

The Eval Lifecycle: What Actually Happens Between “Proof of Concept” and “Production”
Most AI projects die in the gap between “it works on my laptop” and “it works in production.” The eval lifecycle is the bridge nobody teaches you to build.

TL;DR: OpenAI’s enterprise whitepaper quietly introduced a three-stage evaluation framework for AI agents — retrieval, summarization/grounding, and guardrails — with a continue/refine/stop gate at each stage. This framework is more important than anything else in the 25-page document, and the whitepaper spends exactly one table on it. Here’s the expanded version: how each eval stage actually works, what tools exist to run them, what “good” looks like at each gate, and how the entire lifecycle repeats at MVP, pilot, and production scale. If you’re building AI products, this is the technical architecture that determines whether your proof of concept ever graduates.
Why Evals Are the Whole Game
There’s a moment in every AI project where the demo works. The retrieval is pulling relevant chunks, the model is generating coherent answers, and the stakeholders are nodding. This moment is dangerous.
It’s dangerous because the gap between “works in a demo” and “works in production” is not a linear improvement problem. It’s a category shift. In a demo, you control the inputs, you cherry-pick the questions, and you evaluate by gut feel. In production, real users ask unpredictable questions against messy data, and you evaluate by numbers you’ve committed to in advance.
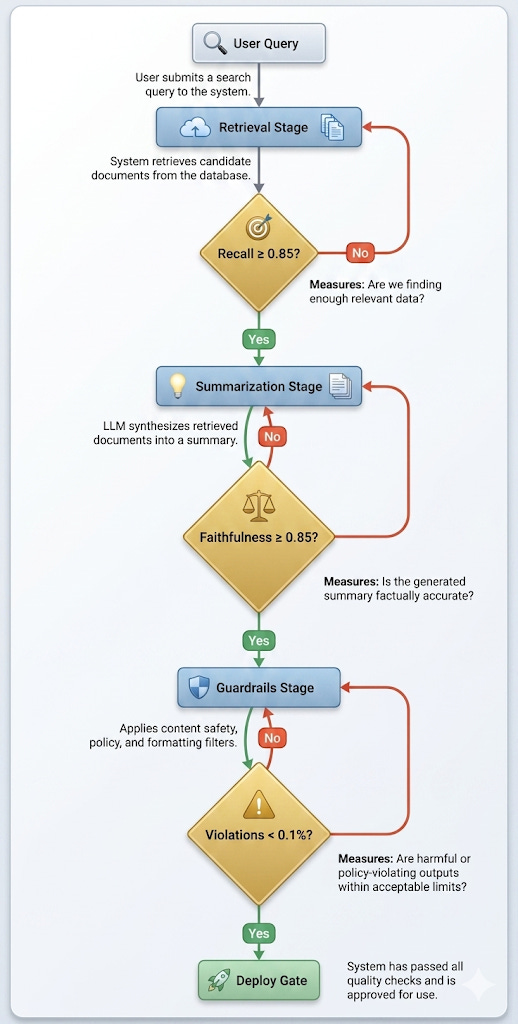
The eval lifecycle is the structured process that bridges this gap. OpenAI’s enterprise whitepaper sketches it in a single table. Let’s build the full architecture.
Stage 1: Retrieval Evaluation
Retrieval Evals
Each stage has its own metrics, its own evaluation set, and its own continue/refine/stop gate. The lifecycle repeats at MVP, pilot, and production scale — with the evaluation set roughly doubling at each stage.
The question: Does the system reliably find the right information?
This is where most AI products fail first — not because retrieval is hard to build, but because retrieval is hard to evaluate well. A retrieval system that returns plausible results will pass casual inspection. A retrieval system that returns the right results for edge cases is what separates a demo from a product.
What you’re measuring:
Recall — of all the documents that should have been retrieved, what fraction did the system actually find? Low recall means the system is missing relevant information. For a Q&A agent over company docs, this might mean missing the updated policy while retrieving the obsolete one.
Precision — of all the documents retrieved, what fraction are actually relevant? Low precision means the model’s context window is polluted with irrelevant material, degrading downstream generation quality.
