

Privacy Filter Is Not an LLM
OpenAI’s open-weight PII model is a bidirectional token classifier — what that architecture buys, where the headline benchmark misleads, and why Anthropic ships nothing comparable.

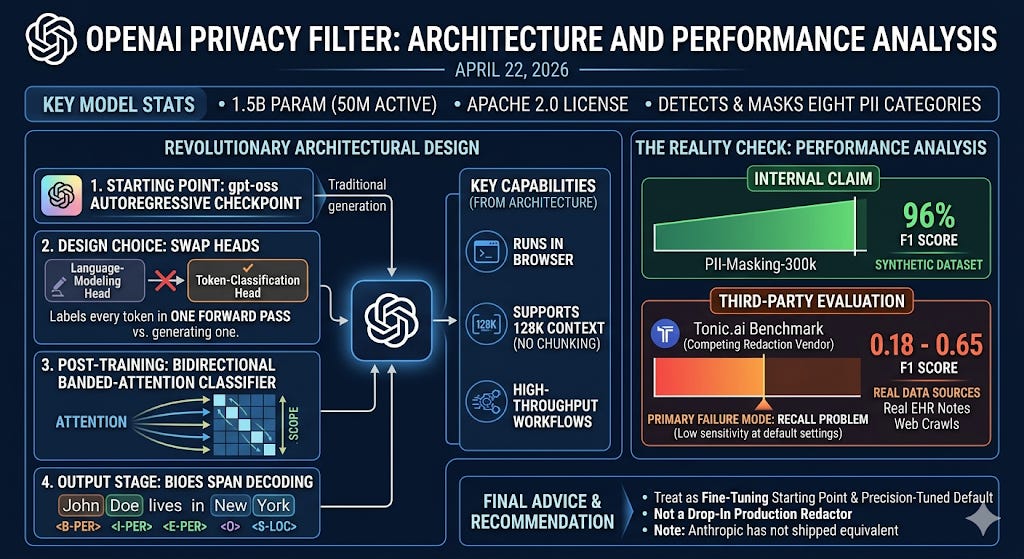
TL;DR - OpenAI released Privacy Filter on April 22, 2026 — an Apache 2.0, 1.5B-parameter (50M active) model for detecting and masking eight categories of personally identifiable information. The headline is the 96% F1 score on PII-Masking-300k. The actual story is the architecture: Privacy Filter takes a gpt-oss autoregressive checkpoint, swaps its language-modeling head for a token-classification head, and post-trains it as a bidirectional banded-attention classifier with BIOES span decoding. It labels every token in a single forward pass instead of generating one. That single design decision is why it runs in a browser, supports 128K context without chunking, and is designed for high-throughput data sanitization workflows. But the 96% F1 is on synthetic data — a third-party benchmark by Tonic.ai (a competing redaction vendor) on real EHR notes and web crawls puts F1 between 0.18 and 0.65 at default settings, almost entirely as a recall problem. Treat Privacy Filter as a fine-tuning starting point and a precision-tuned default, not a drop-in production redactor — and notice that Anthropic, despite having every reason to ship something equivalent, has not.
The architecture: a generative model with its head replaced
Most coverage describes Privacy Filter as “a small open-weight model for PII detection.” That misses the interesting part. Privacy Filter is not a small LLM that happens to do classification. It is structurally a different model class.
