

The Anatomy of a Production Vertical Agent
Seven layers wrap every LLM that has shipped in healthcare, banking, and insurance. The model itself is the smallest of them — here’s what the other six are doing.

TL;DR - Production AI agents in regulated industries — clinical documentation at Abridge, prior authorization at Anterior, patient engagement at Hippocratic, customer experience at Sierra, mortgage origination at Rocket and Tavant — have converged on a seven-component architecture. The LLM is the smallest of those seven. The other six do the load-bearing work: a router that orchestrates calls, a constellation of specialist models with supervisors, a deterministic policy layer that retains decision authority, a domain schema adapter into the system of record, a long-horizon state store, a human checkpoint router, and a regulator-replay audit trail. No two vendors call them the same thing. They are the same components. Call the pattern Vertical Agent Anatomy (VAA). If your design is missing any of these seven, you are building a demo, not a production vertical agent.
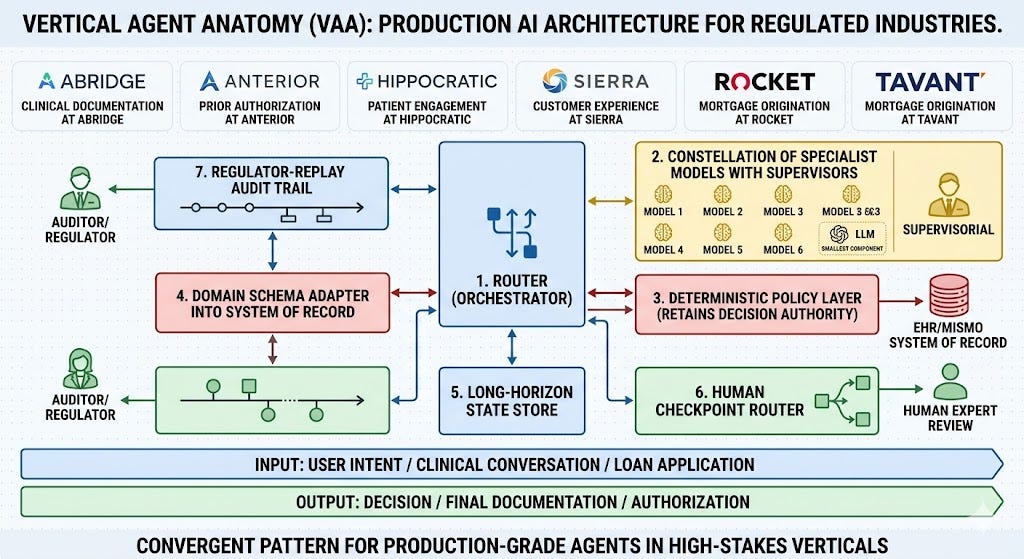
A production vertical agent is an LLM-driven system that operates safely inside a regulated industry’s compliance, schema, and system-of-record constraints. In practice, this requires seven specific architectural components: the LLM itself, plus six layers of deterministic scaffolding that prevent it from speaking, deciding, or acting outside those constraints. The MongoDB engineering team has argued the LLM is the smallest part of any production agent system. Regulated verticals make the imbalance more extreme — the harness becomes nearly the entire system.
Production vertical agents have converged on the same seven components
Read enough architecture posts and the same pattern emerges. Sierra calls its multi-model layer a “constellation of models” and the policy-enforcement layer “supervisor agents.” Hippocratic AI calls its constellation “Polaris” — roughly twenty-two supervising LLMs around a ~400B-parameter primary, aggregate ~4.1 trillion parameters. Decagon calls its routable workflow definitions “Agent Operating Procedures” and its quality-review layer “Watchtower.” Abridge calls its evidence-linked audit layer “Linked Evidence.” Norm Ai calls its regulation-to-decision-tree compiler “Leap.” Tavant calls its mortgage agent framework “MAYA” and positions the underlying identity model with the line: “These [AI] agents need to be provisioned like people.” Workday calls its agent registry and lifecycle layer the “Agent System of Record.”
Different names. The same seven components.
