

The Responses API Is OpenAI’s Bet That State Belongs on the Server
OpenAI’s new API primitive replaces three years of duct tape with one opinionated call. Here’s every feature that matters, what it fixes, and how to migrate a real customer support system.

TL;DR - OpenAI launched the Responses API in March 2025 to replace both Chat Completions (for new projects) and the Assistants API (sunsetting August 2026). The core bet: move conversation state, reasoning token persistence, and tool execution to the server so developers stop rebuilding the same plumbing. The result is 40–80% better cache utilization than Chat Completions, chain-of-thought that survives across turns, built-in tools (web search, file search, code interpreter, computer use, MCP), and a compaction system that lets agents run beyond the context window. If you’re building anything multi-turn on OpenAI today, the Responses API isn’t optional — it’s the surface where new capabilities land first.
The Problem the Responses API Solves
Every developer who has built a production chatbot on the Chat Completions API knows the ritual. User sends a message. You fetch the entire conversation history from your database. You prepend the system prompt. You serialize the whole thing into a messages array. You send it. You get a response. You store it. Next turn, you do it all again — with one more message appended.
This works. It also wastes money, breaks prompt caching, and throws away the model’s reasoning between turns.
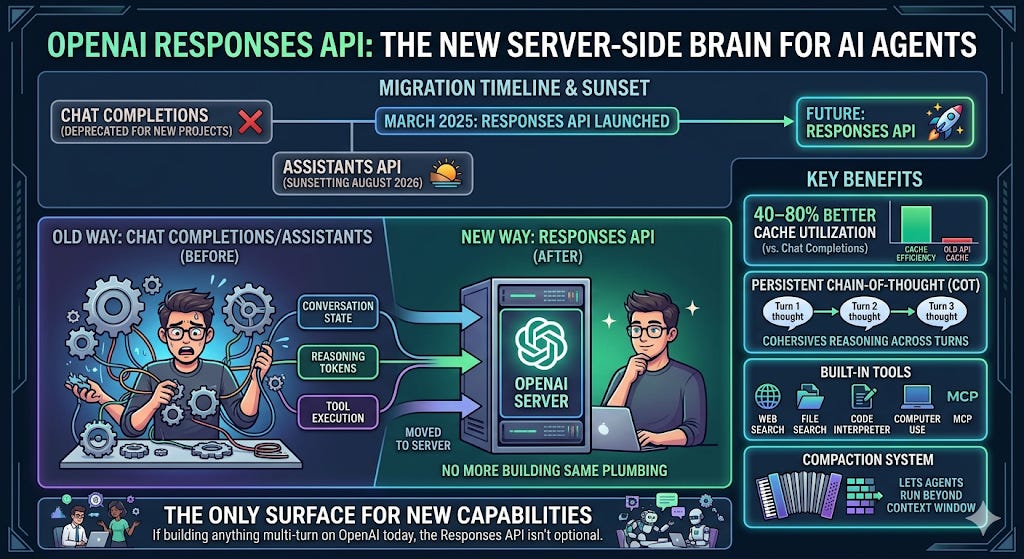
Responses API
The Assistants API tried to fix this in late 2023 by moving state server-side. Persistent threads. Managed runs. Built-in tools. The abstraction was right, but the execution was painful: creating a thread, adding a message, kicking off a run, polling for completion, then finally retrieving the response. Five API calls for one answer. Rate limits tied to threads. Opaque state that was hard to debug. And because no other provider implemented the Assistants API, adopting it meant full vendor lock-in to a perpetual beta.
The Responses API is OpenAI’s second attempt. It takes the right ideas from Assistants — server-side state, built-in tools, persistent reasoning — and delivers them through the simplicity of a single API call. No threads. No runs. No polling.
Every architectural choice has a regime where it’s right and a regime where it’s wrong. Stateless APIs were the right answer for the workloads LLMs were first built against: classification, single-turn Q&A, one-shot generation. What you sent was what you paid for, and the abstraction was symmetric, clean, and cheap to reason about.
Agentic systems break that regime. An agent isn’t a classifier — it’s a sequential decision process in which every step depends on the reasoning, tool calls, and results of every prior step. Forcing that shape onto a stateless API creates what I call the Stateless Tax — three compounding costs that scale with conversation depth and never appear as a single line item on your bill.
