you change both the cost and the output. You can’t optimize one without affecting the other. An engineer who reduces inference costs by 40% but degrades response quality by 20% hasn’t saved money — they’ve broken the product.
This coupling is why inference economics requires its own discipline, not just a tab in your existing monitoring dashboard.
Enter Model Reliability Engineering
Model Reliability Engineering (MRE) is an engineering discipline that owns model behavior reliability in production — and inference economics is one of its core concerns.
MRE sits at the intersection of several existing disciplines. Site Reliability Engineering (SRE) gives it operational rigor — uptime targets, incident response, monitoring. MLOps gives it the deployment and pipeline perspective. AI Safety gives it the behavioral constraint framework. But none of these disciplines adequately cover the specific problem of maintaining reliable model behavior at manageable cost in production systems.
MRE addresses this through a two-layer architecture: Context Engineering (designing and managing what goes into the model) and Harness Engineering (building the infrastructure that wraps, monitors, and controls model interactions). Together, they form a framework for thinking about inference costs as an engineering problem, not a finance problem.
The MRE approach to inference economics centers on five operational concerns:
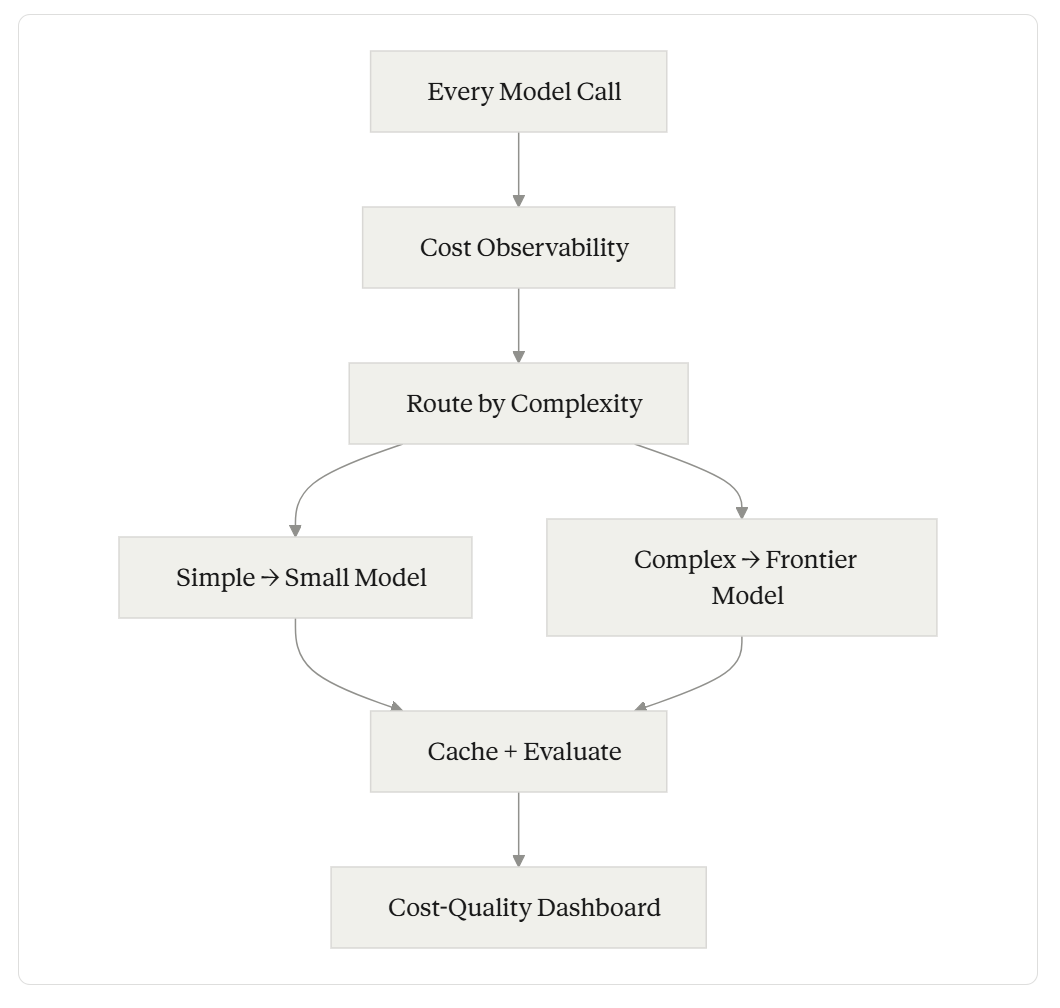
1. Cost Observability
You can’t optimize what you can’t see. Most teams track their aggregate model bill — total spend per month. That’s like tracking your total cloud bill without knowing which service consumes the most. Useless for optimization.
Effective cost observability means tracking cost per request, segmented by model, feature, user tier, and request complexity. It means knowing that your document summarization feature costs $0.12 per request while your chatbot costs $0.03 per request — and understanding why.
The implementation is straightforward: instrument every model call with metadata (feature name, model used, input tokens, output tokens, latency) and aggregate it in a monitoring system. The hard part is building the organizational habit of reviewing this data with the same rigor you’d review error rates or latency percentiles.
2. Model Routing
Not every task requires the same model. A classification decision — “is this email spam or not?” — can be handled by a small, fast, cheap model. A complex reasoning task — “analyze this legal document and identify liability risks” — requires a frontier model.
