

The "Self-Improving" AI Myth (And What 60 Production Deployments Actually Do)
Sixty production deployments converged on a three-layer architecture where the eval surface, not the base model, is the moat.

TL;DR - Self-improving AI agents in 2026 do not improve through model weight updates. They improve at the harness layer (orchestration, evaluation, A/B gating) and the context layer (per-tenant memory and skill libraries). Sixty production deployments across customer support, devtools, legal, healthcare, finance, sales, recruiting, and real estate converged on this architecture. The vertical leaders win by owning the loop inside the product, not by training a better base model. The biggest unfilled opportunity is the horizontal self-improvement engine, no vendor sells one. Build in a vertical: invest in eval surface and outcome-based pricing. Build horizontally: ship the packaged loop that plugs into any agent stack.
What “self-improving” actually means in production
The “self-improving agent” label is doing heavy lifting in 2026 product marketing. The label conflates four very different mechanisms: weight updates from production traces, harness changes shipped after A/B testing, per-tenant context that accumulates from user interactions, and procedural skill libraries that compound across sessions. Most products marketed as “self-improving” do exactly one of these, usually the third, and stop there.
Across the production landscape, the dominant pattern is harness plus context. Real model weight updates are concentrated in a handful of companies with proprietary data flywheels: Hippocratic AI versions its Polaris suite with documented progression from 96.79% to 99.38% clinical accuracy on its RWE-LLM safety benchmark, EvenUp trained Piai on hundreds of thousands of personal-injury cases, Abridge ships custom medical speech recognition across fourteen languages, and Harvey co-developed a case-law model with OpenAI. Everyone else differentiates at the harness and context layers.
The model layer is where a small number of verticalized leaders defend a moat. The harness layer is where every serious player wins or loses the production loop.
The three-layer architecture
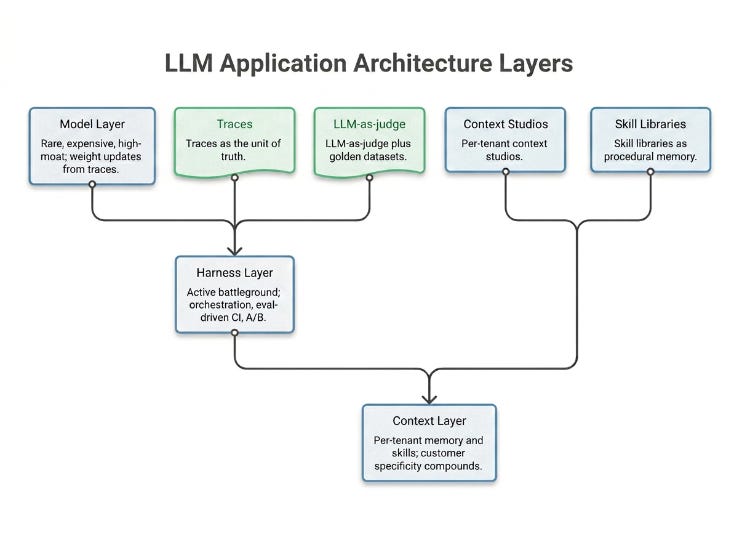
The three-layer model, popularized by LangChain in early 2026 and now widely adopted, separates what changes in an LLM system into model, harness, and context. Each layer has its own improvement surface, its own cost curve, and its own failure modes.
Model layer: rare, expensive, high-moat. True weight updates from production traces. The pattern is consistent across the four companies that do this: own a proprietary data flywheel, build a benchmark, ship versioned models. Glean’s Waldo agent runs on Nemotron 3 Nano. Most enterprises buy frontier models and never touch the weights.
Harness layer: the active battleground. The orchestration, evaluation, retry, gating, and reflection logic that constrains and verifies model behavior before output reaches the user. This is where almost all 2026 differentiation lives. Cursor publishes harness-improvement details openly, measuring releases against an internal CursorBench plus an offline grader plus online A/B with Code Retention and Keep Rate as proxies. Anthropic documents Claude Code’s harness evolution across released versions. Decagon’s Agent Operating Procedures are a harness in disguise. The term “harness engineering” has moved from Anthropic-internal vocabulary to industry-standard framing.
