

The Complete Field Guide to Browser Harnesses in 2026
Thirty-plus harnesses, four topologies, two billion-dollar valuations, one collapsing abstraction layer. The canonical landscape of how autonomous agents drive the web - and the trade-offs that decide

TL;DR - The market for browser harnesses - the engineered layer between an autonomous agent and a live web page, has crystallized into four topologies in the last twelve months: code-first deterministic (Libretto, Healenium), NL-DSL hybrid (Stagehand v3, Browser Use, AgentQL), vision-LLM CUA (Skyvern, Anthropic Computer Use, OpenAI Operator, Project Mariner), and a fourth emerging thin-CDP pattern (browser-use/browser-harness) that argues the entire abstraction layer is on a collapse trajectory. Underneath the SDKs, the browser-as-a-service market has consolidated to five serious players (Browserbase, Steel, Anchor, Hyperbrowser, Bright Data) competing on session-minute pricing plus stealth, proxy, and CAPTCHA bundles. WebVoyager has saturated above 90% and no longer differentiates the top tier; Web Bench - 5,750 tasks across 452 live sites, with mutating "write" operations - is the benchmark that matters now, and Skyvern's 64.4% on it is the current public number to beat. For engineering teams picking a harness in 2026, the right answer is almost never one topology. It is a deterministic, cached, replayable code skeleton wrapped around a small fallback CUA loop for the long tail.
What is a Browser Harness?
A browser harness is the engineered surface through which an autonomous agent perceives, acts on, and validates against a live web page. It is not the model. It is not Playwright. It is not the agent itself. It is the layer between them that handles four primitives: perception (how the page is represented for the model), action (how the model’s intent is translated into clicks, types, and navigation), durable state (what survives across steps, sessions, and process boundaries), and recovery (how the harness behaves when the page changes underneath).
The discipline of building this layer well, Harness Engineering, emerged in 2025 as the natural counterpart to context engineering. Context engineering governs what the model knows. Harness engineering governs what the agent sees, can act on, and can observe. In production agent systems, the harness is where reliability is engineered. The model contributes the easy 80% of capability. The harness contributes the difference between an automation that works in a demo and one that holds up against vendor UI redesigns, session model changes, and adversarial bot detection over a multi-year deployment.
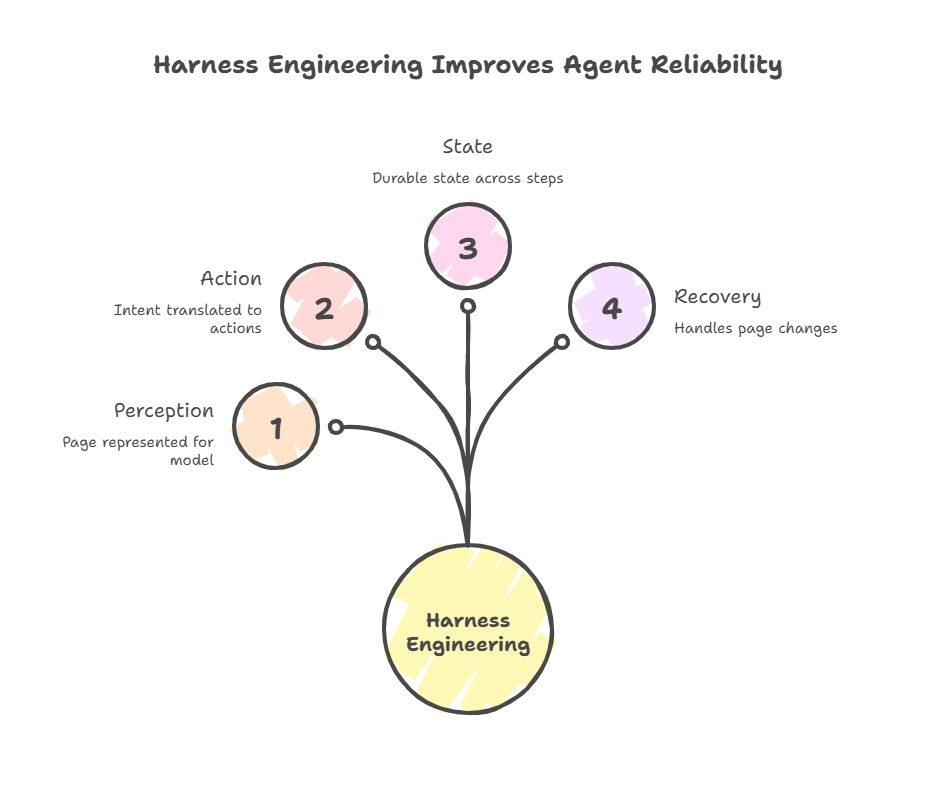
The four topologies
Production deployments in late 2025 and early 2026 converge on four structural patterns, each with a different center of gravity on the cost / determinism / surface-coverage axis.
