Three Weeks of Opus 4.7 in Production: What Teams Are Actually Reporting
The launch numbers were one story. The production patterns are a different one.

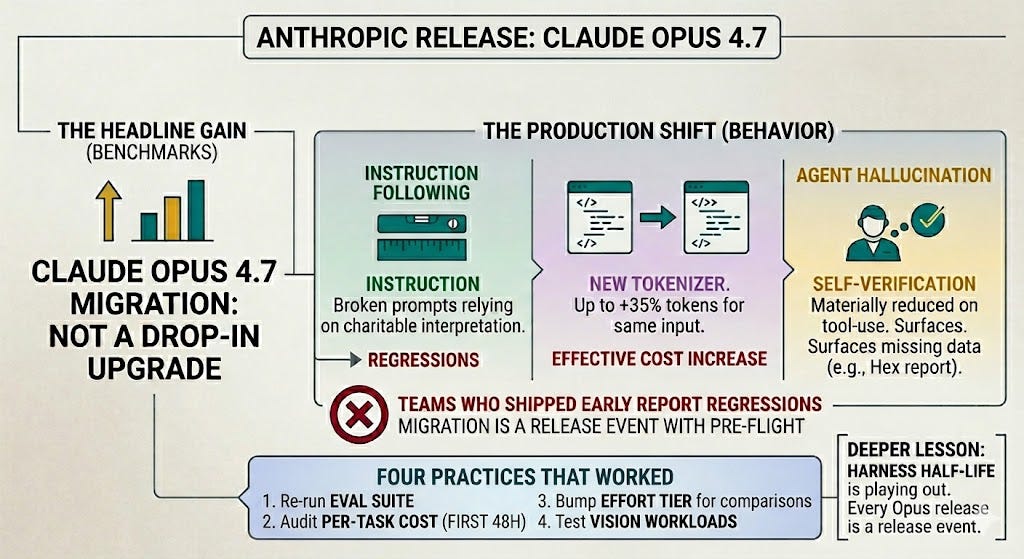
TL;DR - Anthropic released Claude Opus 4.7 on April 16, 2026 at unchanged pricing ($5/$25 per million tokens). After three weeks of production traffic from teams that shipped early, the most important changes are not the headline benchmark gains — they’re the behavior shifts. Stricter instruction following has broken prompts that relied on charitable interpretation. The new tokenizer can produce up to 35% more tokens for the same input text, shifting cost calculations even at unchanged pricing. Self-verification has materially reduced agent hallucination on tool-use tasks; Hex reports the model surfaces missing data states honestly rather than confabulating. The migration is not drop-in — teams that flipped the model string in config and shipped are the teams reporting regressions. The four practices that worked: re-run the eval suite, audit per-task cost in the first 48 hours, bump the effort tier when comparing benchmarks, and test vision workloads explicitly. The deeper lesson: every Opus release on the current ~2-month cadence is now a release event with its own pre-flight, and the Harness Half-Life is playing out in real time on every team’s prompt suite.
What was promised at launch
The April 16 launch positioned Opus 4.7 as a targeted upgrade over Opus 4.6 — improvements in software engineering, vision, instruction following, and self-verification, with particular gains on the most difficult tasks. Anthropic’s framing was that users should be able to hand off their hardest coding work to the model with less supervision than 4.6 required.
The benchmark numbers Anthropic published: 64.3% on SWE-bench Pro, 87.6% on SWE-bench Verified, and 69.4% on Terminal-Bench 2.0, with 3x higher image resolution (up to 2,576 pixels on the long edge) and a new xhigh effort tier between high and max. Pricing held flat at $5 per million input tokens and $25 per million output tokens.
Opus Updates
That was the launch. What’s emerged in the three weeks since is more textured — and the texture is where the engineering decisions actually live.
The instruction-following shift is the biggest change
The headline that matters for any team running production prompts: Opus 4.7 follows instructions more literally than 4.6 did.