Context layer: where customer specificity compounds. Per-tenant memory, knowledge packs, skill libraries, and tool manifests. Every serious vertical agent has a context studio: Sierra Explorer, Decagon Duet, Hex Context Studio, Ada Coaching, Intercom Procedures, Harvey Memory. This layer is where customer-specific value compounds, and where the multi-tenant safety problem lives.
The model layer is where vertical leaders defend a moat. The harness layer is where every serious player wins or loses the production loop.
Harness Topology applied across sixty deployments
Harness Topology is the comparative discipline of analyzing harness shape across regulated industries, used to identify which harness design patterns generalize across verticals and which are domain-locked. Built on Vertical Agent Anatomy, applied cross-vertically. Inside it sit two named concepts: Harness Half-Life (the durability axis: how fast harness investment depreciates as the model evolves) and Harness Saturation (the viability threshold: the point at which a system labeled an “agent” is a deterministic workflow with an LLM bolted on).
Applied empirically across roughly sixty production deployments in 2026, Harness Topology reveals nine patterns that repeat across every leading vertical agent. A vertical agent that does not implement at least seven of them is missing a core mechanism.
Traces as the unit of truth. Every serious shop treats execution traces as the artifact that drives improvement. LangSmith, Langfuse, OpenTelemetry GenAI conventions, and Cursor’s internal trace store all encode this.
LLM-as-judge plus golden datasets. Glean’s internal AI Evaluator hits 74% human agreement rate; Harvey’s LAB benchmark uses rubric-based LLM grading; Cursor’s CursorBench and Decagon’s simulation suite combine LLM judges with human review.
Per-tenant context studios. Sierra Explorer, Decagon Duet, Hex Context Studio, Ada Coaching, Intercom Procedures, Harvey Memory. Every leader has one; nobody sells one as a horizontal product.
Skill libraries as procedural memory. Anthropic’s Agent Skills standard (SKILL.md plus scripts) is being copied by Replit, Devin, OpenHands, and Cursor Rules. An open-source marketplace ecosystem already exists at scale.
A/B harness experimentation on real traffic. Cursor A/Bs harness variants and measures Code Retention. Intercom A/Bs Fin against production baselines on every change. Decagon versions and simulates conversations before deployment.
Outcome-based pricing aligned with the improvement loop. Sierra charges only on full resolution; Intercom Fin charges per resolution; EvenUp’s pricing is tied to settlement outcomes. The loop is structurally aligned with the customer metric.
Offline “dreaming” jobs. Coding agents that run nightly over recent traces, propose harness or context changes, and gate against an eval suite. Sierra Explorer, Decagon Duet, Intercom Optimize, and Cursor’s harness-improvement agent are all variants.
Vertical benchmarks as the eval moat. Harvey’s LAB, Mercor’s APEX-Agents (open-sourced on Artificial Analysis), Hippocratic’s RWE-LLM. The benchmark itself becomes a competitive asset distinct from the product.
Workflow / SOP ingestion as cold-start. Sierra Ghostwriter, Decagon AOPs, Ada Playbooks, Harvey Workflow Agent. Natural-language SOPs and call transcripts bootstrap the first agent before any improvement loop has data.
The patterns are not fashionable. Each one closes a specific failure mode. A vertical agent missing trace infrastructure cannot improve at all. A vertical agent without a golden dataset cannot ship harness changes safely. A vertical agent without per-tenant context cannot survive contact with the customer’s idioms. The list is functional, not aesthetic.
The five standardized axes that turn rebuild into configuration
Across verticals, the leaders also converge on five standardized axes that turn vertical onboarding from rebuild into configuration. Each axis is a slot in a generic agent kernel, planner, memory, tool router, critic, that gets filled with vertical-specific configuration.
1. Workflow / SOP ingestion as the bootstrap. Sierra Ghostwriter ingests existing SOPs and transcripts. Mercor Enterprise runs AI-moderated interviews with employees to extract tacit workflows. Harvey requires firm-specific upload of precedents before work begins.
2. MCP / connectors as the tool layer. MCP has effectively won as the integration standard. Clay’s Claygent connects to any MCP server. Devin and Cursor expose MCP marketplaces. Glean ships over 100 connectors. The tool layer is no longer differentiation; the manifest is.