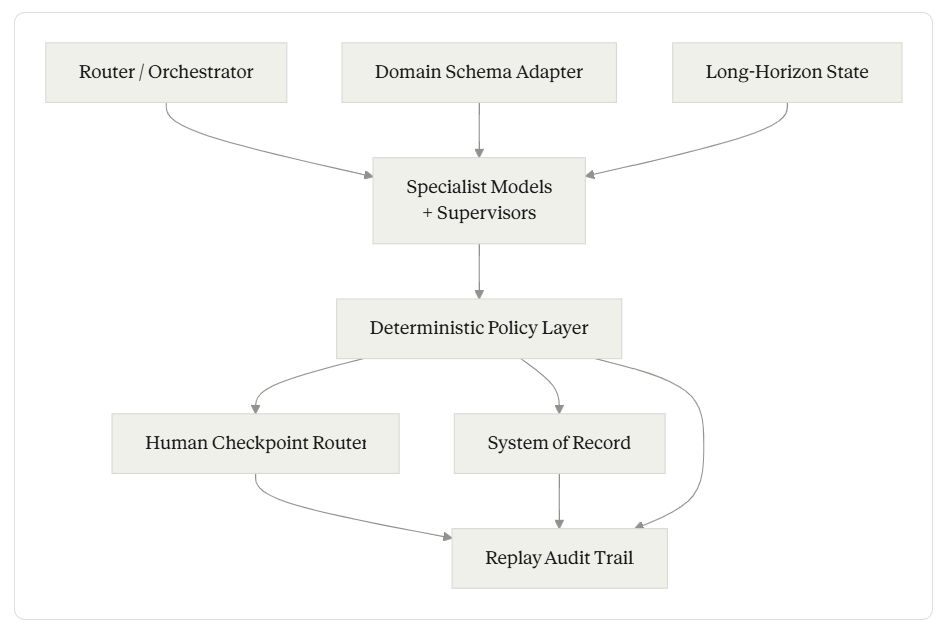
The closest academic anchor is the 2025 arXiv paper that proposed a standardization of Vertical AI agent design patterns and named the central component a “Cognitive Skills Module” — what we’ll call the specialist model constellation. The paper formalized the cognitive layer but did not name the surrounding six. The MongoDB harness writeup formalized the surrounding scaffold for general-purpose agents but did not specialize it to regulated verticals. VAA is the regulated-vertical specialization: the same architecture, with the harness components made specific because the vertical demands they be.
1. The Router/Orchestrator decides who handles what
The router is the first thing a request hits. It decides which downstream models, which tools, which policies, and which humans get involved. Production verticals see heterogeneous request types — a KYC submission, a prior auth appeal, and a refinance inquiry all require different downstream paths. Single-model designs try to reason their way to the path. Production agents route deterministically when they can.
Sierra’s Agent OS routes among 15+ models depending on task — low-latency models for lookups, high-precision classifiers for behavior detection, tone-optimized models for sensitive interactions. Rocket Mortgage’s “Rocket AI Agent API” performs the same role across the borrower lifecycle on AWS Bedrock, with Step Functions orchestrating Claude 3 Haiku fine-tunes and other specialist models. Decagon’s AOPs are essentially programmable router definitions in natural language.
The architectural insight: the router is the cheapest place to enforce determinism. Every routing decision that doesn’t go through an LLM is one fewer failure mode in production. Teams who treat the router as an afterthought and let the LLM decide its own next step end up paying for that decision in eval cost and audit ambiguity.
2. The Specialist Model Constellation is where the LLM actually lives
The LLM does not sit alone. It sits inside a constellation of specialist models, each tuned to a subtask, with supervising models that check outputs before they leave the constellation.
The pattern is explicit at Sierra: agents are assembled from 15+ purpose-built models working in concert, backed by supervisors that enforce guardrails, policies, and quality checks. It is more extreme at Hippocratic, whose Polaris architecture places roughly twenty-two supervising LLMs around the primary conversational model — the design explicitly assumes the primary cannot be trusted to police itself. Anterior’s published architecture follows the same shape: specialist models for classification and synthesis, LLM-as-judge supervisors evaluating outputs in real time, with a clinical review team an order of magnitude smaller than competitor benchmarks because the supervisors absorb most of the work.