The behavioral pattern, reported across multiple post-launch evaluations: prompts that relied on the model “reading between the lines” now do exactly what they were told. If the prompt says “respond in JSON format,” the model does — even when a clarifying question would have been more useful. If the prompt says “use Postgres, not SQLite” early in the run, the model now honors that constraint twenty steps later where 4.6 would sometimes drift toward whatever the broader context implied.
Three concrete patterns have shown up most often in the regression triage:
Implicit fallback prompts. Teams shipped prompts that effectively said “if you can’t do X, do Y.” The 4.6 behavior was to interpret this as a soft preference and frequently produce X anyway when X was clearly the right answer. The 4.7 behavior is to follow the literal instruction — Y appears when X would have been better, because the prompt said Y was acceptable. Fix: rewrite to express constraints as preferences rather than fallbacks where appropriate.
Format-overriding-content. A prompt that ends with “respond in JSON” gets JSON, even when the right response is a clarifying question. The 4.6 model would often violate the format instruction to ask the question. The 4.7 model produces malformed JSON or a JSON object containing the question, both of which break downstream parsers. Fix: split format instructions from content instructions, or explicitly say “if you need clarification, ask in plain text and skip the JSON wrapper.”
Negation drift. “Don’t do X” instructions that 4.6 sometimes interpreted as “X is unusual but not forbidden” now produce strict refusal of X even when context shifts. Fix: state the positive form (”do Y”) rather than the negation, where possible.
This is good for production systems. Predictability beats cleverness, and stricter instruction following is exactly the property agentic systems need to scale beyond babysitting. It is bad for teams who shipped prompts that depended on the model’s charitable interpretation. Those prompts now produce different outputs, sometimes subtly worse, and the regression is not always visible in eval — it shows up as a 3% increase in user complaints two weeks after launch.
The practical implication: every team migrating from 4.6 to 4.7 needs to re-run their prompt suite against the new model and re-tune. Not because anything is broken — because the model is now answering the literal question, and the literal question may not have been quite what the prompt intended.
The tokenizer change is a silent cost shift
Pricing did not change. Effective spend did.
Anthropic’s pricing documentation states the change explicitly: Opus 4.7 uses a new tokenizer that may use up to 35% more tokens for the same fixed text. Independent post-launch testing has reported token counts up roughly 12-18% on typical workloads, with code-heavy and multilingual content sitting closer to the upper bound.
The 35% number is the worst case. The realistic number for most production workloads is in the 10-20% range. Either way, the implication for a team running production traffic is concrete:
Cost rises at the same pricing per token, because the same prompts now consume more tokens. A workload that ran at $50K/month on 4.6 likely runs at $55-60K/month on 4.7 with no other changes.
Rate limits hit sooner for any team running close to the ceiling, because the limits are denominated in tokens per minute. Teams who previously had headroom may need to request a quota increase or restructure their request distribution.
Context window math changes — prompts that comfortably fit in 200K under the old tokenizer now sit closer to the edge. Teams who routinely ran at 180K input may now be hitting 220K and getting truncated.
Cache hit accounting is unchanged at the multiplier level (5m write at 1.25x, 1h write at 2.0x, read at 0.1x), but the absolute number of cached tokens is higher, which changes the savings calculation in absolute terms.
This is a benign change on paper and an expensive one in practice. The teams that ran a careful migration audited their per-task cost metric in the first 48 hours and adjusted budgets. The teams that did not are now finding out via the monthly bill.
The broader lesson: token consumption is now part of the migration audit. A model upgrade is not a cost-neutral event even when per-token pricing is unchanged. The metric that matters is cost-per-task, not cost-per-token, and it must be measured before and after every migration.
Self-verification has been the standout improvement
The behavioral change practitioners report most consistently is self-verification on agentic tasks. The model proactively checks its own outputs before declaring a task complete — writing tests and running them, re-checking tool results before synthesizing, flagging missing data rather than confabulating around it.
Hex’s CTO captured the practical impact: the model surfaces missing-data states honestly rather than fabricating around them, and it resists the kind of conflicting-evidence patterns that previously confused 4.6. On Hex’s 93-task internal benchmark, the resolution rate moved up by 13 points against 4.6, and Opus 4.7 closed four problems that neither 4.6 nor Sonnet 4.6 had been able to finish.