Privacy Filter
The base checkpoint is a gpt-oss-style decoder pretrained autoregressively. OpenAI then performs three modifications to convert it into a classifier:
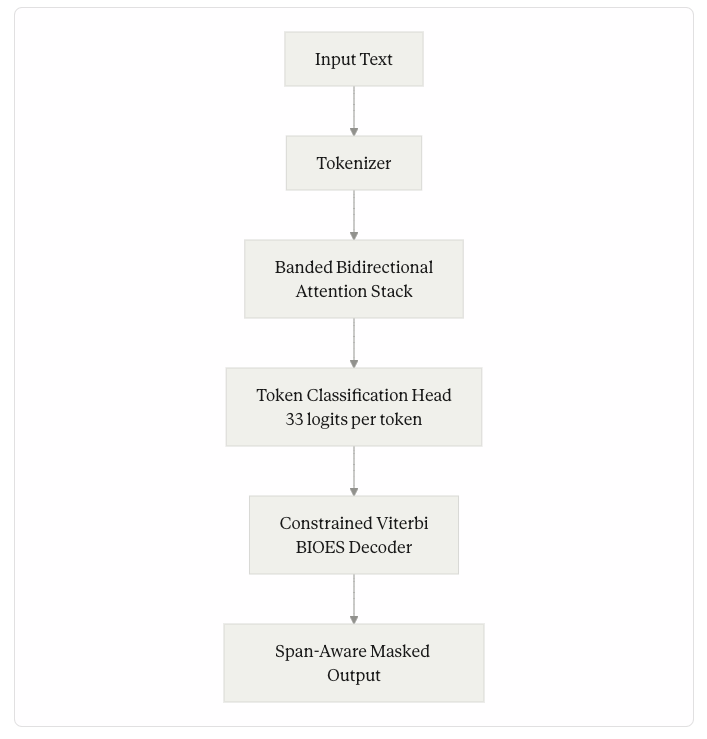
Replace the head. The language-modeling head is removed and a token-classification head is bolted on, emitting 33 logits per token (1 background class plus 8 PII categories × 4 BIOES boundary tags).
Switch attention from causal to bidirectional banded. Each token now attends to a window of 128 tokens on each side (effective receptive field: 257 tokens including itself), in both directions. The causal mask — the thing that makes a model “generative” — is gone.
Post-train with supervised classification loss. No next-token prediction. The objective is BIOES tag accuracy on a privacy-labeled dataset (the public PII-Masking-300k corpus plus synthetic data, augmented with model-assisted annotation review).
The retained pieces are also informative: grouped-query attention (14 query heads, 2 KV heads), rotary positional embeddings, and a sparse mixture-of-experts feed-forward block. The MoE is what gives the 50M-active-out-of-1.5B-total figure. Only a small fraction of weights actually fire on any single forward pass, which is what makes CPU inference viable.
The Architecture
The decoder is the other piece worth surfacing. Per-token classifications produce incoherent spans on their own — “John” tagged as begin-name, the next token tagged as begin-address, and so on. To prevent that, Privacy Filter applies constrained Viterbi decoding over the BIOES transition graph. Begin must be followed by Inside, Inside, or End. End cannot transition to Inside. Single is its own one-token span. The decoder enforces these transitions globally over the sequence, so the output is always a clean set of contiguous spans.
This architecture is not novel by NLP standards — BIOES tagging and Viterbi decoding date back to pre-transformer NER systems. What is novel is using a frontier-quality pretrained generative model as the substrate, then surgically retargeting its head and attention pattern for a different objective. The world model the autoregressive pretraining gave the network — the contextual sense of when “Alice” is a literary character versus a person in a customer email — is preserved. That world model is what classical Presidio-style regex-plus-NER doesn’t have, and it is the entire reason Privacy Filter outperforms rule-based systems on ambiguous spans.
Why the architecture matters in production
Three properties fall out of this design that an LLM-based redactor wouldn’t have.
Single-pass labeling. A 128K-token document is processed once. There is no autoregressive decoding loop over the output, no chain-of-thought reasoning, no JSON parsing of the result. OpenAI describes the model as designed for high-throughput data sanitization workflows but does not publish specific tokens-per-second numbers; the architecture’s single-forward-pass design is what enables a sanitization-on-every-prompt deployment pattern even at modest hardware budgets.
No prompt engineering surface. A generative model used for classification has prompts, which means it has prompt injection risk. A token classifier has neither. There is no instruction the input can override.
Adjustable precision/recall via the decoder, not the weights. OpenAI exposes the Viterbi transition biases as runtime knobs. You can shift the operating point toward higher recall without retraining, just by re-tuning decoder priors.
