

OpenAI’s AI Deployment Playbook Is Missing a Chapter
Their whitepaper nails the org chart. It ignores the engineering discipline that determines whether AI products actually stay in production.

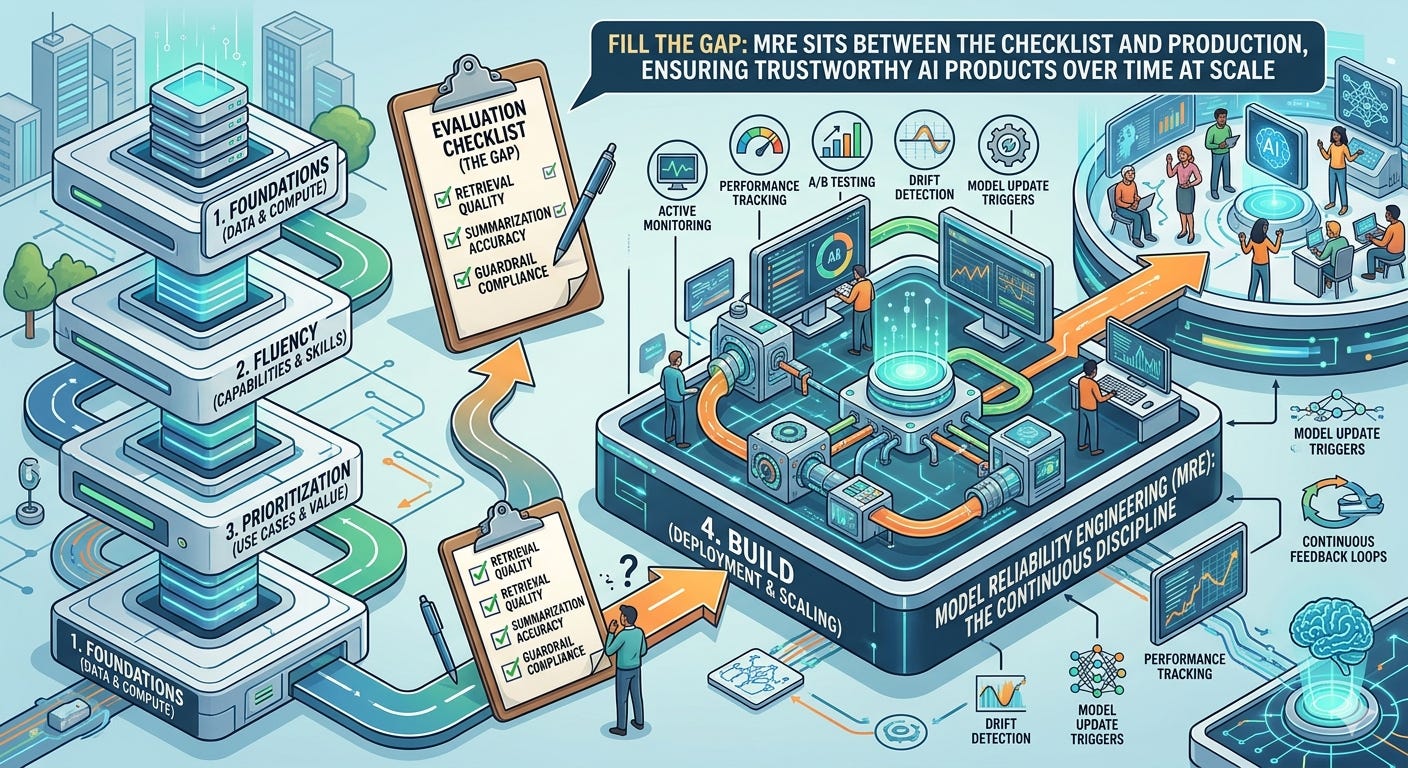
TL;DR: OpenAI’s “From Experiments to Deployments” whitepaper lays out a solid four-phase framework for scaling AI — foundations, fluency, prioritization, build. But Phase 4 reveals a critical gap: the whitepaper treats evaluation as a step in a checklist rather than a continuous engineering discipline. It describes what to measure (retrieval quality, summarization accuracy, guardrail compliance) without naming who owns it or how it operates at scale. That missing chapter is Model Reliability Engineering — the discipline that sits between the eval checklist and the production system that keeps your AI products trustworthy over time. If you’re an AI engineer reading OpenAI’s playbook, understand the organizational framework, but build MRE into your Phase 4 from day one.
The Whitepaper Gets a Lot Right
Credit where it’s earned. OpenAI’s whitepaper, published in late 2025, distills real lessons from enterprise partnerships with BBVA, Uber, Lowe’s, Booking.com, and others into a four-phase model for scaling AI:
Phase 1: Set the foundations — executive alignment, governance, data access. The “compliance fast path” example from Figma is particularly instructive: data guardrails that enable experimentation rather than blocking it.