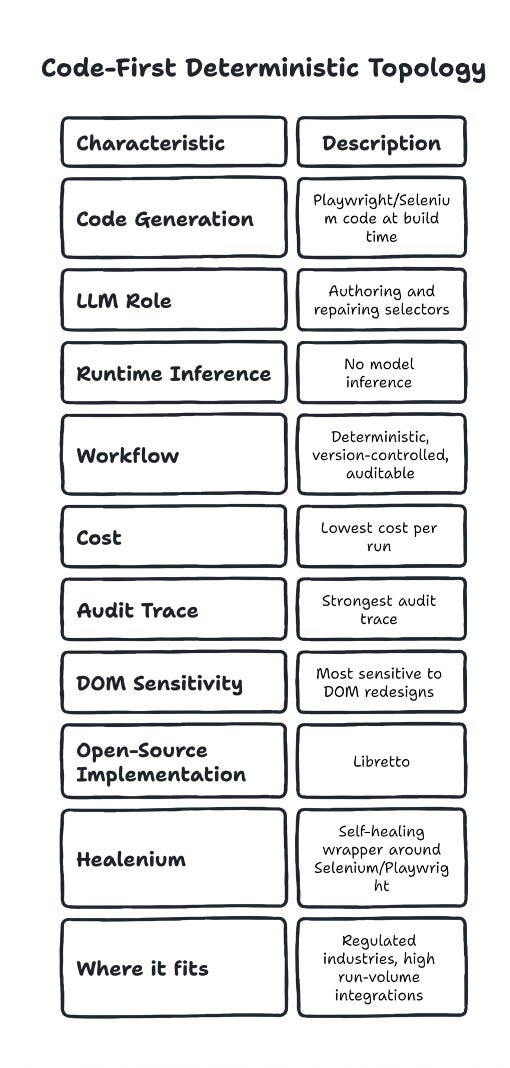
Topology one: code-first deterministic
The agent generates Playwright (or Selenium) code at build time. The LLM is in the loop for authoring selectors and repairing them when they break. At runtime, no model inference happens - the workflow runs as deterministic, version-controlled, auditable code. Lowest cost per run, strongest audit trace, most sensitive to DOM redesigns.
The reference open-source implementation is Libretto, released by Saffron Health in October 2025. Libretto generates Playwright/TypeScript code with Zod-typed input and output schemas. Its killer move is a reverse-engineering pass that watches network traffic during a successful run and, where the underlying API permits, generates a direct-HTTP version of the workflow that bypasses the UI entirely. Saffron’s HN post documents the constraint that drove the design: “a year building and maintaining browser automations for EHR and payer portal integrations” where every vendor UI change broke the previous quarter’s work.
Healenium is the older sibling pattern, a self-healing wrapper around Selenium and Playwright that uses tree-comparison ML to repair broken selectors at runtime. The Pro tier extends this with AI-generated GitHub PRs to fix locators in source. Healwright is the JavaScript-native sibling.
Where it fits: regulated industries where audit trail is non-negotiable (healthcare, banking, insurance, legal), workflows with high run-volume and bounded counterparty lists, integrations where the underlying API exists and can be replayed directly.
Topology two: NL-DSL hybrid
The agent expresses intent through a small set of high-level primitives - act, extract, observe, agent in Stagehand; Agent.run(task=…) plus @tool-decorated functions in browser-use; query-language extraction in AgentQL — and the harness falls back to the LLM only at decision points. Caching makes the second run of a workflow ~deterministic; the LLM only fires on cache miss.