The flip side is genuine: token classifiers cannot reason about context the way an LLM can. They cannot rewrite, synthesize, or follow a custom redaction policy (”redact only PII belonging to non-employees”). Privacy Filter does what it does and nothing else.
The 96% F1 trap
The PII-Masking-300k benchmark is a synthetic corpus generated specifically to evaluate PII-masking systems. OpenAI reports F1 = 96% on the original (94.04% precision, 98.04% recall) and 97.43% on a corrected version where they fixed annotation errors. Both numbers are real and reproducible.
They are also nearly useless as a production signal.
Tonic.ai — itself a vendor of competing redaction tooling — published a benchmark within days of release, running Privacy Filter against four real-world test groups: electronic health record notes, call-center transcripts, loan contracts, and web crawls. Their methodology is transparent (token-level evaluation projected to Privacy Filter’s 8-class taxonomy on 500+ documents) and the comparison product is their own. With those caveats noted: Privacy Filter’s F1 ranged from 0.18 to 0.65 at default settings. Tonic’s purpose-built redactor scored 0.92–0.99 on the same data. Precision was comparable across both systems (around 0.77–0.85 for Privacy Filter). The gap was almost entirely recall: on web-crawl PII, default recall was 10%; on EHR notes, 38%.
Two things explain this. First, OpenAI ships Privacy Filter with a precision-tuned default operating point. Over-redaction destroys downstream utility, and the company chose to under-flag rather than over-flag. The Viterbi knobs can recover most of the gap, but at the cost of multiplying total predictions roughly 5× — with a corresponding hit to precision on common words like “our” and “please.” Second, real-world PII has a long tail of formats — international phone numbers, forum-handle-style usernames, obfuscated contact blocks, region-specific identifiers — that the default eight-category taxonomy doesn’t even attempt to cover. SSNs, MRNs, NHS numbers, and Brazilian CPFs are not in the default label set.
Fine-tuning closes the gap. OpenAI’s own announcement reports fine-tuning improves F1 from 54% to 96% on a domain-adaptation benchmark and approaches saturation, and the model card explicitly recommends task-specific fine-tuning when policy differs from base boundaries. The lesson: Privacy Filter’s value as a base model is real. Its value as a drop-in production redactor at default settings is not.
Where Anthropic fits — and conspicuously doesn’t
Anthropic does not ship anything equivalent to Privacy Filter. There is no open-weight Anthropic PII detector. There is no Claude API endpoint specifically for PII redaction. The Constitutional Classifiers Anthropic publishes about — including the more recent two-stage cascade with activation probes — are jailbreak and CBRN safety filters, scanning for harmful intent rather than personal data. They are also closed-weight and operated only inside Anthropic’s own deployment.
This is a structural difference between the two labs in 2026. OpenAI now maintains an open-weight model family (gpt-oss-20b, gpt-oss-120b, and now Privacy Filter as a derivative). Anthropic does not. For an engineering team using Claude in a regulated environment — healthcare, legal, financial — there is no first-party path to local PII filtering on Claude’s own infrastructure. The viable options are:
Run Privacy Filter or Presidio in front of Claude as a proxy. This is what community tooling like the Claude Privacy Tool already does — it intercepts prompts locally, swaps PII for placeholders using OpenAI’s open-weight model, sends the masked version to Claude, and re-substitutes on the way back.
Use a commercial proxy. Tools like Grepture or Tonic Textual sit between the client and the Claude API, performing token-level redaction with a reversible token map.
Build it in-app. Open issues like anthropics/claude-code#29434 are explicitly requesting a first-party redaction hook in Claude Code so secrets and PII don’t enter the context window in the first place.
The strategic reading: OpenAI is positioning small, specialized open-weight models — what’s worth calling safety SLMs — as infrastructure they want the broader ecosystem to standardize on. Anthropic’s safety story is built around training-time alignment plus closed classifiers integrated tightly into Claude itself. Both are legitimate strategies. Only one of them gives you a model you can run locally.
