

Two Ways to Shrink an AI Model. Only One Keeps the Output.
Quantization changes the numbers. Lossless compression removes the wasted bits and keeps every output identical, for about 30% less memory.

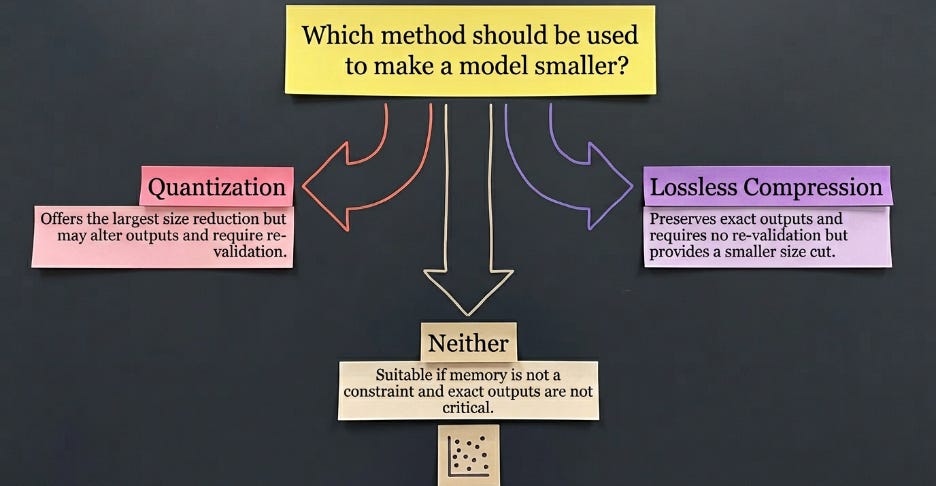
TL;DR - If your inference bill is climbing or you are running out of GPU memory, you have two ways to make a model smaller. Quantization cuts the most bytes but changes the model’s outputs, which is a problem for anything regulated or already validated. Lossless compression cuts about 30% of the bytes by re-packing the wasted space in BF16 weights, and the outputs come back bit-for-bit identical. The DFloat11 research confirms the 30% with zero accuracy change, and ZipNN reports similar. The 30% is a fixed ceiling, not a knob, so treat it as a free one-time discount for BF16 workloads that are memory-bound and cannot tolerate changed output. ISIRO Runtime is one commercial product built on this technique, with vendor-reported numbers worth testing rather than trusting. Before you quantize anything, run a bit-exact diff on a compiled model and measure whether your decode path is actually memory-bound.
The cheapest way to lower an AI inference bill is usually not a faster chip. It is moving fewer bytes. Quantization does that by shrinking the numbers in a model, which changes its outputs. Lossless compression does it by removing wasted space in those numbers, so roughly 30% of the bytes disappear and the outputs stay exactly the same.

Lossless float compression cuts about 30% of an LLM’s size by re-encoding the low-information bits in BF16 weights, then unpacking them on the GPU during inference, with outputs that are bit-for-bit identical to the original model. Because it changes no numbers, it fits regulated deployments in finance, healthcare, and defense where quantization is disqualifying. Published work including DFloat11 and ZipNN establishes the technique; the catch is that the win only shows up when your workload is memory-bound, and it tops out at 30%.
This matters to three groups at once. AI engineers and architects choosing how to serve a model. Teams hitting a GPU memory or budget ceiling. And the decision-makers signing the cloud and hardware bills. All three are asking the same question in different words: how to run a model for less without making it worse.
Why your inference cost is really a memory problem
Modern accelerators can do far more math than they can be fed. Over the past twenty years, raw compute on server chips grew about 3.0 times every two years, while the memory bandwidth that feeds the chip grew only 1.6 times on the same cadence. The math got cheap. Moving the data to the math stayed expensive.
For text generation, that gap is the whole story. Generating one token means reading a large pile of weights from memory and doing very little arithmetic on each byte before reading the next pile. The expensive compute units mostly wait. That is why memory bandwidth, not raw compute, is now the main bottleneck for serving, and it is why the lever that lowers cost and latency is fewer bytes crossing the bus, not faster math.
There is a useful consequence hiding in that sentence. If the chip is waiting on memory, the compute is sitting idle and free. Any trick that spends a little of that idle compute to move fewer bytes is close to free at the margin. Lossless compression is exactly that trick.
Weights are not the only thing crossing the bus. As conversations get longer, the key-value cache becomes a second heavy consumer of memory traffic, and research on lossless KV-cache compression targets those bytes the same way. Weights are simply the clearest place to start.