Stagehand v3, released by Browserbase in late 2025, is the reference implementation. Browserbase rewrote the framework on top of Chrome DevTools Protocol directly, made the LLM provider swappable through a Model Gateway, and shipped automatic action caching at both the SDK and Browserbase server level. Cache hits validate against a DOM hash and execute the stored selector directly, no LLM call. Browserbase’s own measurement: “up to 2x faster execution and ~30% cost reduction on repeat workflows” from caching alone.
Browser Use is the Python-first sibling. The agent is, in the team’s own words, “just a for-loop” - the SDK exposes Agent, Tools, a CompactionConfig for context-window management, and an ephemeral=N flag that keeps only the last N tool outputs in context. The company raised a $17M seed led by Felicis in March 2025 and operates browser-use Cloud with a hosted model (bu-ultra) that reports 89.1% on WebVoyager with GPT-4o and ~14 tasks per hour on their internal 100-hard-task set.
AgentQL, from TinyFish ($47M Series A led by ICONIQ Growth in August 2025), takes a different cut - a semantic query language that sits on top of Playwright and returns schema-typed structured data. Google Hotels is the publicly disclosed customer.
Where it fits: most production workloads with diverse counterparty surfaces, build-cost-dominated workflows, teams that want a single primitive set across many integrations.
Topology three: vision-LLM CUA
The model sees a screenshot, decides a mouse and keyboard action, the harness translates it to CDP (Chrome DevTools Protocol). Most flexible across surfaces - works on canvas-only UIs, ignores DOM redesigns entirely - but the highest cost per step and the weakest determinism.
Skyvern is the reference open-source vision-CUA harness. Its 2.0 release pairs a vision LLM with a planner-and-validator multi-agent team and scored 85.8% on WebVoyager — a jump from 45% on Skyvern 1.0’s single-prompt loop. The team also co-published Web Bench (5,750 tasks across 452 live sites, including mutating “write” operations where the agent must change state on a real site) and reports 64.4% overall accuracy, the leading public number on the harder benchmark.
The foundation labs ship their own CUA primitives directly. Anthropic’s Claude Sonnet 4.5 (September 29, 2025) introduced a computer_20250124 tool definition with refinements like hold_key, triple_click, and wait, and the post stated that Sonnet 4.5 “now leads at 61.4%” on OSWorld, up from Sonnet 4’s 42.2% just four months earlier. OpenAI’s Operator launched in January 2025 with the o3-based computer-use-preview model; OpenAI’s original CUA paper reported OSWorld 38.1%, WebArena 58.1%, and WebVoyager 87%. Operator was folded into ChatGPT agent on July 17, 2025, and the standalone operator.chatgpt.com site was shut down on August 31, 2025. Google’s Project Mariner shipped a public preview at I/O May 2025 with a Chrome extension, a “Teach & Repeat” learn-once-replay-many primitive, and up to 10 parallel cloud task streams.
Where it fits: surface-general workloads (RPA-style automation across heterogeneous portals, regulatory sites that change frequently), canvas-only or heavily-obfuscated DOMs, exploratory agents where build cost must be near zero.
Topology four: thin CDP
The newest pattern, and the most architecturally interesting. The argument: any abstraction above the raw Chrome DevTools Protocol is a constraint on a model that was already pretrained on millions of CDP tokens. The harness should be a daemon that holds the websocket, plus a workspace where the agent writes its own helpers mid-task and the helpers persist as a domain skill.
Browser Harness (browser-use, January 2026) is roughly 600 lines of code. When the agent encounters a missing capability - drag-and-drop, file upload, dialog handling - it reads the existing helpers, writes a new function in the same style, and uses it immediately. The function persists under agent-workspace/domain-skills/<domain>/ and can be PR’d back upstream.
This is the explicit operational embodiment of Richard Sutton’s “bitter lesson” applied to harness engineering: don’t wrap the model with abstractions; expose the substrate and let the model build the abstractions it needs.
Where it fits: experimental and exploratory work where the team values flexibility over guardrails, internal automation, the long tail of one-off integrations.
The browser-as-a-service layer
Underneath the SDK layer, a separate market has formed: managed browser infrastructure that handles concurrency, stealth, proxies, CAPTCHA solving, and session replay. Five providers compete seriously.