The alternatives landscape
For teams evaluating PII redaction in 2026, Privacy Filter joins a crowded field. The relevant tradeoffs:
Microsoft Presidio is open source, mature, and combines regex pattern recognizers, spaCy-based NER, and contextual checks. It supports more languages out of the box than Privacy Filter and ships with image and structured-data redactors that Privacy Filter lacks. Its weakness is exactly where Privacy Filter is strong: ambiguous, contextual PII that requires language understanding rather than pattern matching, since its defaults rely heavily on regex and pre-trained NER models rather than purpose-trained PII classification.
AWS Comprehend is a managed cloud API. AWS’s docs state PII detection supports English or Spanish text documents only, with no on-prem option. It is a reasonable pick only if your data is already in AWS and your sensitivity tolerance allows cross-network calls.
Google Cloud Sensitive Data Protection (formerly DLP) has the broadest taxonomy — over 200 built-in infoType detectors — but is also cloud-only and the most complex to configure.
Private AI is the commercial purpose-built option. The vendor publishes its own benchmark showing it leading on recall across domains, with multilingual support and a containerized on-prem deployment path. Treat the numbers as vendor-published rather than independent.
Tonic Textual is the production-trained option for teams with real customer data — its head-to-head against Privacy Filter is the only public comparison on non-synthetic corpora to date.
The architectural takeaway across these options: Privacy Filter is the first frontier-lab open-weight entry into a category that has been dominated by closed cloud APIs and SDK-based regex-NER hybrids. Its long-term value is probably less as a finished tool and more as a base checkpoint that shifts the ecosystem from rule-based to learned context-aware redaction.
What this means for your stack
If you are building production AI features today and PII handling is part of the threat model, three concrete decisions follow.
First, decide where redaction lives in your pipeline. The two viable spots are at-source — a proxy or hook that scrubs prompts before they reach any LLM API — and in-batch — a sanitization pass on training data, logs, and indexed corpora before they reach a vector store. These have different operating-point requirements. At-source needs low latency and reversibility (the token-to-real-value map persists for the session). In-batch can be slower, can run in parallel, and is one-way.
Second, do not adopt Privacy Filter at default settings if your data doesn’t look like PII-Masking-300k. Either fine-tune on a few hundred to a few thousand domain examples, or tune the Viterbi knobs aggressively and accept the precision hit, or run Privacy Filter as one detector among several with rule-based and pattern-based detectors filling the gaps. The eight-category taxonomy is also static — if your domain has SSNs, MRNs, NHS numbers, or non-US tax IDs, you will need to fine-tune to add those classes.
Third, reversibility is the real production problem, not detection. If your application needs to mask PII before sending to an LLM and then un-mask it in the response, you are doing pseudonymization, not anonymization. The LLM might rewrite, paraphrase, or modify the placeholders, and your un-masking logic has to handle that. Privacy Filter solves none of this. Tools like Protecto and Tonic position themselves explicitly around the un-masking robustness problem, which is harder than the F1 score implies.
Safety SLMs as a model class
Privacy Filter is the clearest signal yet that “small, specialized model trained for one safety task” is becoming a stable category — distinct from foundation models and distinct from classical NLP libraries. The pattern is consistent: take a frontier-pretrained checkpoint as the substrate, surgically modify the head and attention pattern for a single classification or scoring objective, post-train on labeled safety data, and ship the weights under a permissive license so the ecosystem can fine-tune for vertical domains.
The next entries in this category are predictable. Prompt-injection detectors. Toxicity classifiers. Output policy auditors. Code-secret scanners. Some already exist as research artifacts. Privacy Filter is the first that is small enough to run in a browser, accurate enough to ship, and open enough to adapt without negotiating a license. If safety SLMs become the standard infrastructure layer for production AI — the privacy and safety equivalent of TLS termination — Privacy Filter is the v1.
What’s worth watching is whether Anthropic continues to keep its safety classifiers internal, or whether the competitive pressure of an open ecosystem forces a shift. The Constitutional Classifiers research is, technically, exactly the kind of work that could ship as open weights for the broader community to build on. So far, it hasn’t.