Phase 2: Create AI fluency — literacy programs, champion networks, SME development. BBVA’s journey from 3,000 to 11,000 (and now 120,000) ChatGPT Enterprise licenses, powered by a distributed champion network, is the best public case study of this phase working at scale.
Phase 3: Scope and prioritize — repeatable intake processes, impact/effort scoring, reuse-first design. Standard portfolio management, adapted well for AI’s unique characteristics.
Phase 4: Build and scale products — cross-functional teams, incremental builds, gated checkpoints, continuous evaluation.
Phase 4 is where the whitepaper gets interesting — and where it stops too soon.
MRE in the mix
Where MRE Fills the Gap
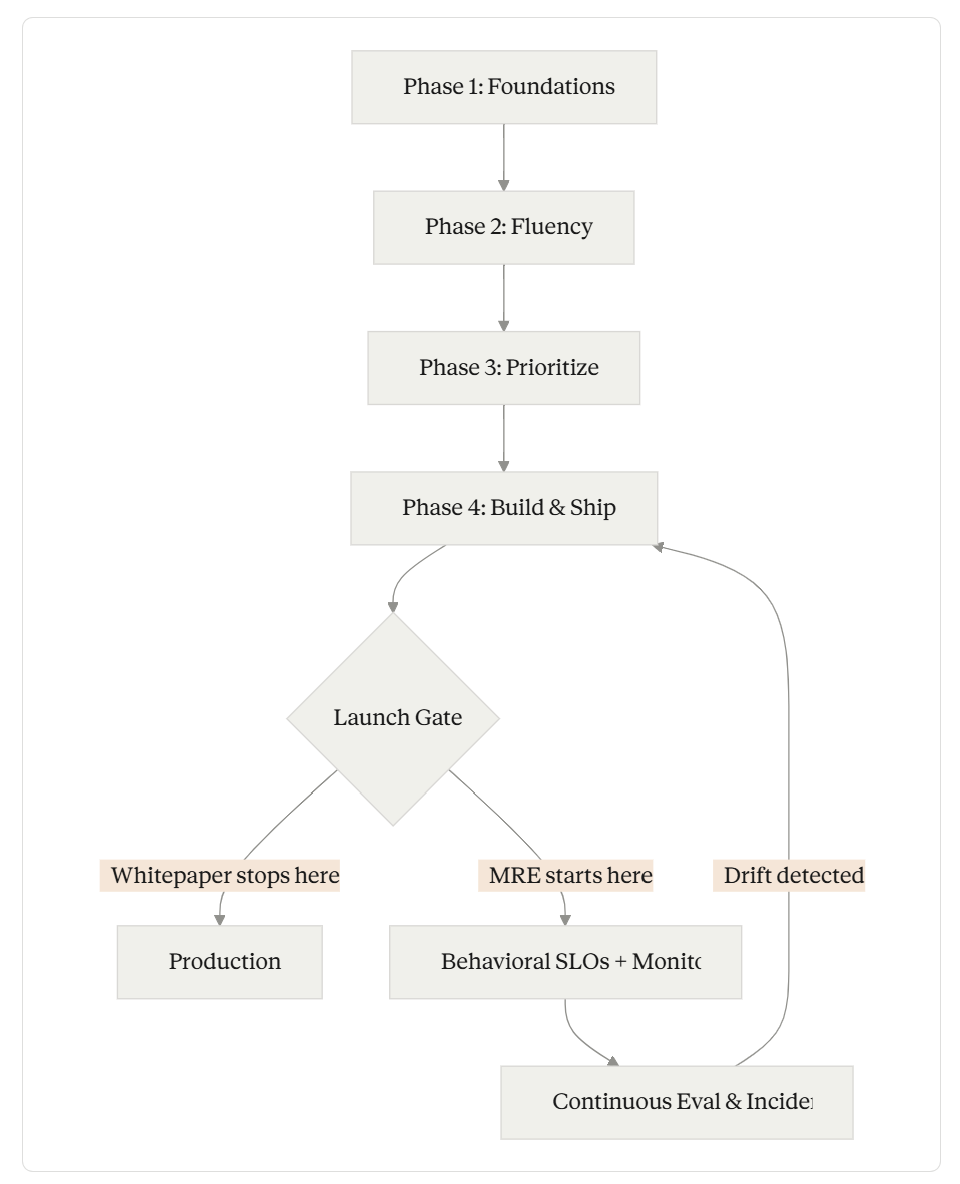
The whitepaper's four phases get you to the launch gate. MRE - Model Reliability Engineering is the operational discipline that keeps AI products reliable after deployment — monitoring behavioral SLOs, detecting drift, and feeding failures back into the build cycle.