Model routing is the practice of sending each request to the most cost-effective model that can handle it at the required quality level. In practice, this means defining quality thresholds for each task type, benchmarking multiple models against those thresholds, building a routing layer that selects the appropriate model per request, and continuously evaluating whether routing decisions are still optimal as models evolve.
Teams that implement routing consistently report 40–60% reductions in inference costs. It’s the single highest-leverage optimization available, and most teams haven’t done it because it requires evaluation infrastructure they don’t have.
3. Prompt Economics
Prompt length directly affects cost — more input tokens means higher cost per request. But prompt optimization for cost can’t be done in isolation from quality.
The MRE approach treats prompts as economic artifacts. Every prompt has a cost (measured in tokens) and a quality level (measured by evaluation). The goal is to find the minimum-cost prompt that meets the quality threshold — not the cheapest prompt possible, and not the longest prompt that maximizes quality.
This requires evaluation infrastructure: a way to systematically test prompt variations against quality metrics and cost metrics simultaneously. Without evaluation, prompt optimization is guesswork. With evaluation, it’s engineering.
4. Caching and Deduplication
Many production workloads involve repeated or near-identical requests. Semantic caching — returning cached results for requests that are similar enough to previous ones — can significantly reduce inference costs without affecting user experience.
The engineering challenge is defining “similar enough.” Exact-match caching is trivial but catches few cases. Semantic similarity caching (using embedding distance to find near-matches) catches more cases but introduces a quality risk: the cached response might not be appropriate for the new request.
The MRE framework treats caching as a reliability decision, not just a performance optimization. Every cache hit is an assertion that the cached response is good enough for the new request. That assertion needs validation.
5. Budget Governance
As inference costs become a material portion of company spend, they need governance mechanisms similar to other significant cost centers.
This means per-feature cost budgets (this feature should cost no more than $X per month), cost-per-request limits (if a single request exceeds $Y, flag it for review), trend alerting (if costs are growing faster than usage, investigate), and cost-quality tradeoff documentation (recording why each routing or prompt decision was made).
Budget governance sounds bureaucratic, but without it, inference costs grow unchecked until they trigger a crisis.
The Cost-Quality Tradeoff in Practice
Here’s a concrete example of how MRE thinking changes inference economics.
Consider a customer support AI that handles 10,000 requests per day. Without optimization, every request goes to a frontier model with a long system prompt. Cost: roughly $0.15 per request. Monthly bill: $45,000.
An MRE approach would look like this:
Step 1 — Classify requests by complexity. Analysis reveals that 60% of requests are simple FAQ-type questions, 30% are moderately complex, and 10% require deep reasoning.
Step 2 — Build a routing layer. Simple requests go to a small model ($0.01/request). Moderate requests go to a mid-tier model ($0.05/request). Complex requests go to the frontier model ($0.15/request).
Step 3 — Optimize prompts per tier. The simple model gets a short, focused prompt. The mid-tier model gets a moderate prompt with examples. The frontier model gets the full system prompt.
Step 4 — Add semantic caching for the simple tier, where many requests are near-identical.
Result: Simple requests (6,000/day × $0.008 with caching) = $48/day. Moderate requests (3,000/day × $0.05) = $150/day. Complex requests (1,000/day × $0.15) = $150/day. Total: $348/day. Monthly bill: roughly $10,400.
That’s a 77% cost reduction. But it only works because each step was validated against quality metrics. The small model’s responses to simple queries were evaluated and confirmed to meet quality thresholds. The routing classifier was tested for accuracy. The caching system was validated against semantic similarity scores.
Without evaluation infrastructure, you’re just guessing about where to cut. With it, you’re engineering.
Who Owns This?
At most companies today, nobody owns inference economics. The engineering team builds features. The finance team pays the bills. Nobody connects the two systematically.
MRE argues that inference economics is an engineering responsibility — specifically, it’s the responsibility of whoever owns model behavior in production. The person who decides which model to use, how to prompt it, and how to evaluate the output is also the person best positioned to optimize the cost, because they understand the cost-quality tradeoff for each decision.
This doesn’t mean every engineer needs to become a financial analyst. It means the team responsible for model interactions needs cost visibility, cost targets, and the tools to optimize against them. Just as SRE teams own uptime targets, MRE teams own cost-quality targets.
For teams without dedicated MRE roles (which is most teams right now), the minimum viable version is: instrument every model call, review costs weekly by feature, and set per-feature cost budgets. That alone puts you ahead of 90% of teams managing inference costs today.
The Compounding Problem
Here’s why this matters now and not later: inference costs compound with growth. Unlike traditional infrastructure costs that grow sub-linearly with scale (thanks to efficiency gains), inference costs grow roughly linearly — and sometimes super-linearly when complex features get more usage.
A startup spending $25K/month on inference at 1,000 users will likely spend $250K/month at 10,000 users unless they actively optimize. At 100,000 users, the unoptimized bill would approach a $3M annual run rate — on inference alone.
Cost Observability with AI
Every month you delay implementing cost observability, routing, and evaluation is a month where cost inefficiencies compound into your growth trajectory. The startups that survive the transition from early traction to real scale will be the ones that treated inference economics as a first-class engineering discipline from the beginning, not the ones that panicked when the bill arrived.