

Model Reliability Engineering: Who Owns It When the AI Is Confidently Wrong?
Teams know their AI can be wrong. What's missing is the engineering discipline to make it reliably right.

TL;DR: Companies deploying LLMs in production are discovering a reliability gap that none of the existing engineering disciplines — SRE, MLOps, AI Safety — are designed to close. Infrastructure stays up. Pipelines keep running. Models keep generating. But the outputs users depend on can be wrong, inconsistent, or unsafe, and no team owns that problem. What’s emerging to fill this gap is something that might be called Model Reliability Engineering (MRE) — the practice of ensuring that AI model behavior is reliable in production, not just the infrastructure underneath it. This piece maps the gap, explains why it exists now and didn’t before, and sketches the shape of the discipline forming around it. The framework is early and evolving — the goal here is to start a conversation, not finish one.
Model Reliability Engineering
Something Is Missing
A healthcare system deploys an AI assistant to help clinicians review patient records and surface relevant clinical guidelines. The infrastructure team runs it on managed Kubernetes with auto-scaling. The ML platform team built a solid RAG pipeline with nightly document ingestion. The system passes load testing. The SRE dashboard is green across every metric.
A nurse practitioner asks: “What’s the recommended dosing adjustment for metformin in patients with reduced renal function?” The system retrieves a clinical guideline, passes it to the model, and generates a clear, confident answer with a specific dosage recommendation. The recommendation is subtly wrong — the model extracted a dosage figure from a retrieved passage but missed that the passage described a contraindicated scenario, not a recommended one. The qualifying context was in the previous chunk, which didn’t make the top-K retrieval cutoff.
The error isn’t caught. No alarm fires. The system’s correctness monitoring consists of a thumbs-up/thumbs-down button that fewer than 3% of users click. The next time anyone knows something went wrong is when a pharmacist catches the discrepancy during medication review — days later.
This isn’t a hypothetical. Variants of this failure pattern play out across every industry deploying LLMs in production:
In financial services, a compliance assistant retrieves an outdated regulatory interpretation and generates advice based on a rule that was superseded six months ago. The retrieval pipeline ran perfectly. The document was in the corpus — it just shouldn’t have been, or should have been flagged as superseded. No existing monitoring caught it because “the model returned a well-formed answer from a successfully retrieved document” looks like success to every metric being tracked.
In legal, a contract review tool summarizes a liability clause but drops a carve-out exception that fundamentally changes the clause’s meaning. The LLM’s summary is grammatically perfect, tonally appropriate, and 80% accurate. The missing 20% is the part that matters. The tool’s evaluation framework tests for “is the summary relevant to the clause?” but not “does the summary preserve all material qualifications?”
In enterprise knowledge management, an internal Q&A system answers “What’s our policy on remote work eligibility?” by combining fragments from three different policy documents — a 2022 version, a 2023 update, and an FAQ that was drafted but never approved. The answer reads coherently but reflects a policy that never existed. Each source was individually legitimate. The synthesis was not.
In every case, infrastructure reliability was excellent. Pipeline reliability was excellent. The model performed exactly as designed — it generated fluent, confident text based on the context it received. The failure was in a layer that no existing discipline is structured to monitor: the reliability of the model’s behavior as experienced by the user.
Why This Gap Exists Now
This isn’t a problem that people have been ignoring. It’s a problem that didn’t fully exist until recently. Three shifts created it.
Shift 1: From prediction to generation
Traditional ML in production outputs predictions: a classification, a score, a probability. A fraud detection model returns 0.87. A recommendation engine ranks items. These outputs are narrow, measurable, and directly testable against ground truth. You can compute precision, recall, F1, and AUC on every production prediction and track them in real time.
LLMs produce open-ended text. The output space is effectively infinite. Two correct answers to the same question can be worded completely differently. A wrong answer can be syntactically identical to a right one except for a single word. Traditional ML monitoring — tracking prediction distributions, feature drift, data quality — doesn’t tell you whether a generated paragraph is true. This is fundamentally different from anything software reliability or ML monitoring was designed to handle.