Replay cost is the visible one. A 20-turn conversation resends 20 messages every turn, with the system prompt bolted to the front each time. Prompt caching is supposed to fix this, and does — until a single dynamic token at the start of the prefix shatters the cache and you’re paying full freight again. The longer the agent runs, the larger the tax, and the more fragile the mitigation.
Reasoning amnesia is the cost most developers never see. GPT-5 and o3 generate hidden chain-of-thought tokens that shape the final answer. On a stateless API, those tokens are discarded the moment the response returns. Next turn, the model reasons from absolute zero — not from where it left off. The conversation looks continuous to the user; the cognition restarts on every call. This is why OpenAI’s own evals show a ~3% SWE-bench lift and a ~4-point Tau-Bench Retail gain just from switching APIs, with no model change. Persisting reasoning isn’t a minor optimization. It’s the model being functionally smarter, because it stops getting wiped between turns.
Observability debt is the silent one. Stateless APIs return a final message; everything between input and output — tool calls, reasoning items, retrieval decisions — is opaque by construction. You can reconstruct it with careful logging, but you’re rebuilding state the API already had and discarded. In production debugging, this is the difference between a stack trace and a single error code.
Server-managed state collapses all three costs into a single API primitive. Response chains eliminate replay. Reasoning items persist cognition across turns. Typed output items turn every step the agent took into an inspectable artifact.
This is why calling the Responses API “a better Chat Completions” undersells what actually happened in March 2025. It’s the first major commercial inference API to treat agentic workloads as a distinct architectural category — one where statelessness isn’t the clean default. It’s a misconfiguration that gets more expensive the longer your agent runs.
The Nine Features That Matter
1. Server-Side State via store and previous_response_id
This is the single biggest architectural change. With Chat Completions, you resend the entire conversation every turn. With the Responses API, you set store: true and the server remembers. On the next turn, pass previous_response_id instead of the full history.
# Turn 1
response1 = client.responses.create(
model="gpt-5",
store=True,
instructions="You are a customer support agent for Acme Corp.",
input="What's your return policy for electronics?"
)
# Turn 2 — no history resending needed
response2 = client.responses.create(
model="gpt-5",
store=True,
previous_response_id=response1.id,
input="What if I lost the receipt?"
)Response objects are saved for 30 days by default. You can delete them explicitly with client.responses.delete(response_id). For organizations with Zero Data Retention requirements, OpenAI provides encrypted reasoning items — you get the reasoning persistence benefit without server-side storage.
Why this matters: A 20-turn customer support conversation on Chat Completions resends 20 messages every turn. On the Responses API, you send exactly one: the new user input. The server handles the rest.
2. Reasoning Token Persistence
This is the feature most developers don’t know they’re missing.
When you use a reasoning model like GPT-5 or o3 through Chat Completions, the model generates chain-of-thought tokens during inference. But those tokens aren’t returned to you. On the next turn, the model starts reasoning from scratch — like a detective who forgets all the clues every time they leave the room.
With the Responses API’s previous_response_id, reasoning tokens from the previous turn survive into the next turn. The model builds on its prior thinking instead of starting over.
OpenAI’s internal evals show a 3% improvement on SWE-bench with the same prompt and setup when using Responses instead of Chat Completions. That number sounds modest, but on agentic benchmarks like TAU-bench the gap widens to 5%, because multi-step reasoning tasks compound the benefit of persistent chain-of-thought.
3. Built-In Tools
Chat Completions gives you function calling — you define schemas, the model returns tool_calls, you execute them, you send results back. Every tool call is a round trip through your backend.
The Responses API adds hosted tools that OpenAI executes for you:
response = client.responses.create(
model="gpt-5",
instructions="You are a research assistant.",
input="What were the key announcements at GTC 2026?",
tools=[
{"type": "web_search"}, # OpenAI runs the search
{"type": "code_interpreter"}, # OpenAI runs the code
{"type": "file_search"}, # OpenAI searches uploaded files
{"type": "computer_use"}, # Model interacts with UIs
{"type": "mcp"}, # Connect to external MCP servers
]
)Because tool execution happens server-side for hosted tools, you eliminate the round-trip latency of bouncing every call through your own backend. You can still define custom function tools alongside the hosted ones — the two compose naturally.
The web_search tool uses the same models powering ChatGPT search, which score around 90% accuracy on the SimpleQA benchmark — dramatically better than plain GPT models without search. File search integrates with OpenAI’s vector stores for a RAG pipeline without custom infrastructure. And the MCP tool connects to any Model Context Protocol server, meaning your agent can interact with external services through a standardized interface.