Notion AI reported it as the first model to pass their implicit-need tests — tasks where the model must infer required actions rather than being told what tools to invoke.
For teams running coding agents and other multi-step automation in production, this is the change that justifies the migration on its own. The error rate that previously forced human checkpoints on every meaningful action drops, and the human checkpoint can move one layer up the stack. That is a different shape of human-in-the-loop, and it changes the economics of agent oversight.
The economics shift is concrete. If a team was running a coding agent that required human review on every PR, and 4.7 reduces the review-required rate from 100% to 60%, the per-PR human time falls by 40%. Aggregated across an engineering org’s PR volume, that’s a meaningful productivity multiplier — and it lands on the same headcount, not new hires.
For agent product teams, this also reshapes the handoff layer. The escalation triggers that fired when the model was uncertain now fire less often, because the model resolves more cases internally. The handoff payload still has to be tight when escalations do happen — but the volume of escalations falls, which means the human queue shortens, which means each escalation gets faster human attention, which means handoff quality improves end-to-end.
The xhigh effort tier and task budgets
Two new control surfaces shipped with 4.7. Both have meaningful implications for production economics.
xhigh sits between high and max — finer-grained control over the reasoning-vs-latency tradeoff. Anthropic recommends starting with high or xhigh for coding and agentic use cases, and Claude Code now defaults to xhigh across all plans.
Hex’s observation is the load-bearing one for cost calibration: low-effort 4.7 sits at roughly the quality of medium-effort 4.6. This means a team comparing the two should benchmark at one tier higher on 4.7 to match equivalent quality at lower cost. Concretely:
Workloads that ran at
mediumon 4.6 → trylowon 4.7 first; you may match or exceed quality at lower costWorkloads that ran at
highon 4.6 → trymediumorhighon 4.7; match quality at meaningful cost reductionWorkloads that need the absolute ceiling →
xhighis the new tier worth exercising;maxremains for the genuinely hardest tasks
The teams treating effort tiers as fixed config rather than tunable parameters are leaving real cost savings on the table. A migration sprint that includes effort-tier audits typically recovers a meaningful portion of the tokenizer cost increase.
Task budgets (public beta) are a token cap on a complete agentic loop — thinking, tool calls, tool results, and final output combined. The model sees a running countdown and prioritizes accordingly. This is the agent-system equivalent of a request timeout. It does not optimize cost per call; it bounds the worst case.
The implementation pattern is direct: set a per-task budget at invocation time, and the model receives the running count as part of its prompt context. As the budget approaches zero, the model wraps gracefully — finishing the current step, summarizing where it is, returning a partial answer rather than hitting a hard cutoff mid-tool-call.
For any team that has had a runaway agent loop in production — the kind that eats a day’s budget retrying the same failing tool call — this is the primitive that closes that failure mode. The combination with the server-side compaction beta (the compact-2026-01-12 header) means teams now have provider-native primitives for both the cost ceiling and the context overflow problem. Less custom infrastructure to build; less to maintain.
The vision jump is real
The vision change is the one most likely to be undervalued because it requires a workflow that exercises it. For teams that work with screenshots, diagrams, dense PDFs, or any high-DPI input, the practical impact is large.
The maximum image resolution moved from ~1.15 megapixels to ~3.75 megapixels — a 3.3x increase in pixel count. Independent reports flag this as an inflection for document extraction, log screenshot analysis, architecture diagram understanding, and similar workflows.
The use cases where this materially changes feasibility:
Dense document extraction — financial statements, medical records, technical drawings — where text or detail at the original resolution was previously too small to reliably extract.
UI testing and visual regression — full-page screenshots of complex web apps where individual components or text strings were previously below the resolution threshold.
Architecture diagrams and technical illustrations — where the relationships between components depend on small text labels and connection details.
Log and dashboard screenshots — where a workflow involves the agent reading rendered UI rather than structured data.