Shift 2: From self-contained models to compound systems
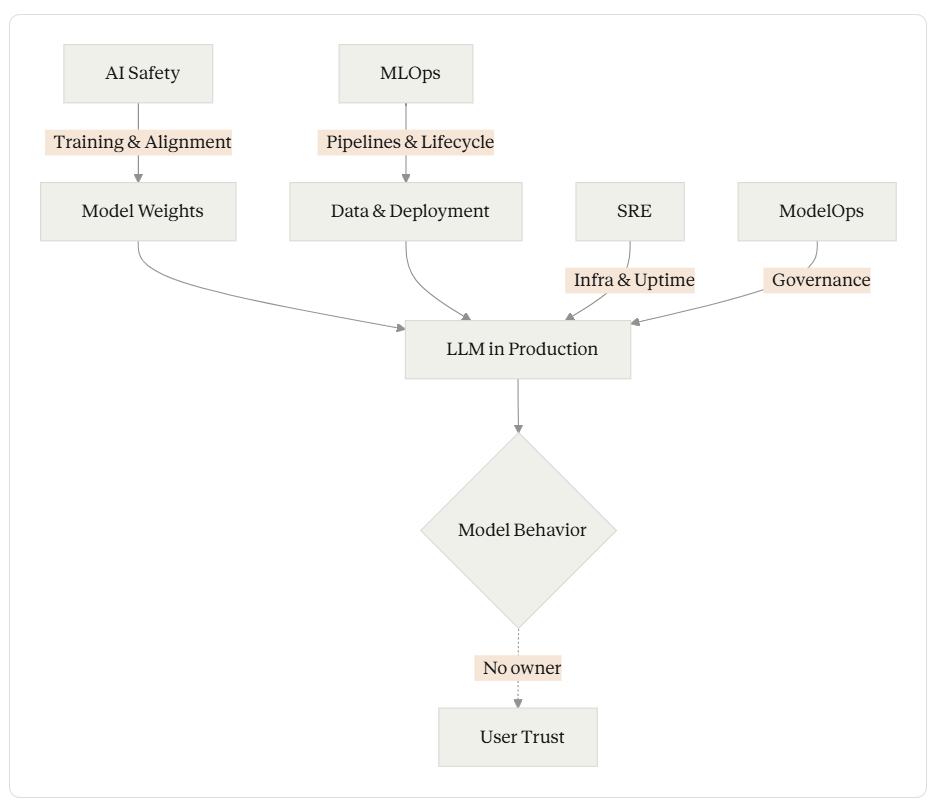
A traditional ML model is a single artifact: data goes in, prediction comes out. Its reliability surface is the model itself plus its input pipeline.
An LLM in production is a compound system — the term Berkeley researchers used in early 2024. It’s a model wrapped in a retrieval pipeline, a prompt template, a set of guardrails, possibly tool-calling infrastructure, memory, re-ranking, citation logic, and output formatting. The model is one component among many. A failure in any component degrades the final output, and the failure modes are combinatorial. Bad chunking + good retrieval + good generation = wrong answer. Good chunking + good retrieval + bad extraction = wrong answer. Good everything + stale source document = wrong answer.
No single component owner sees the full picture. The retrieval team sees retrieval metrics. The model provider sees generation metrics. The infrastructure team sees latency and throughput. Nobody sees “the user got a wrong answer because of an interaction between retrieval ranking and chunk boundary placement,” because that’s not any one team’s metric.
Shift 3: From technical users to everyone
When ML models served data scientists and internal analytics teams, a slightly wrong output was caught and corrected by experts who understood the model’s limitations. When LLMs serve nurses, compliance officers, customer support agents, and end consumers, the user often lacks the domain expertise to recognize when the model is wrong — especially when the model’s errors are articulate, confident, and well-structured.