This is also where the constellation’s biggest design failure shows up: teams overspend on model selection and underspend on supervisors. Picking the right primary model matters less than the question of whether anything is checking its output before it leaves the agent.
3. The Deterministic Policy Layer retains the decision authority
This is the single most underappreciated layer. The policy layer is the non-LLM gatekeeper that decides whether the model’s recommendation can be acted on, escalated to a human, or rejected outright. Regulators do not accept “the model said so.” Liability sits with the deterministic decision-maker, and the deterministic decision-maker is not the LLM.
The pattern is consistent across verticals. Microsoft’s Azure AI Foundry prior authorization template is explicit: the agent never produces an automated DENY, only APPROVE or PEND, and every recommendation requires clinician sign-off with documented rationale. Blend’s mortgage agent Autopilot “does not make credit decisions, which remain the responsibility of human underwriters and automated underwriting systems.” Anterior’s design principle — never let the LLM make the final authorization decision — sits at the same architectural location. Norm Ai’s Leap platform pushes this furthest, representing regulations themselves as decision trees rather than as LLM prompts, so the policy layer is the regulation itself in machine-executable form.
The common confusion is to call this “human-in-the-loop.” It is not. The policy layer runs before any human sees the recommendation; it filters which decisions even reach the human checkpoint router. Calling it human-in-the-loop is how teams end up with a system that escalates everything and overwhelms reviewers, or escalates nothing and ships a deterministic decision under an LLM-shaped accent. Both outcomes are common. Both are architectural failures at this layer.
4. The Domain Schema Adapter is where every vertical pays its own tax
The schema adapter is the translation layer between LLM-native representations and the vertical’s canonical schemas — and the systems of record built on them. Healthcare has FHIR R4 and HL7 v2 and SMART-on-FHIR and CDS Hooks and C-CDA and the Da Vinci PAS/CRD/DTR profiles. Mortgage has MISMO and Encompass and MSP. Insurance has ACORD. Trade has FpML and FIX. Cross-border payments now have ISO 20022. Demos work in plain English. Production does not.
Abridge’s Epic integration is the canonical example. Abridge was the first ambient-AI tool officially integrated into Epic’s EHR through the “Pal” program, with Linked Evidence mapping any word or phrase in the generated note back to source transcript or audio in real time. The integration is bidirectional and embedded inside Epic workflows from Haiku to Hyperdrive — not a wrapper around Epic, a participant in it. Rocket Mortgage’s Bedrock agents bridge directly into MSP and Encompass. AWS AgentCore Gateway exposes core banking systems as OpenAPI-schema tools so KYC agents can act against them without modeling the underlying banking schema in prompts. ICE Aurora embeds responsible agentic AI directly into Encompass and MSP rather than running as a standalone tool.
The architectural insight is that every vertical pays this tax independently. There is no FHIR-equivalent layer that crosses verticals; even within a vertical, there is no clean abstraction across systems of record. Schema work is where production cost accumulates and where horizontal AI agent platforms keep hitting the same wall. It is also where vertical agents earn their right to exist — the deep schema bridge is the moat, not the model choice.
5. The Long-Horizon State Store handles the cases that span weeks
A prior auth can bounce three times. A disability claim spans 90 days. M&A diligence runs for two quarters. A mortgage application drags for 45 days. Stateless agents cannot handle any of these.
The state store is the agent’s durable memory across days, weeks, or quarters — for cases that don’t fit in a single request/response. Tennr’s RaeLM™ document-reasoning model, trained on 100M+ medical documents and 2.3B distinct data fields, acts as the persistent reasoning substrate for referral workflows that touch the same patient across multiple touchpoints. Oracle AI Agent Memory positions itself explicitly as “a persistent memory core for AI agents...enabling them to perform well at long-horizon tasks.” Sierra’s Agent Data Platform serves the same role for CX agents whose conversations span multiple sessions.