Two ways to make a model smaller
Quantization is the popular option, and for good reason. It drops the precision of every weight from 16 bits to 8 or 4, which shrinks the model and the bytes moved per token. The price is that every weight becomes a slightly different number, so the model produces slightly different outputs. For a lot of products that is fine. For some it is a dealbreaker, and the research community has shown that the effect of lossy compression on model behavior, including safety and bias, is not yet fully understood.
Lossless compression takes a different path. Think of a ZIP file. You compress a folder to 70% of its size, and when you unzip it you get every original byte back, exactly. Lossless model compression does the same thing to the weights. It finds the wasted space, packs it tighter, and unpacks it before the math runs, so the model that executes is the original model down to the last bit.
The wasted space is real and measurable. A BF16 weight uses eight bits for its exponent, but a trained model’s weights cluster in a narrow range, so most of those exponent bits carry no information. DFloat11 re-encodes that redundancy and gets the weights down to about eleven effective bits, a roughly 30% reduction with bit-for-bit identical output. Independent groups land on the same figure: ZipNN reports lossless savings often around a third and sometimes above half. When separate teams converge on the same number, the number is real.
That convergence also sets the ceiling. The other bits in a weight behave like random noise and will not compress, so lossless cannot reach the 50% or 75% that 4-bit quantization hits. What it gives you is a bounded, one-time, free 30%. Not a knob you keep turning, a discount you take once.
Who should care, and the situations where it pays off
ISIRO.AI, a startup building on this technique, frames the value as lower cost, better memory-bound latency, data-center power savings, and longer edge battery life, across every scale. Stripped of the pitch, that resolves into four concrete situations.
You serve a model that has to stay exactly itself. A bank’s credit model, a hospital’s clinical-support model, or a defense classifier was approved as a specific artifact producing specific outputs. Quantizing it makes a different artifact, which in a strict regime restarts validation, audit, or filing. That clock can run months. Lossless compression sidesteps it entirely: the validated model and the deployed model are the same bits, so the memory savings arrive without reopening governance. A single changed digit in such a model can mean a different lending decision or a different dosage flag, which is why exact reproduction, not close-enough accuracy, is the bar. For these teams, bit-exact is not a nice-to-have. It is the only acceptable answer.
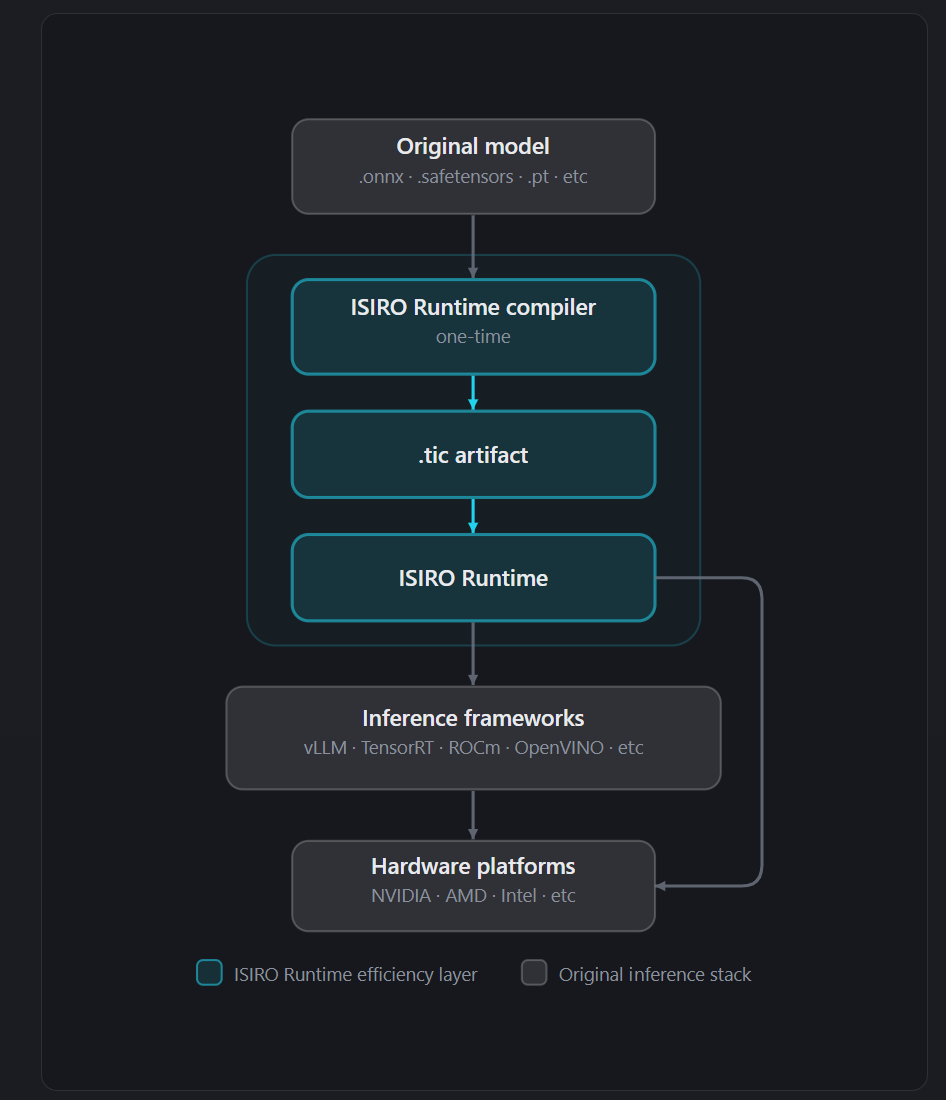
source: isiro.ai
You are about to outgrow your GPUs. A 30% smaller model is the difference between fitting and spilling. DFloat11 ran a 405B-parameter model, normally an 810GB load, on a single 8x80GB node. At a fixed memory budget the same compression bought 5.3 to 13.17 times longer context. A BF16 8B model is about 16GB; trim 30% and it lands near 11GB, which can be the line between one tier of GPU and the next. If you keep hitting out-of-memory errors or paying for the bigger instance, this is the lever.