The consequence of this shift: model behavior reliability is no longer a nice-to-have quality attribute. It’s a safety property. And unlike traditional safety properties in software, it can’t be addressed through static analysis, type checking, or deterministic testing. It requires continuous, probabilistic monitoring of outputs that are non-deterministic by nature.
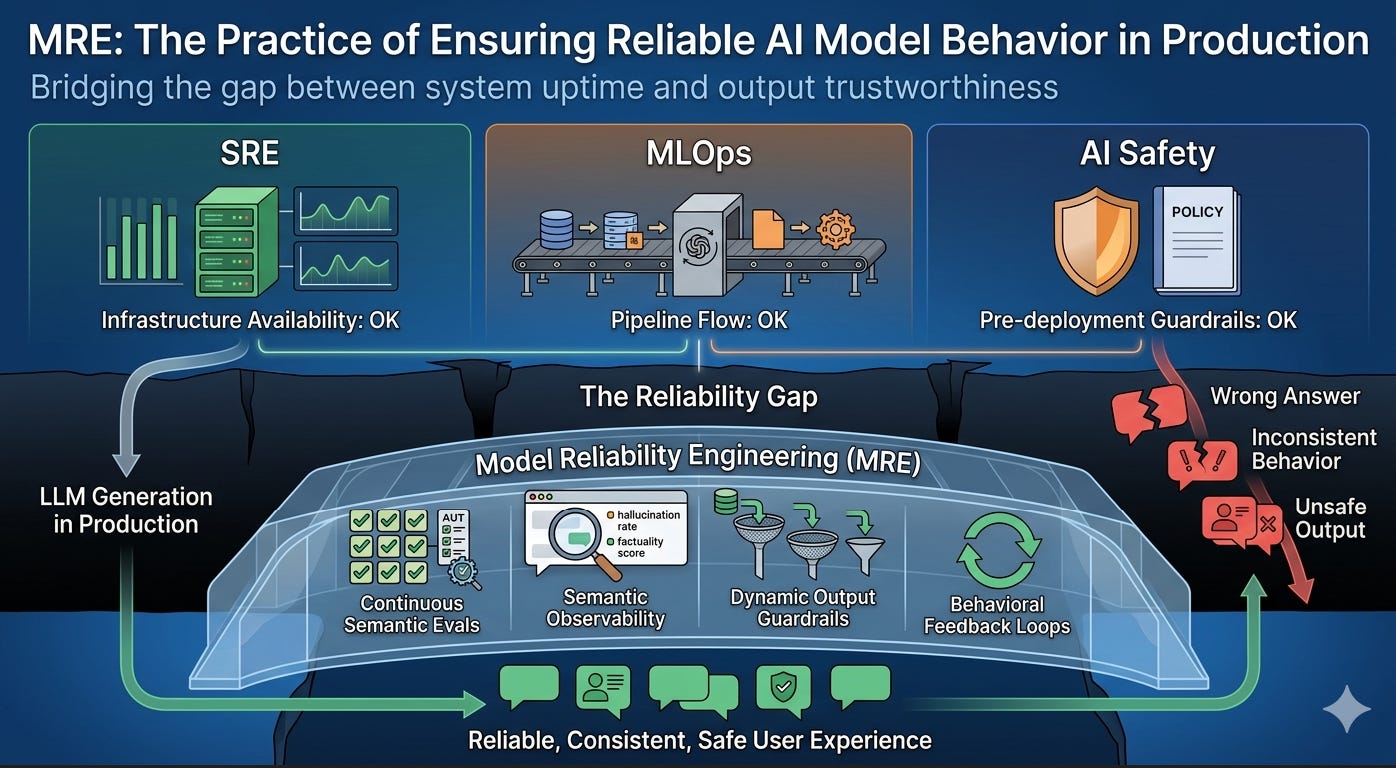
What Existing Disciplines Cover — and What They Don’t
It’s worth being precise about why existing practices don’t close this gap. Not because they’re insufficient at what they do, but because none of them are scoped to cover model behavior reliability.