The missing primitive at this layer is reawakening on external events — not just storing state but triggering on it. A claim that bounces and resurfaces 60 days later. A loan that becomes refinanceable when rates drop. A KYC review that requires re-verification on an annual cadence. Most vertical agents are still built as request/response when the underlying workflow demands a calendar- and event-aware agent. This is one of the clearest gaps between current production deployments and what the next generation of vertical agents will require.
6. The Human Checkpoint Router is not “human-in-the-loop”
“Human-in-the-loop” as a vibe is not a checkpoint architecture. Production checkpoint routing has explicit thresholds, named reviewer pools, SLA tracking, and override-rate telemetry that feeds back into the eval system.
Anterior is the cleanest published example: confidence-tiered routing where each tier specifies which clinical reviewer types see the decision, and the override rate is treated as a continuous quality signal — initial override rates of 15–20% decay toward <5% as the system learns from each override. Hippocratic AI’s clinician validation network — more than seven thousand licensed U.S. clinicians as of the November 2025 Series C announcement — exists as a checkpoint pool that the router can call into based on specialty, jurisdiction, and conversation type. Tavant’s stated principle extends further: AI agents themselves need explicit identities, distinct authority scopes, and full auditability — provisioned like people, not like generic automation. The implication for the checkpoint router is that the human and the agent are both first-class identities with explicit authority models.
The architectural failure mode here is the “send everything below 80% confidence to a human” pattern. This is not a checkpoint router; it is a workload offload. Production deployments build a routing policy that names specific reviewers, specific SLAs, specific reasons for escalation, and tracks override rates as a continuous quality signal that loops back into the eval system. Calibration of the threshold is itself an ongoing engineering problem — not a static config value.
7. The Regulator-Replay Audit Trail is not a log file
Every regulated vertical demands that decisions be reproducible. HIPAA. The Federal Reserve’s SR 11-7. The NAIC AI Model Bulletin. FCRA adverse-action notices. NYDFS Part 500. CMS-0057-F. “We have logs” is not auditable. The audit trail in a production vertical agent is evidence-linked, decision-grained, tamper-resistant, and designed to survive a regulator or a court reconstructing why a specific decision was made on a specific day for a specific person.
Abridge’s Linked Evidence is the cleanest example in healthcare: every section of a generated note maps back to the timestamped transcript and source audio, so clinicians and auditors can reconstruct provenance at the word level. Sixfold provides full sourcing and lineage for every underwriting decision, with the explicit goal of making the decision defensible in a regulatory review. The MobiHealthNews blueprint for agentic prior auth describes the audit substrate as a “provenance graph that records every step an agent takes” — what data it looked at, which rules and policies it applied, what it decided and why.
Academic prior art is catching up. The Brown audit-trails paper defines LLM audit trails as “a chronological, tamper-evident, context-rich ledger of lifecycle events and decisions.” IBM’s “Replayable Financial Agents” preprint goes further and proposes a determinism-faithfulness assurance harness specifically for regulatory replay of tool-using LLM agents in finance.
Logs are not audit trails. Audit trails are designed for replay by someone who wasn’t in the room. The two are not architecturally equivalent, and treating them as equivalent is one of the most common reasons production vertical agent pilots fail compliance review.
Why this is a framework, not a checklist
The seven components are load-bearing in regulated industries. They are not optional. A general-purpose customer-service chatbot can ship without a deterministic policy layer because nothing it does carries regulatory weight. A KYC agent cannot. A prior auth agent cannot. A mortgage origination agent cannot. The Bessemer vertical-AI thesis (with the caveat that Bessemer is a portfolio investor in Abridge and a number of other vendors cited in this piece) and the broader vertical-AI investor consensus argues that vertical agents win because they reach further into the system of record. That is true, but it is the schema adapter doing that work, not the model. The model is the easy part.
VAA is descriptive, not prescriptive. The components illuminate where production engineering effort actually goes — and where most early deployments under-invest. They are not a scoring rubric. A system with all seven components but a weak schema adapter will still fail in production. A system that nails the schema adapter but treats the policy layer as a confidence threshold will pass demos and fail audits.