Browserbase is the market leader by funding and customer concentration. The company raised a $40M Series B led by Notable Capital in June 2025 at a $300M post-money valuation, with the financing announced alongside the Director product release. Public customer list spans Perplexity, Vercel, Clay, Commure, 11x, Customer.io, and Structify. Director is the no-code workflow product targeted at non-technical users. The October 2025 launch of 1Password Secure Agentic Autofill is the most concrete production answer yet to the credential-handoff problem.
Steel ships an open-source core (steel-dev/steel-browser, Apache-2.0) and a commercial cloud. The team operates the AI Browser Agent Leaderboard and has published the most honest provider-comparison benchmark in the space: browserbench on AWS EC2 us-east-1, 5,000 runs per provider. Steel’s own measured numbers on cold-lifecycle navigate-to-google: Steel ~665 ms data-plane, Kernel ~1.45× of Steel, Browserbase ~1.97×, AnchorBrowser ~2.17×, Hyperbrowser data-plane ~1.09× but “control-plane tax overwhelms it.” Hobby tier free with 100 hours/month.
Anchor Browser raised a $6M seed in October 2025, co-led by Blumberg Capital and Google’s Gradient Ventures. Tel Aviv-based, founded by Unit 8200, SentinelOne, and Noname alumni. Its public product distinction is b0.dev: run the AI agent only at the planning stage, record the workflow, then replay it deterministically afterward. The same insight as Stagehand caching and Project Mariner’s Teach & Repeat, but exposed as a primary product surface. Disclosed integrations include Groq, Unify, and Browser Use.
Hyperbrowser (YC W25; backers include Accel and SV Angel) ships a credit-based model — roughly 100 credits = 1 browser-hour ≈ $0.10. Stealth and CAPTCHA solving with randomized canvas/WebGL/UA fingerprints. The company’s positioning is “built from ground up for AI agents.”
Bright Data is the established incumbent. The Web Unlocker, Scraping Browser, Browser API, and Bright Data MCP server with 60+ tools and 5,000 free monthly requests anchor a per-GB proxy and per-success pricing model. The proxy network — 150M+ residential IPs — is the asset that’s hard to replicate. AIMultiple’s independent load test under 250 concurrent agents put Bright Data at 95% feature coverage and 95% success on multi-step tasks, the top score on that bench.
Apify rounds out the field with a 10,000+ Actor marketplace, compute-unit pricing at $0.25–0.30/CU, and an MCP server exposing the catalog. The underlying Crawlee library (Apache-2.0) is the OSS substrate that many third-party scrapers run on.
The benchmark reality
WebVoyager has saturated. Top-tier published scores are bunched: Magnitude self-reports 93.9% (with the caveat that its public github.com/magnitudedev/webvoyager README acknowledges requiring a patches.json to handle outdated tasks), Browserable 90.4%, Browser Use 89.1%, Skyvern 85.8%, OpenAI CUA 87%. Steel’s own leaderboard warns explicitly that “WebVoyager scores are approaching saturation. Scores above 90% are common enough that the benchmark no longer differentiates the top tier well.”
The harder benchmarks now matter more.
Web Bench, co-published by Skyvern and Halluminate in 2025, is the most demanding public reference: 5,750 tasks across 452 live sites, with state-mutating “write” operations where the agent must actually change something on the target. Skyvern’s 64.4% overall accuracy is the leading published number.
OSWorld tests AI models on real-world computer tasks - the benchmark Anthropic now leads on with Sonnet 4.5 at 61.4%, up from Sonnet 4’s 42.2% four months earlier.
BrowseComp, published by OpenAI on April 10, 2025, is a 1,266-question benchmark explicitly designed to be hard for browsing agents. At launch, OpenAI’s Deep Research model scored 51.5% while all other models scored below 10%.
Online-Mind2Web - 300 live tasks across 136 sites - is the newest entrant and currently the most realistic measure of multi-step web navigation.
The structural truth across all of this: vendor self-benchmarks dominate the public numbers, and every single 85%+ WebVoyager claim is vendor-self-reported. Treat any single-benchmark statistic as directional, not definitive.
The collapsing distinction
The hardest thing to communicate in a market map is the temporal axis. Where this looked like four genuinely different topologies twelve months ago, it now looks like a converging set of patterns that production teams combine.