Site Reliability Engineering operates at the infrastructure layer. SRE’s tools — SLOs, error budgets, incident response, capacity planning — are designed for systems with deterministic or statistically predictable behavior. A web server either returns the right page or an error code. An SRE can define “success” as a 200 response within 300ms. For an LLM, a 200 response within 300ms tells you nothing about whether the content of that response is reliable. Todd Underwood, who built ML SRE at Google and later led reliability teams at OpenAI and Anthropic, has written directly about this: infrastructure failures in ML systems manifest as quality problems, and SRE’s monitoring isn’t designed to distinguish “the system returned an error” from “the system returned a confident wrong answer.” SRE monitors the vehicle. It doesn’t know if the vehicle is driving to the right destination.
MLOps operates at the pipeline and lifecycle layer. MLOps ensures models get from development to production, stay updated, and remain monitored for data and distribution drift. These are necessary functions. But MLOps drift detection typically tracks input distributions, feature statistics, and prediction distribution shifts — not whether individual outputs are correct, faithful to sources, or safe in context. MLOps monitors the assembly line. It doesn’t inspect what’s coming off the end of it.
AI Safety operates at the training and alignment layer. AI safety research produces the techniques — RLHF, constitutional AI, red-teaming — that make foundation models safer before deployment. For practitioners deploying models they didn’t train, in applications the model provider didn’t anticipate, AI safety provides crucial principles but not an operational engineering practice. A model can be aligned at training time and still produce unreliable outputs in a specific deployment context because of retrieval failures, prompt interactions, or domain-specific edge cases the training process never encountered. AI safety establishes the building code. It doesn’t do the home inspection.
ModelOps operates at the governance layer. ModelOps tracks which models are deployed where, who approved them, and whether they comply with organizational policies. It’s necessary for enterprise governance. It doesn’t monitor whether the model’s Tuesday afternoon output to a specific user was correct.
Existing Disciplines
The gap between these disciplines isn’t narrow. It’s the entire layer that users experience.
The Shape of What’s Emerging
Across organizations deploying LLMs seriously, a set of practices is forming to address this gap. Different teams call it different things — “LLM quality engineering,” “AI output monitoring,” “model behavior testing” — or don’t name it at all, just bolt it onto existing SRE or MLOps responsibilities. But the practices converge. What’s emerging has a recognizable shape, and giving it a name might help the community develop it faster.
The term that seems to fit is Model Reliability Engineering (MRE) — the practice of ensuring that AI model behavior is reliable in production. Not infrastructure uptime. Not pipeline health. The actual outputs the system produces.
MRE focuses on a simple question that turns out to be operationally complex: does the model’s output deserve the user’s trust, right now, for this query?
The practices forming around this question tend to organize along two layers.
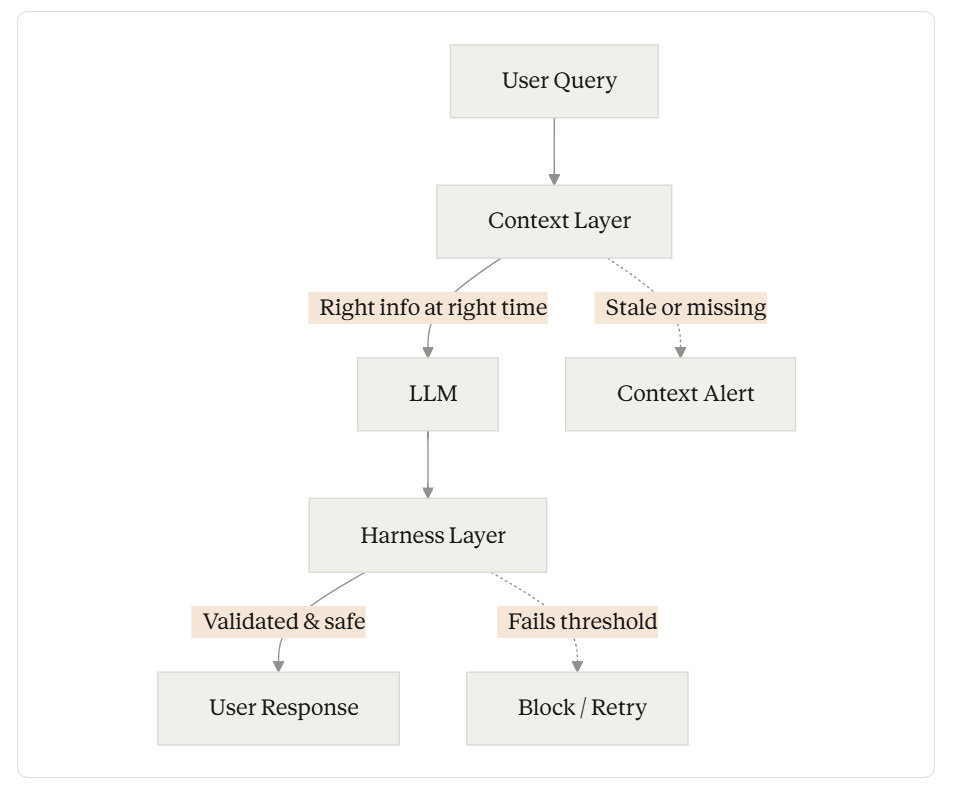