The Gap in Phase 4
The whitepaper includes a table that traces a Q&A agent through three evaluation stages: retrieval (does it find the right information?), summarization and grounding (does it synthesize useful, cited answers?), and guardrails (does it stay within approved data, tone, and safety guidelines?). Each stage has a decision gate: continue, refine, or stop.
This is a good checklist. It is not an engineering discipline.
Here’s what the table doesn’t address:
Who owns these evaluations after launch? The whitepaper assigns “SME review” and “safety review” as activities, but never identifies a team or role responsible for ongoing behavioral monitoring. In traditional software, SRE owns uptime. In ML systems, MLOps owns pipeline health. In AI products built on LLMs, who owns behavioral reliability — the question of whether the model is still doing what you deployed it to do?
What happens when the model changes underneath you? The whitepaper acknowledges that “AI systems don’t follow fixed rules” and that “capabilities evolve in weeks, not quarters.” But the evaluation framework is presented as a build-time activity. When your model provider ships a new version — and they will, roughly every three days according to the whitepaper’s own graphic — who reruns those evals? Who detects behavioral drift before your users do?
Where are the SLOs? The table has qualitative goals (”accurate, grounded, and useful”) but no quantitative thresholds. In SRE, you don’t say “the system should be reliable” — you say “99.9% availability measured over a 30-day rolling window.” AI products need the same precision: “faithfulness score above 0.85 on our evaluation suite, measured daily across a stratified sample of production queries.”
What’s the incident response playbook? When a guardrail fails — and it will — what happens? The whitepaper’s “continue/refine/stop” gates are pre-launch decisions. Post-launch, you need detection, triage, mitigation, and postmortem processes. You need to know whether to roll back the prompt, switch models, tighten the guardrail, or escalate to a human.
The Missing Chapter: Model Reliability Engineering
These aren’t minor gaps. They’re the difference between a successful pilot and a production system that earns trust over months and years.
The discipline that fills this gap is what I call Model Reliability Engineering (MRE) — the practice of owning model behavior reliability in production. MRE borrows the operational rigor of Site Reliability Engineering and applies it to the unique challenges of AI systems that generate outputs based on patterns rather than predefined logic.
MRE operates through two layers:
Context Engineering — ensuring the model receives the right information, in the right format, at the right time. This covers retrieval quality, prompt construction, tool orchestration, and the entire input pipeline. When the whitepaper’s “retrieval” and “summarization” stages fail in production, it’s usually a Context Engineering problem: the retrieval pipeline returned stale data, the prompt template drifted, or the context window was consumed by irrelevant information.
Harness Engineering — everything that wraps around model output before it reaches the user. Output validation, consistency checking, safety filtering, fallback logic, and the instrumentation that makes all of this observable. The whitepaper’s “guardrails” stage lives here, but MRE treats it as a continuous runtime concern rather than a pre-launch checkpoint.
Think of it this way: the whitepaper’s Phase 4 table is a construction inspection checklist. MRE is the building management system that keeps the building safe after the inspectors leave.
What This Means for Your Team
If you’re building AI products and following OpenAI’s playbook — which, again, is genuinely good organizational advice — here’s how to fill in the gap:
Define behavioral SLOs before launch. Not “the system should be accurate” but “faithfulness ≥ 0.85, relevance ≥ 0.80, guardrail violation rate < 0.1%, measured daily on a stratified sample of 500 production queries.” These become the contract between your AI product and your organization.
Assign MRE ownership explicitly. Someone — a person, a team, a rotation — needs to own behavioral reliability the way your SRE team owns uptime. They monitor the behavioral SLOs, investigate violations, and coordinate with product and engineering on fixes.
Build for model-provider instability. Pin your model versions. Run behavioral regression tests on every model update. Maintain a rollback capability. The whitepaper says innovation happens every three days — your evaluation system needs to keep pace.
Create an incident response playbook for behavioral failures. When your Q&A agent starts hallucinating, who gets paged? What’s the first mitigation? How do you determine blast radius? These are engineering operations questions, not product management questions.
Instrument everything. Log prompts, retrieved context, raw model outputs, post-processing transformations, and final user-facing responses. Without this trace, you can’t diagnose failures and you can’t run meaningful evals.
The Bigger Pattern
This gap isn’t unique to OpenAI’s whitepaper. It reflects a broader industry blind spot: we’ve gotten good at building AI systems and reasonably good at evaluating them before launch, but we haven’t yet developed the operational discipline for keeping them reliable in production.
SRE emerged because uptime required its own discipline, separate from software engineering. MLOps emerged because model pipelines required their own discipline, separate from DevOps. MRE is the next layer — the discipline that owns the behavior of AI systems that are neither deterministic nor static.
OpenAI’s playbook will get you to production. Model Reliability Engineering is what keeps you there.