Mean Reciprocal Rank (MRR) — is the most relevant document appearing first, or buried in position five? Models pay more attention to what appears early in context. If your best document consistently ranks third, your answers will be worse than they should be.
How you build the evaluation set:
Start with 50-100 representative queries drawn from actual user conversations (or realistic simulations). For each query, a domain expert labels which documents should be retrieved. This labeled set becomes your retrieval ground truth.
This is tedious and irreplaceable. Automated approaches — using an LLM to judge retrieval relevance — are useful for scaling evaluations but unreliable for building the initial ground truth. The domain expert knows that “Q3 revenue guidance” should retrieve the board deck, not the press release. The LLM doesn’t know your organization well enough to make that distinction.
The gate decision:
Continue if recall ≥ 0.85 and precision ≥ 0.75 on your evaluation set. Refine if metrics are between 0.60 and 0.85 — this usually means adjusting chunking strategy, embedding model, or retrieval parameters. Stop if recall is below 0.60 — the retrieval pipeline needs fundamental rework before downstream evaluation is meaningful.
Track token costs at this stage. Retrieving too many documents burns context window space and money. Retrieving too few misses information. The right balance is specific to your use case.
Stage 2: Summarization and Grounding Evaluation
The question: Does the system synthesize clear, consistent, useful, and cited answers? Did it follow the right steps and access the right data?
This is the stage where the whitepaper’s description — “evals on traces/logs + SME review” — is most dangerously compressed. “SME review” alone can mean anything from “my colleague glanced at five outputs” to “three domain experts independently rated 200 outputs on a structured rubric.” The difference in quality assurance is enormous.
What you’re measuring:
Faithfulness — does the answer only contain claims that are supported by the retrieved context? An answer can be correct according to the model’s training data but unfaithful to the retrieved context, which means it’s hallucinating in a way that’s invisible to the user. This is the most important metric in the entire eval lifecycle and the one most teams measure poorly.
Relevance — does the answer actually address the question? A faithfully grounded answer that doesn’t answer the user’s question is useless.
Completeness — does the answer cover all the relevant information from the retrieved context? Partial answers erode trust over time even when they’re technically accurate.
Citation accuracy — if the system claims “according to document X,” is that claim actually in document X? Citation errors are trust-destroying because they’re verifiable — a user who checks a citation and finds it doesn’t match will never trust the system again.
How you build the evaluation:
For each query in your evaluation set, have domain experts write the “gold standard” answer — the response a knowledgeable human would give. Then compare model outputs against these references.
Automated faithfulness evaluation is one of the areas where LLM-as-judge approaches are genuinely useful. Have a separate model (not the one generating the answer) check whether each claim in the output is supported by the retrieved context. Tools like RAGAS, DeepEval, and TruLens provide frameworks for this, but the key insight is: use a different model for evaluation than the one generating answers. Models are unreliable judges of their own outputs.
The gate decision:
Continue if faithfulness ≥ 0.85, relevance ≥ 0.80, and citation accuracy ≥ 0.90 on a sample of 200+ queries. Refine if faithfulness is between 0.70 and 0.85 — this usually means adjusting the system prompt to enforce stricter grounding, or improving the retrieval stage to provide better context. Stop if faithfulness is below 0.70. A system that hallucinates in 30%+ of responses is not ready for any form of user testing.
Stage 3: Guardrail Evaluation
The question: Does it stay within approved data, tone, and safety guidelines?
Guardrails get treated as an afterthought in most AI projects — the safety review that happens the week before launch. That’s backwards. Guardrail failures are the ones that make the news, generate legal liability, and destroy user trust in ways that no amount of accuracy improvement can repair.
What you’re measuring:
Topic boundary compliance — does the system stay within its defined scope? A legal Q&A agent that starts offering medical advice has failed a topic boundary guardrail, even if the medical advice happens to be accurate.
Tone and brand consistency — does the system’s voice match organizational guidelines? A customer-facing agent that suddenly becomes casual or sarcastic when asked difficult questions has a tone guardrail failure.
Safety filtering — does the system refuse or redirect harmful, offensive, or manipulative inputs? This isn’t just about explicit toxicity — it includes prompt injection attempts, jailbreaking, and social engineering.
PII handling — does the system avoid exposing, generating, or echoing personally identifiable information? This is both a safety and a regulatory requirement.