The Context Layer
Every production LLM system has to solve the problem of getting the right information to the model at the right time. The methods span a wide spectrum — from static knowledge baked into model weights through fine-tuning, to dynamic retrieval from external sources, to real-time tool use and agentic research. Each method has a different reliability profile.
RAG systems can fail through stale indexes, bad chunking, missed retrieval, or context overload. Fine-tuned models can fail through knowledge staleness or catastrophic forgetting. Long-context approaches can fail through attention drift and the well-documented “lost in the middle” effect. Tool-calling systems can fail through API errors, schema mismatches, or the model misinterpreting returned data.
What’s emerging is the recognition that context is a reliability surface. It can be monitored, measured, and held to standards the same way infrastructure performance can. Retrieval precision isn’t just a search quality metric — it’s a leading indicator of output reliability. Context freshness isn’t just a data management concern — it’s a behavioral SLO. Source authority scoring, chunk boundary analysis, multi-source corroboration — these are reliability practices for the context layer, and teams are beginning to treat them that way.
The Harness Layer
Between the model’s raw output and what the user sees sits a control layer — the guardrails, evaluators, validators, safety filters, and orchestration logic that constrain and verify model behavior. This layer is where reliability is enforced.
In practice, this includes faithfulness scoring (does the output contradict its source context?), citation verification (do cited sources actually support the claims?), confidence calibration (does the system communicate uncertainty when it should?), output validation gates (does the response meet formatting, safety, and quality thresholds before serving?), graceful degradation (does the system fail safely when context is insufficient?), and permission-aware filtering (does retrieval respect access controls?).
In the Claude Code ecosystem, practitioners are already building harness components intuitively — CLAUDE.md files that establish behavioral constraints, hooks that enforce validation at lifecycle events, skills that encode domain-specific guardrails, subagents that verify outputs. What hasn’t happened yet is treating these as components of a reliability discipline with measurable SLOs.
Two evolving layers
The two layers are complementary. Context without harness gives the model the right information but no way to catch when it uses that information wrong. Harness without context constrains a model that’s working with bad information to begin with. Reliable model behavior requires both.
What Behavioral SLOs Look Like
The most concrete contribution MRE makes is extending the SLO concept from infrastructure to model behavior. This isn’t fully developed yet — the right metrics and thresholds are still being discovered in practice — but the emerging shape looks something like this:
Correctness rate — the percentage of outputs that are factually accurate against source material. This requires automated evaluation plus regular human calibration, because purely automated scoring drifts. A team might set a 90% correctness SLO, with the understanding that measuring it is harder than measuring uptime and that the metric itself will evolve.