3. Per-tenant context store. Universal pattern. Customer-specific knowledge, working style, precedents, and learned patterns isolated per tenant. The audit surface lives here.
4. Vertical benchmarks as the eval moat. Harvey’s LAB, Mercor’s APEX-Agents, Hippocratic’s RWE-LLM. The benchmark itself is the competitive asset. Harder to copy than a feature; compounds over time.
5. Outcome-based pricing. Sierra and Intercom Fin price on resolution; EvenUp ties to settlement outcomes. Pricing structurally aligns the improvement loop with the customer’s metric, the agent that improves the customer’s outcome also improves its own revenue.
These five axes are what makes the harness layer the active battleground. A vertical agent with a strong eval suite and outcome-based pricing has a self-tuning revenue model. A vertical agent without them has shipped a demo.
What the numbers actually say
Most of the cited improvement numbers in the 2026 self-improving agent market are vendor-published. Treat them as directional. Where independent benchmarks exist, the picture is less flattering than the marketing.
Hebbia’s Matrix shows 92% accuracy with o1 versus 68% out-of-the-box RAG on a legal/financial benchmark, a vendor-published number on a vendor-defined benchmark. Cognition reports Devin 2.0 is 83% more productive than 1.x per Agent Compute Unit, also vendor-published, with no methodology release. Intercom Fin reports 51% average resolution across its customer base, with Lightspeed at 65% end-to-end and Synthesia at 87% self-serve, customer-reported, but mediated through Intercom’s product analytics.
The independent benchmark numbers tell a different story. Mercor’s APEX-Agents benchmark, 480 tasks across investment banking, consulting, and law, released open-source, shows frontier models scoring roughly 33%, a large gap to humans. OpenHands reports about 77% on SWE-Bench Verified with Sonnet 4.5. The verticals where independent benchmarks are publicly available are the verticals where the production gap is widest.
The reading is consistent with Harness Topology’s central claim: harness investment is what closes the gap between frontier-model benchmark score and customer-outcome resolution rate. The customer cares about resolution rate. The model cares about benchmark score. The harness is what translates one into the other.
Where the pattern saturates
Harness Saturation is the viability threshold inside Harness Topology, the point at which a system labeled an “agent” is actually a deterministic workflow with an LLM bolted on, because the harness has accumulated so many gates, verifications, and constraints that no autonomous decision remains. The end-of-agent signal: every decision is gated, every output is validated, every action requires approval, and the LLM call is reduced to a structured-output formatter.
The most regulated verticals are closest to saturation. Healthcare clinical-decision agents and legal demand-letter agents have so many compliance gates that the autonomous surface has collapsed to schema completion. Customer support is further from saturation because the customer’s tolerance for a wrong answer is higher than the patient’s. Devtools is furthest from saturation because the human reviewer is in the loop on every change.
Saturation matters because it tells the practitioner when to stop adding harness. Adding more gates past saturation degrades completion rates without lowering incident rates. The engineering-correct move is to drop the LLM and ship the deterministic workflow it became.
The biggest unfilled opportunity
The vertical-agnostic self-improvement engine does not exist as a product. Every serious vertical agent runs a version of the same loop: trace → cluster failures → propose context or skill update → gate against eval suite → ship. Sierra Explorer, Decagon Duet, Intercom Optimize, and Cursor’s harness-improvement coding agent all implement variants. None is sold as a horizontal product.
That is the largest single opening in the territory. A packaged self-improvement loop, plugging into any agent stack via traces, producing per-tenant context and skill updates that any eval suite can promote, would slot into every vertical without rebuilding the loop. The market readiness is high; the competitive whitespace is wide; the product does not exist.
The closest adjacent products are observability platforms (LangSmith, Langfuse), Anthropic’s Agent Skills registry which crossed 277,000 installs on the frontend-design skill alone, eval platforms (Braintrust, HoneyHive), and memory products (Mem0, Zep, Letta). None of them ships the full loop. The observability platforms see traces but do not propose changes. The eval platforms score outputs but do not generate updates. The memory products store context but do not curate skills.