Browserbase ships Stagehand (NL-DSL) plus Director (code-first workflow output) plus computer-use agent integration. Browser Use ships the for-loop agent (NL-DSL) plus the thin-CDP harness (CDP-only) plus bu-ultra (vision-augmented hosted model). Skyvern ships vision-CUA plus a planner-validator team plus workflow recording that produces deterministic replays. Anchor’s b0.dev does the same thing.
The pattern is converging on hybrid: the harness uses the LLM for build-time exploration, caches the deterministic skeleton, and falls back to vision-CUA only on the long tail where deterministic selectors don’t survive. Stagehand v3’s caching architecture, Anchor’s record-and-replay model, browser-use’s Tools.action cache, and Project Mariner’s Teach & Repeat are four implementations of the same underlying insight.
The implication for the next twelve months: pure topology arguments are going to look quaint. The interesting axis is the cache validation strategy, the fallback model, and the recovery primitives - not whether the harness is “code-first” or “vision-first.”
What to pick
For an engineering team picking a harness today, the right defaults are stable enough to commit to.
Default to a hybrid topology, not a pure one. Build the deterministic skeleton in Stagehand v3 (TypeScript) or browser-use (Python) - both ship caches and replay primitives. Reserve vision-CUA (Skyvern, Sonnet 4.5 computer-use, OpenAI computer-use-preview) for the tail of unknown or dynamic flows. Cache aggressively. Flip the default to vision-CUA only if your target sites are mostly canvas-only or have aggressive client-side rendering that defeats DOM extraction.
In regulated industries, default to code-first deterministic. Libretto’s pattern - generate Playwright code at build time, version-control it, audit it - is the cleanest match for healthcare, banking, insurance, and legal workflows where every action needs to be reviewable independent of an LLM. Use the model to author and repair, not to execute.
Outsource the browser infrastructure layer; don’t build it. The economics are clear: Browserbase Startup at $99/month plus $0.10/browser-hour beats running your own anti-bot-aware Selenium grid by an order of magnitude in total cost of ownership. For high-volume or regulated, use Browserbase Scale, Bright Data Scraping Browser, or Anchor. For data-sovereignty constraints, self-host Steel. At sustained concurrency above ~5,000 simultaneous sessions, self-hosting with Camoufox or nodriver starts to make financial sense.
Ship an MCP server, but don’t make it the only access path. Every harness in 2026 ships MCP. Coding-agent users expect it. But Microsoft’s own Playwright MCP team now points coding-agent users to CLI plus skills for token efficiency - “CLI invocations are more token-efficient: they avoid loading large tool schemas and verbose accessibility trees into the model context.” Build both: MCP for exploratory agent users, CLI plus skill files for production coding-agent integration.
Treat the auth model as a first-class architectural decision. Decide upfront: stored profile, just-in-time human handoff (1Password Secure Agentic Autofill), or direct-API replay. The blast-radius posture follows from this choice. Default to JIT handoff for any auth scope that includes state-mutating powers.
Instrument from day one. Steel’s session-replay-and-MP4 pattern, Browserbase’s session replay, Browser Use’s ClickHouse-via-Laminar - all three converge on the same answer: every step needs a video, a token cost, a latency, and a structured failure_reason. Without these, the harness cannot be debugged, replayed, or audited.
The collapse trajectory
The most important thing about this market is what it might look like in eighteen months. The foundation labs are pushing the model’s perception and action accuracy up at a rate the SDK layer cannot match. Sonnet 4.5’s OSWorld score jumped 19 points in four months. OpenAI’s o3-based CUA has folded into ChatGPT. Project Mariner has become a Chrome extension with parallel-task primitives.
The SDK layer is becoming a customer-acquisition channel for the browser-as-a-service layer. Stagehand → Browserbase. Browser Harness → browser-use Cloud. Skyvern OSS → Skyvern Cloud. Pure-OSS SDK companies will have a hard time monetizing without a coupled paid backend.
The harness layer is not going to disappear. State, replay, auth, observability, anti-bot, and concurrency are not problems that the model solves. They are problems the system around the model solves. But the abstractions over the model - the ones that wrapper the LLM with primitives, prompts, and DSLs - are on a collapse trajectory the way agent frameworks were eighteen months ago.
Sources include primary documentation from Browserbase, Browser Use, Skyvern, Saffron Health, Anthropic, OpenAI, Steel.dev, AIMultiple, and the Awesome Agents Web Agent Benchmarks leaderboard.