Faithfulness — how often the model’s response stays grounded in its provided context versus fabricating beyond it. RAGAS, TruLens, and similar tools provide automated scoring here. A faithfulness SLO sets a floor: below this threshold, the system is considered unreliable for its use case.
Abstention accuracy — how often the model correctly identifies when it lacks sufficient information to answer, rather than fabricating a plausible response. This is arguably the most important behavioral SLO for high-stakes applications. A system that says “I don’t have enough information to answer this reliably” when it genuinely doesn’t is more reliable than a system that always produces an answer.
Consistency — given the same question and context, how stable are the model’s answers across repeated queries? Non-determinism is inherent in LLMs, but the factual content of answers to the same question should be stable even if the wording varies. Inconsistency often indicates that the model is uncertain and resolving that uncertainty differently on each pass.
Safety compliance — the rate at which outputs pass content safety, policy compliance, and domain-specific filters. What constitutes “safety” is domain-dependent: a medical system has different safety thresholds than a creative writing assistant.
These aren’t meant as a definitive list. They’re the SLOs that keep showing up across teams doing this work. The right behavioral SLOs for a specific system depend on the domain, the risk tolerance, and the user population. What matters is that they exist at all — that model behavior is treated as a measurable, monitorable dimension with explicit quality targets.
Incident Response for Model Behavior
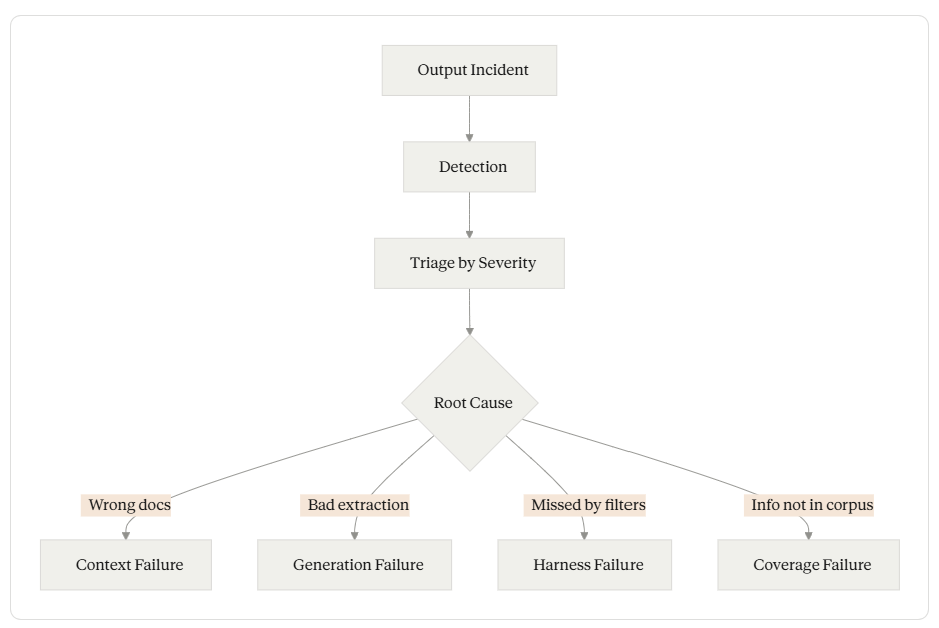
One of the clearest signs that a reliability gap exists is looking at how organizations handle model misbehavior today. When infrastructure goes down, SRE has a well-defined incident response practice: detection, triage, response, postmortem, prevention. When a model generates a harmful or incorrect output, most organizations have... nothing. A user complains. Someone files a ticket. Eventually, someone looks at the logs. Maybe the prompt gets tweaked.
The same rigor can be applied to model behavior:
Detection should be automated. Faithfulness scoring, retrieval quality monitoring, and adversarial probing should catch behavioral degradation before users do. A drop in faithfulness scores below the SLO threshold is an incident — not a metric to review next sprint.