How you build the evaluation:
Create an adversarial test set. This is distinct from the representative test set used in stages 1 and 2. Adversarial tests specifically probe boundaries: out-of-scope questions, prompt injection attempts, requests for information the system shouldn’t have, edge cases where tone guidance is ambiguous.
A strong adversarial test set has 100+ cases across these categories, built by people who actively try to break the system. This is one area where “red teaming” (having humans try to elicit harmful outputs) provides signal that automated evaluation cannot replicate.
The gate decision:
Continue if guardrail violation rate < 0.5% on the adversarial test set and < 0.1% on the representative test set. Refine if violations are between 0.5% and 2% — usually by tightening the system prompt, adding output filters, or restricting tool access. Stop if violation rate exceeds 2% on the adversarial set. Safety is not a gradient.
The Lifecycle Repeats at Every Scale
Here’s what the whitepaper mentions but doesn’t emphasize enough: this three-stage evaluation runs at every deployment gate, not just once.
MVP gate: Run all three stages on your evaluation set. Small scale (50-100 queries for retrieval, 200 for summarization, 100 adversarial). The goal is to validate the architecture, not achieve production quality.
Pilot gate: Re-run with production data from pilot users. The evaluation set should now include real queries you didn’t anticipate. Expand the adversarial set based on actual user behavior. Introduce latency and cost measurements — a system that takes 30 seconds per response won’t be adopted regardless of accuracy.
Production gate: Full evaluation suite plus continuous monitoring. This is where the eval lifecycle transitions from a build activity to an operational responsibility. The same metrics you used to gate deployment now become the SLOs your team monitors daily.
The whitepaper’s “once proven in a narrow scope, the same checks repeat at pilot and production scale” is correct, but it undersells the expansion that happens at each gate. Your evaluation set should roughly double at each stage. Your adversarial set should incorporate everything users tried during the previous stage. And your automated monitoring should replace the manual SME review that gates earlier stages.
The Tooling Stack
You don’t need to build this from scratch. The eval tooling ecosystem has matured significantly:
Retrieval evaluation: RAGAS and DeepEval both provide retrieval metrics out of the box. LangSmith and Arize Phoenix offer tracing that connects retrieval to downstream generation quality.
Faithfulness and grounding: RAGAS faithfulness metrics, DeepEval’s hallucination detection, and custom LLM-as-judge evaluations using structured prompts. Braintrust and HumanLoop provide platforms for managing evaluation datasets and running automated evals at scale.
Guardrails: Guardrails AI, NeMo Guardrails (NVIDIA), and Lakera Guard for safety filtering. LangFuse for observability and trace-level analysis.
End-to-end: LangSmith, Braintrust, and Arize Phoenix each provide integrated platforms that span all three stages, with tracing, evaluation, and monitoring in a single tool.
Pick one end-to-end platform and supplement with specialized tools where needed. The worst outcome is building a custom evaluation framework from scratch — you’ll spend months replicating what these tools provide on day one.
The Real Lesson
The whitepaper frames evaluation as Phase 4 — something that happens when you build products. That’s wrong. Evaluation is the connective tissue that links every phase.
Your Phase 1 data access decisions determine whether you can build a retrieval evaluation set. Your Phase 2 fluency programs determine whether you have SMEs capable of writing gold-standard answers. Your Phase 3 prioritization determines whether you’ve chosen use cases where evaluation is tractable.
The eval lifecycle isn’t a step in the process. It’s the process.
The gate thresholds in Stage 2 are the most underappreciated part of this framework. Most teams treat faithfulness as a vibe check, a few example outputs, some nodding in a meeting, rather than a metric with an explicit cutoff. The consequence is exactly what you describe: systems that pass "SME review" in the loose sense but fail in production because nobody committed to a number.
One thing I'd add: the evaluation set composition matters as much as the size. 200 queries drawn from the happy path is not the same as 200 queries that stress the boundaries of your retrieval design. Teams that double the set size at each gate without changing the distribution tend to get confident about the wrong things.
Writing about the correctness side of this, specifically how systems degrade silently in production after passing all three gates, in my newsletter if you're interested. The eval lifecycle gets you to launch. Staying correct post-launch is a different problem.