A horizontal self-improvement engine sitting between these three would be the missing keystone. It is the single most valuable position in the 2026 agent landscape that no vendor occupies.
The three-layer stack, visualized
FAQ
Where does self-improvement actually happen in 2026 agents?
At the harness and context layers, not the model layer. The harness layer covers orchestration, evaluation, retry logic, A/B testing, and reflection loops. The context layer covers per-tenant memory and procedural skill libraries. Real model weight updates from production traces are concentrated in four to six companies, Hippocratic AI, EvenUp, Abridge, Harvey, Glean, and require a proprietary data flywheel that most enterprises do not have.
What is the difference between Harness Engineering and Context Engineering?
Harness Engineering controls what the user sees: the gates, verifications, and orchestration logic that constrain model behavior before output reaches the user. Context Engineering controls what the model knows: every method of getting information to the LLM at inference time, including RAG, fine-tuning, long-context injection, prompt design, MCP tool use, and persistent memory. Both sit inside Model Reliability Engineering, the broader discipline of making LLM behavior reliable in production.
Why has no horizontal self-improvement product emerged?
Because the eval surface is vertical-specific. A self-improvement loop is only as good as the eval suite that gates its proposed changes, and every vertical defines correctness differently, clinical accuracy in healthcare, citation faithfulness in legal, resolution rate in customer support, Code Retention in devtools. A horizontal product would need a configuration surface that accepts any eval definition, plugs into any agent stack via traces, and produces context or skill updates that any deployment can promote. That surface is hard to design and harder to sell into without a category to lean on.
What does a vertical leader build before the improvement loop exists?
Workflow ingestion. Every leader starts the same way: ingest existing SOPs, call transcripts, audio recordings, or expert demonstrations, and turn them into agent behavior. Sierra’s Ghostwriter is the canonical example. Mercor Enterprise runs AI-moderated interviews with employees to extract tacit workflows. Harvey requires firm-specific precedent upload before work begins. The improvement loop only starts producing value once enough traces have accumulated; the first agent has to ship from the cold-start.
How does Harness Saturation get diagnosed in practice?
Three indicators compound. First, every decision in the agent’s path is gated by a deterministic check. Second, every output is validated against a fixed schema. Third, every action requires human or rule-based approval. When all three are present, the LLM call has been reduced to a structured-output formatter, and the autonomous decision surface has collapsed. The engineering-correct response is to drop the LLM and ship the deterministic workflow the harness has become. Adding more harness past this threshold degrades completion rates without improving incident rates.
The two open positions
The architecture has settled. The leaders have converged. The opportunity has narrowed to two clean positions and one unfilled gap.
For vertical builders, the moat compounds in the eval surface and the customer-outcome metric. Capital invested in proprietary benchmarks and outcome-aligned pricing returns more than capital invested in fine-tuning the base model. The four to six companies running real weight-update loops are the exceptions that prove the rule: they own data flywheels nobody else can replicate, and even then the differentiation visible to the customer is harness-mediated. Vertical leaders without the data flywheel should stop trying to compete on model and start competing on benchmark depth and pricing structure.
For horizontal builders, the territory open in 2026 is the packaged self-improvement loop. Any product that plugs into an agent stack via traces, produces per-tenant context and skill updates, and gates them against the customer’s existing eval suite occupies a position no vendor currently holds. Observability sees the traces, eval platforms score outputs, memory products store context, but none ships the full loop. The market is ready, the configuration surface is hard but tractable, and the first credible category entry will define how every vertical agent procures self-improvement for the next decade.
A subscriber brief mapping the full sixty-deployment landscape, the nine cross-cutting patterns, the three-layer memory stack, the mechanism catalog, and the opportunity map is available below:

Interesting analysis, but it still assumes that improving AI systems is primarily an engineering problem.
Whether improvement happens in model weights, harnesses, context layers, memory stores, or evaluation loops misses the more fundamental question:
"Who holds decision authority?"
A system can have perfect traces, benchmarks, evaluations, memory, and self-improvement mechanisms, yet remain ungovernable if intelligence is allowed to authorize actions.
From an IFA perspective, the real architecture is not:
Model → Harness → Context
https://tauguard.xyz/