Triage matters because not all model failures are equal. A hallucination in a casual Q&A session has different severity than a hallucination in a compliance response. Incident classification needs domain-specific severity frameworks.
Postmortems should be blameless and systemic. Why did the model produce this output? Was it a context failure (wrong documents retrieved), a generation failure (model misinterpreted correct context), a harness failure (validation should have caught this but didn’t), or a coverage failure (the knowledge base lacked the needed information)? Each root cause points to a different remediation.
Incident Response for Model behaviour
Error budgets are the mechanism that makes behavioral SLOs operational rather than aspirational. If your correctness SLO is 92% and you’ve burned through your error budget this month, the team shifts from building new features to improving reliability — the same trade-off SRE pioneered for infrastructure.
RAG as the Primary Proving Ground
If this discipline needs a place to prove its value, RAG is it. RAG is the most widely deployed LLM architecture in production, and it’s where model behavior reliability challenges are most visible and most painful.
RAG systems have at least ten well-documented failure modes, cataloged by Barnett et al. (2024) and expanded significantly by production experience since. Every one of them is a model behavior reliability problem that doesn’t appear on an infrastructure dashboard: stale retrievals, bad chunking, missed context, context overload and the “lost in the middle” effect, unfaithful extraction, security leaks through retrieval, embedding drift, retrieval-generation timing failures, scattered evidence synthesis failures, and the model answering when it should abstain.
The evolution of RAG architectures — from naive single-shot retrieval through advanced hybrid retrieval, self-correcting RAG (Self-RAG, Corrective RAG), and now agentic RAG with autonomous retrieval planning — can itself be understood as an evolution toward greater model behavior reliability. Each generation added mechanisms to detect and recover from failure modes the previous generation couldn’t handle. Self-RAG taught models to judge whether they need to retrieve at all. Corrective RAG added evaluators that score document relevance before generation. Agentic RAG introduced multi-step planning, self-correction loops, and dynamic tool selection.
These advances happened organically, driven by practitioners hitting reliability walls. A model reliability framework provides a way to understand where on the reliability spectrum a system sits and what needs to happen to improve it — turning ad-hoc iteration into systematic engineering.
How This Relates to What Exists
MRE isn’t replacing anything. It’s filling a gap between things that already exist and work well at what they do.
The relationship to SRE is generational. SRE was created because software systems became too complex for traditional operations practices. This discipline is forming because AI systems are too complex for traditional software reliability practices. SRE’s operational philosophy — SLOs, error budgets, blameless postmortems, the principle that reliability is a feature — transfers directly. What changes is the object of measurement: from system behavior (latency, availability, error rates) to model behavior (correctness, faithfulness, appropriate abstention).
The relationship to MLOps is complementary. MLOps handles the lifecycle — getting models from development to production and keeping them updated. Model behavior reliability handles the runtime — ensuring that what the model does in production meets quality standards. A mature AI organization needs both, the same way a mature software organization needs both CI/CD and production monitoring.
The relationship to AI Safety is layered. AI safety establishes the foundation: models that are aligned, harmless, and honest at training time. Model behavior reliability builds on that foundation for specific deployment contexts: ensuring that a generally safe model behaves reliably in this application, with this data, for these users. A model can be well-aligned and still produce unreliable outputs when deployed in a context its training didn’t anticipate.
What’s Still Unknown
Honesty requires acknowledging what isn’t figured out yet. This discipline is early. Several hard problems remain open:
Measuring correctness at scale is hard. Unlike infrastructure metrics that can be computed from logs, output correctness often requires domain expertise to evaluate. Automated faithfulness scoring is getting better (RAGAS, TruLens, LLM-as-judge approaches), but these tools measure consistency with context, not truth. A model that faithfully reproduces information from a wrong document scores high on faithfulness and low on correctness. Bridging this gap requires human calibration, golden datasets, and evaluation frameworks that aren’t mature yet.