4. The instructions Parameter Replaces System Messages
Chat Completions overloads the messages array with a system role message. The Responses API separates concerns: instructions define what the model is, input defines what the user asks.
response = client.responses.create(
model="gpt-5",
instructions="You are a tax assistant. Always cite relevant IRS publications.",
input="What deductions can I claim for my home office?"
)This isn’t just cosmetic. Because instructions sit at the start of the context as a stable prefix, they cache far more effectively than a system message buried in a mutable messages array. The architectural separation between static identity and dynamic conversation is what enables the 40–80% cache improvement OpenAI reports in internal tests.
5. Output Items Instead of Choices
Chat Completions returns a choices array where each choice contains a single message. The Responses API returns an output array of typed items. A single response can contain reasoning items, tool calls, tool results, and the final message — all as separate, inspectable objects.
output: [
{ type: "reasoning", ... }, # Chain-of-thought (if visible)
{ type: "tool_call", ... }, # Tool invocation
{ type: "tool_result", ... }, # Tool output
{ type: "message", ... }, # Final text response
]This is transformative for debugging and observability. With Chat Completions, tool execution is a black box — you see what went in and what came out, but the intermediate steps are invisible. With Items, you get receipts. Every step the model took is an inspectable object in the response. You can build richer UIs, structured audit logs, and step-by-step tracing from a single response.
6. The Conversations API
For applications that need durable, long-lived conversations — think customer support tickets that span days — the Conversations API provides a persistent container:
# Create a persistent conversation
conversation = client.conversations.create(
metadata={"user_id": "user_123", "session_type": "support"}
)
# Use it across multiple responses
response = client.responses.create(
model="gpt-5",
store=True,
conversation=conversation.id,
input="How do I reset my password?"
)Conversations persist indefinitely (no 30-day TTL like standalone responses). You can retrieve all items from a conversation, fork it at any point, and resume across sessions and devices. It replaces the Assistants API’s Threads concept without the polling overhead.
7. Compaction for Long-Running Agents
Every agentic workflow eventually hits the context window ceiling. The Responses API introduces compaction — an intelligent summarization of older conversation content to make room for new work while preserving critical context.
Two modes are available. Server-side compaction triggers automatically when the context crosses a threshold you set:
response = client.responses.create(
model="gpt-5.4",
input=conversation_history,
store=False,
context_management=[{
"type": "compaction",
"compact_threshold": 200000
}]
)Client-side compaction gives you explicit control via the /responses/compact endpoint — you send a full context window, and the API returns a compressed version with an encrypted compaction item that carries forward key state.
This is what enables GPT-5.4 to sustain coherent progress across agent trajectories that would previously collapse when the context window filled up. The compaction endpoint is fully stateless and ZDR-friendly.
8. Tool Search for Large Tool Surfaces
If your agent has 50+ function definitions, sending all of them in every request wastes tokens, breaks cache prefixes, and degrades tool selection accuracy. GPT-5.4 introduces tool search: deferred tool loading where the model dynamically discovers relevant tools at runtime.
Instead of defining every tool upfront, you make tools searchable. The model loads only the definitions it needs for the current request. This preserves cache performance, reduces token usage, and improves latency for enterprise applications with large tool inventories.
9. Flexible Input Formats
Chat Completions requires a messages array with role and content objects. The Responses API accepts three formats:
# Simple string
input="What is the return policy?"
# Message array (familiar from Chat Completions)
input=[{"role": "user", "content": "What is the return policy?"}]
# Multimodal input with images, audio, documents
input=[
{"role": "user", "content": [
{"type": "input_text", "text": "Summarize this document"},
{"type": "input_file", "file_id": "file_abc123"}
]}
]The string shorthand eliminates boilerplate for simple single-turn calls. The multimodal support makes text, images, PDFs, and audio first-class citizens in the same input array.
Case Study: Migrating a Customer Support RAG System
Let’s make this concrete. Consider a mid-size e-commerce company running a customer support bot on Chat Completions with GPT-4o. Here’s their current architecture and what changes with a Responses API migration.