The interesting question once the seven components are recognized is comparative: the shape of those components changes dramatically across verticals. A healthcare audit trail looks nothing like a banking audit trail. A mortgage human checkpoint router looks nothing like a claims one. Schema work in insurance is fundamentally unlike schema work in legal. That comparative analysis — how the harness reshapes itself vertical by vertical — is the next piece in this series.
What this means for your build
Three takeaways for engineering teams looking at vertical agent deployments today.
First, audit your design against the seven components before you start measuring model quality. Most teams discover that what they thought was an “agent” is actually four of the seven components glued together with weak supervisor coverage and no replay audit. Measuring model accuracy on that system answers the wrong question.
Second, the schema adapter and the policy layer are where production hours go. Engineering effort that does not touch one of these two components after the first month is engineering effort that is not building a production vertical agent. This is where the Retrofit Tax hides — every legacy schema, every undocumented system-of-record behavior, every state-by-state policy variation pays itself in engineering hours.
Third, design the audit trail before you design the model. The audit trail constrains everything else — what gets logged, what gets versioned, how decisions are reconstructed, what evidence the policy layer captures on the way through. Most teams design the audit trail last. The result is logs that observability tools can read but regulators cannot.
The LLM is the smallest part. The other six components are the work.
FAQ
What is a vertical agent? A vertical agent is an LLM-driven system designed to operate within a specific industry’s regulatory, schema, and system-of-record constraints — healthcare, banking, insurance, legal, or mortgage. The defining feature is not the model; it is the deterministic scaffolding around the model. The 2025 arXiv standardization paper formalizes the academic definition; production deployments at Anterior, Abridge, Sierra, Decagon, Hippocratic, Harvey, Sixfold, Norm Ai, Tennr, Tavant, Rocket, and Blend instantiate the seven-component shape.
What is the difference between a vertical agent and a general-purpose agent? General-purpose agents have a harness, but the harness is optional in the sense that demos and consumer products can ship without most of it. Vertical agents in regulated industries cannot ship without the harness — every component carries regulatory, schema, or liability weight. The same seven components exist; the difference is that in vertical deployments they are load-bearing rather than nice-to-have.
Can a vertical agent skip any of these components? Not in regulated industries. A vertical agent missing the deterministic policy layer cannot pass model risk management review. One missing the regulator-replay audit trail cannot pass an HHS, OCC, or NAIC audit. One missing the schema adapter cannot reach into the system of record and is effectively a chatbot pretending to be an agent. One missing the human checkpoint router cannot allocate liability cleanly. Each component exists because something specific in the regulated environment requires it.
Is the LLM really the smallest component? By engineering hours, yes. The MongoDB engineering team has made this case for general-purpose agents — the model interaction is a small fraction of the codebase compared to state, governance, orchestration, memory, observability, and evaluation. Regulated verticals push this further. The schema adapter alone often exceeds the entire model-interaction layer in lines of code, ongoing maintenance, and incident frequency. The audit trail and policy layer compound the imbalance.
What is the relationship between VAA and the harness concept? The harness is the broader engineering pattern around any production LLM agent. VAA is the regulated-vertical specialization of that pattern. Components 1, 5, 6, and 7 of VAA correspond closely to harness primitives the MongoDB writeup names (orchestration, memory, governance, observability/eval). Components 3 and 4 — deterministic policy layer and domain schema adapter — are where vertical agents specifically diverge from general-purpose agents.
Read more:
How Vertical Agents Self-Improve in Production

TL;DR - In regulated verticals — healthcare, legal, insurance, finance — the most reliable way to make a deployed agent better is not a new model. It is a closed loop that turns production failures into harness updates: prompts, tools, sub-agents, memory files, judge rubrics, routing logic. Harvey ran this loop on twelve legal tasks and moved average su…
“The seven components are load-bearing in regulated industries. They are not optional. A general-purpose customer-service chatbot can ship without a deterministic policy layer because nothing it does carries regulatory weight.”
totally agree. this was a really solid article thanks a ton :)