Setting the right thresholds is domain-specific. What correctness rate is acceptable? 95% for a customer support bot might be fine. 95% for a medical decision support system might be catastrophic. The thresholds need to come from domain expertise and risk analysis, not from engineering defaults. The framework can provide the structure, but it can’t prescribe universal thresholds.
Non-determinism complicates everything. LLMs are inherently probabilistic. The same input can produce different outputs on consecutive calls. This makes behavioral SLOs fundamentally different from infrastructure SLOs, where the same request should always produce the same response. Model reliability has to reason about distributions of behavior, not individual outputs — and the statistical tools for this are still developing.
The boundary with prompt engineering is fuzzy. Is improving a system prompt to reduce hallucinations a reliability activity or a development activity? Probably both, depending on context. The discipline’s boundaries will sharpen through practice, not through definitional fiat.
The tooling is immature. The evaluation tools that exist — RAGAS, TruLens, custom LLM-as-judge pipelines — are first-generation. They work but require significant integration effort, produce metrics that need calibration, and don’t yet connect to the kind of operational dashboards that SRE teams take for granted. This will improve, but it’s a real limitation right now.
These unknowns aren’t reasons to wait. SRE had plenty of open questions in its early years too. The discipline formed through practice, with refinements accumulating as more teams adopted and adapted the core ideas. This will likely follow the same path.
An Invitation, Not a Manifesto
If this framing resonates, the most useful thing that can happen is for practitioners to pressure-test it against their own experience. The questions worth asking:
Does the gap described here match what you see in your organization? Is there a team or role that owns model behavior reliability, or does it fall between the cracks?
Are the two layers — context reliability and harness reliability — the right decomposition, or is there a third layer missing?
Which behavioral SLOs matter most in your domain, and how are you measuring them today (if at all)?
What failure modes have you encountered that don’t fit neatly into the categories described here?
The discipline will be shaped by the practitioners who adopt and adapt it, not by any single definition. What’s offered here is a starting point — a way to talk about a problem that many teams are experiencing but that doesn’t yet have a shared vocabulary. If naming it helps teams think more clearly about it, build better systems around it, and hold themselves to higher standards for what their AI systems deliver to users, then the name is doing its job.
The infrastructure reliability problem is largely solved. The model behavior reliability problem is wide open. This is how we start closing it.
References: Lewis et al. (2020), “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” Meta AI. Barnett et al. (2024), “Seven Failure Points When Engineering a RAG System.” Asai et al. (2024), “Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection,” ICLR 2024. Yan et al. (2024), “Corrective Retrieval Augmented Generation.” Chen, Murphy, Parisa, Sculley & Underwood (2022), “Reliable Machine Learning,” O’Reilly. Sculley et al. (2015), “Hidden Technical Debt in Machine Learning Systems,” NeurIPS. Singh et al. (2025), “A Survey on Agentic RAG.” Microsoft Research (2024), “GraphRAG.” Hummer & Muthusamy (2018), “ModelOps,” IBM Research.
Hey Kranthi — "teams know their AI can be wrong, what's missing is the engineering discipline to make it reliably right" is a sentence that should be printed on a card and handed to every team shipping an AI product. Everyone acknowledges the problem and almost nobody has a system for managing it.
The abstention accuracy metric is the one that jumps out at me. I build AI agents for businesses and the single most important thing I scope is "when does this agent say I don't know and hand off to a human." An agent that confidently makes up an answer to a question it shouldn't touch is worse than one that does nothing at all. Training the system to know its own edges is harder than training it to be good at its core task — and nobody budgets time for it.
The compound system failure point is real too. Once you've got an agent pulling from a knowledge base, calling APIs, reading emails, and generating responses — a bug in any link of that chain produces a confident wrong answer at the end. And the user has no idea which component failed because the output looks the same either way. That's where the "harness layer" concept earns its weight — you need checkpoints between components, not just evaluation at the end. Really practical framework. This one's going in my reference library.
The financial services compliance assistance example resonates totally. I wrote about the drift state in FS and more broadly too. Good read!