The cost: higher resolution images consume more tokens. Anthropic recommends downsampling when the extra fidelity is not needed. The pattern that has emerged: tier images by resolution requirement, and route to lower-resolution input for routine cases. Treat the high-resolution capability as a tool to invoke, not as a default.
This is not a “nice to have” change for vision-adjacent workloads. It is the difference between vision capabilities that worked in demos and vision capabilities that work in production.
The regressions
Not every change is an improvement. Two regressions are worth flagging.
Web research quality, by some independent reports, has dropped relative to 4.6 — source attribution accuracy, contradiction detection, and citation specificity all reportedly weaker. The hypothesis circulating among teams who migrated then partially reverted: the training tradeoff that improved agentic persistence shifted the model away from the careful cross-referential reasoning that made 4.6 strong on research tasks.
The practical guidance from teams who ran both side-by-side: if your primary workload is research synthesis where source fidelity matters, evaluate carefully before migrating. Some teams are running 4.7 for coding workflows and 4.6 for research workflows on the same product surface, routed by task type. The cost of running two models is real but smaller than the cost of regression on the workload that regressed.
Self-reported numbers vs independent testing. As is now standard with frontier model launches, independent testing tends to show tighter margins than vendor numbers. The 13% lift on coding benchmarks reported by Hex may be closer to 5-6 points in real-world workloads, particularly when controlling for the effort tier difference. This is not specific to Anthropic; it is a category property of self-reported AI evaluations and a reason to run independent benchmarks before relying on launch numbers for production decisions.
The patterns that worked
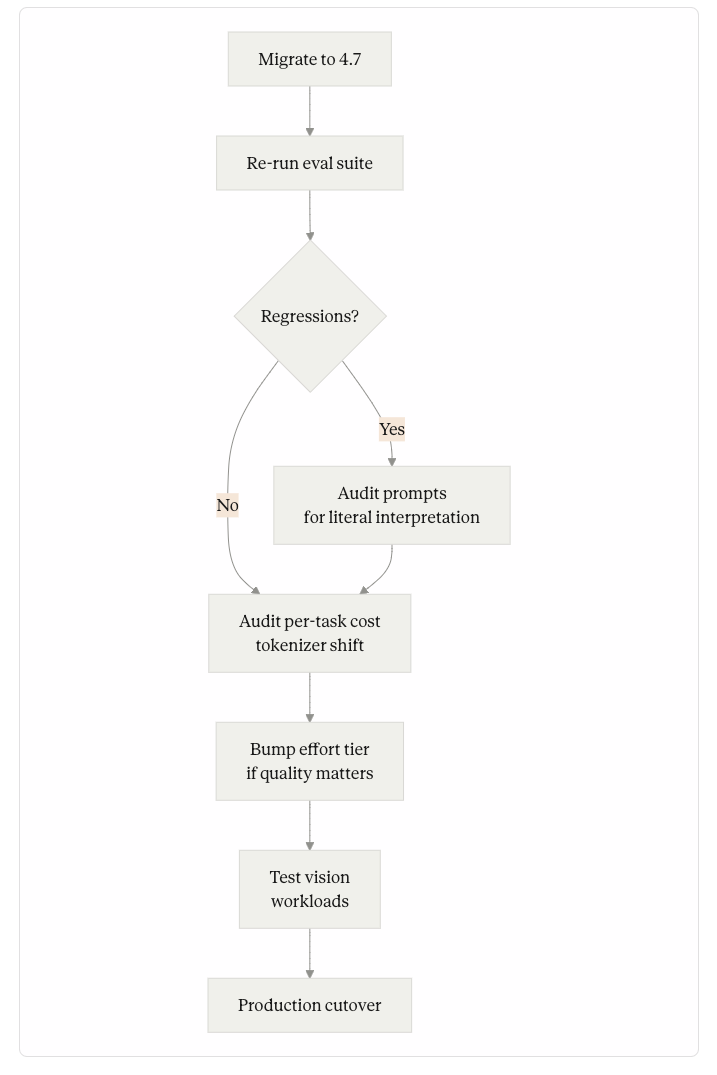
The migration patterns that worked in the first three weeks share four practices:
Re-run the eval suite before flipping production traffic. The instruction-following shift exposes prompt regressions that are not obvious from spot-checking. Teams that have a regression suite ran it against 4.7 first, triaged the failures, and then either fixed the prompts or held the model upgrade until they could.