The Before: Chat Completions Architecture
User message arrives
→ App fetches full conversation history from Postgres (all turns)
→ App prepends system prompt (800 tokens of instructions)
→ App calls embeddings API with the user's question
→ App queries Pinecone for relevant knowledge base chunks
→ App injects retrieved chunks into the messages array
→ App sends everything to Chat Completions
→ App parses response
→ App stores response in Postgres
→ If tool call: app executes tool, sends result back, waits again
→ Repeat for every turnThe pain points: Every turn resends the full conversation (0% prompt cache hit rate). The system prompt is 800 tokens of static instructions re-sent identically every request. RAG requires a separate embeddings call plus a vector DB query before every API call. Tool execution requires multiple round trips. A 15-turn conversation means the system prompt alone costs 12,000 redundant tokens. And the model’s reasoning resets between every turn.
The After: Responses API Architecture
User message arrives
→ App sends one API call with previous_response_id + new input
→ Built-in file_search handles RAG (vector store configured once)
→ Built-in web_search handles real-time queries
→ Model's reasoning persists from prior turns
→ Static instructions cached via `instructions` parameter
→ Response returned with full item trail for observability
→ RepeatWhat You Actually Save
Token costs: The instructions parameter creates a stable prefix that caches across turns. OpenAI’s extended prompt cache retention (up to 24 hours) means the system prompt stays cached throughout a support agent’s entire shift. For a 15-turn conversation, you eliminate roughly 12,000 redundant instruction tokens and gain 40–80% cache improvement on the remaining context.
Infrastructure: You can retire your Pinecone instance (or equivalent) for this use case — file search with vector stores handles the RAG pipeline. You eliminate the embeddings call, the vector query, and the chunk injection logic.
Quality: Reasoning persistence means the model remembers not just what was said, but how it was thinking about the problem. When a customer asks a follow-up that builds on a complex refund calculation, the model’s prior chain-of-thought carries forward instead of starting from scratch.
Observability: Every response contains typed output items — you can log exactly which knowledge base documents were retrieved, which tools were called, and what reasoning the model applied, all from a single response object.
The Migration Decision Matrix
Not every application should migrate today. Here’s how to think about it:
Migrate now if you have multi-turn conversations with reasoning models, applications resending full conversation history every turn, workflows that need built-in web search or file search, or agentic systems hitting context window limits.
Migrate incrementally if you have a mix of simple and complex flows. The Responses API is a superset of Chat Completions — you can migrate individual user flows that benefit from reasoning persistence while keeping simpler flows on Chat Completions.
Wait and watch if you have single-turn, stateless workloads with no tools (basic classification, single-shot generation). Chat Completions handles these fine and will be supported indefinitely.
Be cautious if your architecture requires full control over conversation state for compliance reasons, though encrypted reasoning items and ZDR support address most of these concerns.
The Assistants → Responses Concept Map
If you’re migrating from the Assistants API (sunset: August 26, 2026), the mapping is straightforward:
Assistants API → Responses API
─────────────────────────────────────────────
Assistant object → instructions + model + tools (inline config)
Thread → Conversation (or previous_response_id chain)
Message → Input items
Run (create → poll → get) → Single responses.create() call
Run Steps → Output items (inspectable per-step)
Code Interpreter → {"type": "code_interpreter"} built-in tool
File Search / Retrieval → {"type": "file_search"} built-in tool
Thread-based state → store: true + conversation or previous_response_idThe biggest win: you go from a five-step async flow (create thread → add message → create run → poll status → get response) to a single synchronous API call that returns the complete result.
What to Watch
The Responses API is clearly where OpenAI is investing. New capabilities — tool search, compaction, computer use, MCP support — are landing in Responses first, sometimes exclusively. GPT-5.4’s tool calling with reasoning: none is only supported in the Responses API, not Chat Completions.
But there are trade-offs to keep eyes on. Server-side state means you’re trusting OpenAI with your conversation data (responses are retained for 30 days by default). The in-memory fast path caches only the most recent response; older IDs are hydrated from persisted state when store: true, and if unresolvable you must fall back to full context. And despite being billed as simpler, the Items-based response format is a different mental model that takes adjustment.
The broader signal is architectural. OpenAI is pushing developers toward a world where the API provider manages state, runs tools, and handles context — and developers focus on defining behavior and building UIs. Whether that trade-off works for your stack depends on how much control you’re willing to delegate.
But for the majority of applications resending full conversation histories and rebuilding tool execution loops from scratch — the Responses API isn’t just an improvement. It’s the API you wished existed three years ago.
Building on the Responses API or migrating from Assistants? I’d love to hear what’s working and what’s breaking.