You deploy at the edge or on-device. The same 30% lets a model fit on hardware that could not otherwise hold it, including embedded boards and devices like NVIDIA Jetson. ISIRO lists edge battery life as a target, because fewer bytes moved is less energy spent, which on a battery is the metric that matters. On a phone or a robot, the model that fits is the model you ship, so a 30% reduction can be the difference between an on-device feature and a slower round trip to the cloud.
You are paying a large, growing inference bill. A 30% cut in memory traffic translates fairly directly into fewer accelerators for the same memory-bound work. In round numbers, a fleet of 100 GPUs doing memory-bound serving could do the same work on roughly 70, or each GPU could carry about 1.4 times its previous load. That is also a cooling and energy line on the facility budget, which is why this lands on a decision-maker’s desk and not only an engineer’s. ISIRO lists data-center power among its targets for the same reason: fewer bytes moved is less energy burned, and at fleet scale that is a sustainability number and a budget number at once.
Quantization trades accuracy for memory. Lossless compression trades a little spare compute for memory. The right question is which one you actually have to spare.
When to do what
The choice between levers comes down to two questions. Does the deployment need bit-exact output? Is the decode path actually memory-bound? The answers point cleanly to a tool.
Your situation Need exact output? Decode memory-bound? Best lever Regulated or already-validated model Yes Yes or no Lossless compression Cost-driven, some accuracy slack No Yes Quantization (bigger cut) Already 4-bit but still memory-tight Maybe Yes Try lossless on top, expect a smaller extra win Compute-bound, or the model already fits n/a No Neither; no memory lever needed
Two rules of thumb fall out of the table. If you cannot change the output at all, lossless is the only memory lever that qualifies, full stop. If you can change the output and you are purely chasing cost, quantization’s larger reduction usually wins, and lossless is a smaller bonus you can stack on if you are still tight. The one case to avoid is reaching for either lever when you are not memory-bound, because then you are paying overhead to save bandwidth you were not short on.
How to take advantage of it
The adoption path is short and measurable, and you can run most of it in an afternoon.
Start by finding the workloads that are actually memory-bound. Profile a representative serving job and check whether the GPU is starved on memory bandwidth during decode at your real batch size. If it is, you have a candidate. If it is compute-bound, stop here.
Next, decide whether the workload needs bit-exact output. If it is regulated, validated, or audited, the answer is yes and lossless is your lever. If not, price quantization first and treat lossless as the fallback when you need exact output or a free top-up.
Then run the test that settles it. Compile the model into a compressed format, serve it, and diff the outputs against your uncompressed baseline. A true lossless path produces a diff of exactly zero. Measure memory traffic, latency, and cost against the same baseline. Now you have numbers for your workload instead of a vendor’s.