Audit per-task cost in the first 48 hours after migration. The tokenizer change is a silent cost shift, and the only honest measurement is the per-task metric. A 30% increase in median cost-per-task with no quality change is the signal that effort tier or task budget tuning is needed.
Bump effort tier when comparing benchmarks. If the previous workload ran at
highon 4.6, equivalent quality on 4.7 may sit atxhigh— and equivalent cost athighmay now match whatmediumdid on 4.6. The tier-shift opportunity is the largest under-claimed win in the migration.Test vision workloads explicitly. The 3.3x resolution jump changes what is feasible. Teams that don’t exercise vision are leaving capability on the table — and teams whose workloads include any document, screenshot, or diagram processing should explicitly test whether the new resolution unlocks workflows that weren’t viable before.
The teams that struggled in the first three weeks did the opposite: flipped the model string, watched some prompts regress, and spent days triaging without a structured re-evaluation. Several reported partial reversion to 4.6 for specific high-value workloads while they did the migration audit they should have done before the cutover.
Migration Plan
The verdict three weeks in
For agentic coding workflows: migrate. The self-verification and tool-call reliability gains compound into materially fewer failed loops and less wasted compute. The teams running coding agents in production are the clearest beneficiaries.
For vision-heavy workflows: migrate immediately. The resolution jump is the kind of capability change that opens new product surfaces — workflows that were demo-viable but production-fragile become production-viable.
For research-heavy workflows: evaluate carefully. The reported regression on cross-referential reasoning is real for some tasks. Some teams are running 4.6 for research and 4.7 for coding on the same product, routed by task type, until the gap closes.
For everyone: budget time for prompt audit, audit per-task cost, and treat the migration as a release event with its own pre-flight. The model is better. The migration is not free.
What this release teaches about model upgrades generally
The deeper pattern this release illustrates is the Harness Half-Life playing out in real time. The custom prompt scaffolding, the fallback heuristics, the workarounds for 4.6’s quirks — many of them are now obsolete. Some of them are now actively suppressing capabilities the new model could provide. A team that built a custom verification step on top of 4.6 because the model didn’t reliably check its own work is now running that custom step and the model’s stronger built-in self-verification — paying for both, getting marginal benefit from the custom layer.
Auditing the harness on every model release is no longer optional. With a release cadence of roughly two months on the Opus line, it is now part of the operating rhythm.
The teams who treat each model release as a discrete project — its own pre-flight, its own audit, its own dashboard for tracking the migration — are the teams whose harnesses stay lean. The teams who treat each release as a config flip accumulate harness debt at compounding rates, and pay it off in larger and more painful migrations later.
The model is improving faster than the harnesses around it. That asymmetry is now a structural feature of building on frontier models, and the engineering response — instrumented migrations, structured audits, and a culture of harness pruning — is what separates teams whose costs shrink with each release from teams whose costs only grow.
Three weeks of production data from Opus 4.7 is enough to see the shape. The teams who learned this lesson cleanly are already preparing for the next release. The teams who didn’t are still triaging the last one.
Dont miss out on the next editions from The AI Runtime
The Cost Layer — The xhigh effort tier and the tokenizer change are both cost levers. Caching, routing, and task budgets are how teams absorb the per-task cost shift on migration.
The Shipped Agent’s First 90 Days — Treat every model release as a release event with its own pre-flight. The first 90 days framework formalizes the operating rhythm that catches regressions before users do.
Long-Running Agent State Management — The compact-2026-01-12 beta header pairs with Opus 4.7’s task budgets. Both are provider-native primitives that close failure modes teams used to build themselves.