One practical worry for enterprises is whether evaluating a vendor means handing over the model weights. It should not. ISIRO’s stated approach is that you run without sharing your model, compiling and comparing against your own baseline in your own cloud or on-prem environment. Confirm that boundary in writing before any trial, because for a model that cost six figures to train, the weights are the asset you are protecting.
This is where a product like ISIRO Runtime fits the pattern. It compiles a model once into a compact execution-native .tic artifact, then runs it through an efficiency layer that sits between your model and the inference stack you already use, targeting vLLM, TensorRT, and OpenVINO with an OpenAI-compatible API so existing clients keep working. Support today is scoped to BF16 vLLM on NVIDIA GPUs. ISIRO reports 30% lower memory traffic and up to 2 times lower latency against a cuBLAS baseline on its evaluated workloads. Those are vendor-published figures from scoped tests, not independent benchmarks, and the latency comparison is against NVIDIA’s own library on NVIDIA hardware where ISIRO is an Inception and AWS partner. They line up with the published research on the technique, which is the most that can be said for a number nobody outside the vendor has reproduced. The point of the afternoon test is to replace that vendor number with yours.
If the model is your intellectual property, the compiled-artifact approach also opens a security option. ISIRO packages encryption, signing, and an in-use lock for the compressed file, plus hardware-backed confidential computing for buyers with strict isolation requirements. Treat those claims as a separate evaluation from the efficiency claims, because encryption of a model file is well understood and the differentiated part needs testing against your own threat model.
The catch: decode speed, and a hard 30% ceiling
Lossless compression is not free of engineering risk, and the risk is the same property that makes it work. Packing weights tighter produces variable-length codes, and those break the lockstep parallelism GPUs rely on, because no thread knows where its data starts without decoding everything before it. A naive implementation also unpacks weights into memory before computing, which puts back the exact traffic the compression removed.
The good implementations fix this by unpacking inside the computation. ZipServ describes a load-compressed, compute-decompressed design that keeps weights compressed across the bus and unpacks them on the fly directly into the compute units. Anyone can compress BF16 weights by 30%, because that ratio is a property of the data. The hard, defensible work is the decode kernel that keeps the saved bandwidth from being eaten by unpacking overhead. The product is the kernel, not the compression.
Two limits are worth saying plainly. The 30% does not grow; the redundancy in BF16 is fixed, while quantization research keeps finding lower bit-widths, so on a pure cost basis quantization often wins. And the technique only helps when decode is memory-bound, so on a small model that already fits or a compute-bound job, it is the wrong tool. Inside its scope it is close to a free lunch. Outside it, reach for something else.
Frequently Asked Questions
Is this just quantization by another name?
No, and the difference is the whole point. Quantization lowers the precision of the weights, which shrinks the model but changes its outputs. Lossless compression re-packs the existing weights and unpacks them exactly, so the outputs are identical to the original model. One trades accuracy for memory; the other trades a little compute for memory. You can even use both, though the lossless gain shrinks once weights are already quantized.
How much will it actually save me?
About 30% on BF16 models, with DFloat11 and ZipNN both landing near that figure. The ceiling is set by how much wasted space a BF16 weight contains, so a lossless codec cannot match the 50% or 75% that 4-bit quantization reaches. Treat 30% as a fixed, one-time discount, and run a test on your own workload to confirm the figure and the latency effect before committing.
Which models and hardware does this work on?
The technique applies to any model with repetitive numerical structure, large LLMs or small ones, though the headline 30% is specific to BF16 weights. In practice, tooling maturity is the constraint. ISIRO, for example, supports BF16 vLLM on NVIDIA GPUs today, with other frameworks and hardware on its roadmap. If you run a different stack, the research applies but the production tooling may not be ready yet.
Who on the team owns this decision?
Engineers and architects run the test and own the integration, because the value depends on whether decode is memory-bound and whether the bit-exact diff is truly zero. Decision-makers own the trigger, because the payoff shows up as fewer GPUs, a smaller cloud bill, and lower facility power. The fastest path is an engineer running the afternoon test and handing a decision-maker the cost delta for their actual workload.
Closing
Pick one model you serve in BF16 and ask two questions before your next GPU purchase. Is decode memory-bound at your production batch size? Does the deployment require exact output? If both answers are yes, compile the model, diff it against your baseline, and confirm the difference is exactly zero. The 30% is then yours to take with no accuracy conversation to have with anyone. If you are compute-bound or can tolerate changed output, you have just saved yourself a vendor call by knowing it.
https://shapeofcinema.substack.com/p/im-with-stoopid?r=8dbojf&utm_medium=ios