

Your AI Strategy Doesn’t Need More Use Cases. It Needs a Production System.
Why most enterprise AI strategies fail at the same point — and the five decisions that separate companies shipping AI products from companies running perpetual pilots.

TL;DR: Most enterprise AI strategies are lists of use cases hunting for approval. The companies that actually reach production — BBVA (120,000 employees), Lowe’s (1,700 stores), Intercom (millions of monthly resolutions), Booking.com (global trip planning) — didn’t succeed because they found better use cases. They succeeded because they built production systems: repeatable engineering, governance, and organizational infrastructure that turns any validated idea into a deployed product. After analyzing seven enterprise deployments from OpenAI’s whitepaper, the path to production comes down to five architectural decisions most companies either skip or get wrong. This article is the strategy document your CTO needs — not another use-case brainstorm, but the engineering and organizational blueprint for making AI deployable by default.
The Pilot Trap
Here’s what happens at most companies: A team identifies a promising AI use case. They build a prototype. It works in the demo. Stakeholders are excited. Then nothing happens for six months.
The prototype needs production data — but the data team hasn’t classified which datasets are approved for AI use. The prototype needs a deployment environment — but the infrastructure team hasn’t provisioned one for AI workloads. The prototype needs a compliance review — but legal doesn’t have a framework for evaluating AI-specific risks. The prototype needs an evaluation suite — but nobody has defined what “good enough” means.
Each of these is a solvable problem. The issue is that they’re solved sequentially, per-project, by the same team that built the prototype. The team that’s good at building AI prototypes is now spending 80% of its time on governance, infrastructure, and cross-functional coordination.
This is the pilot trap: the gap between prototype and production isn’t a technology problem. It’s a systems problem. And it requires a systems solution.
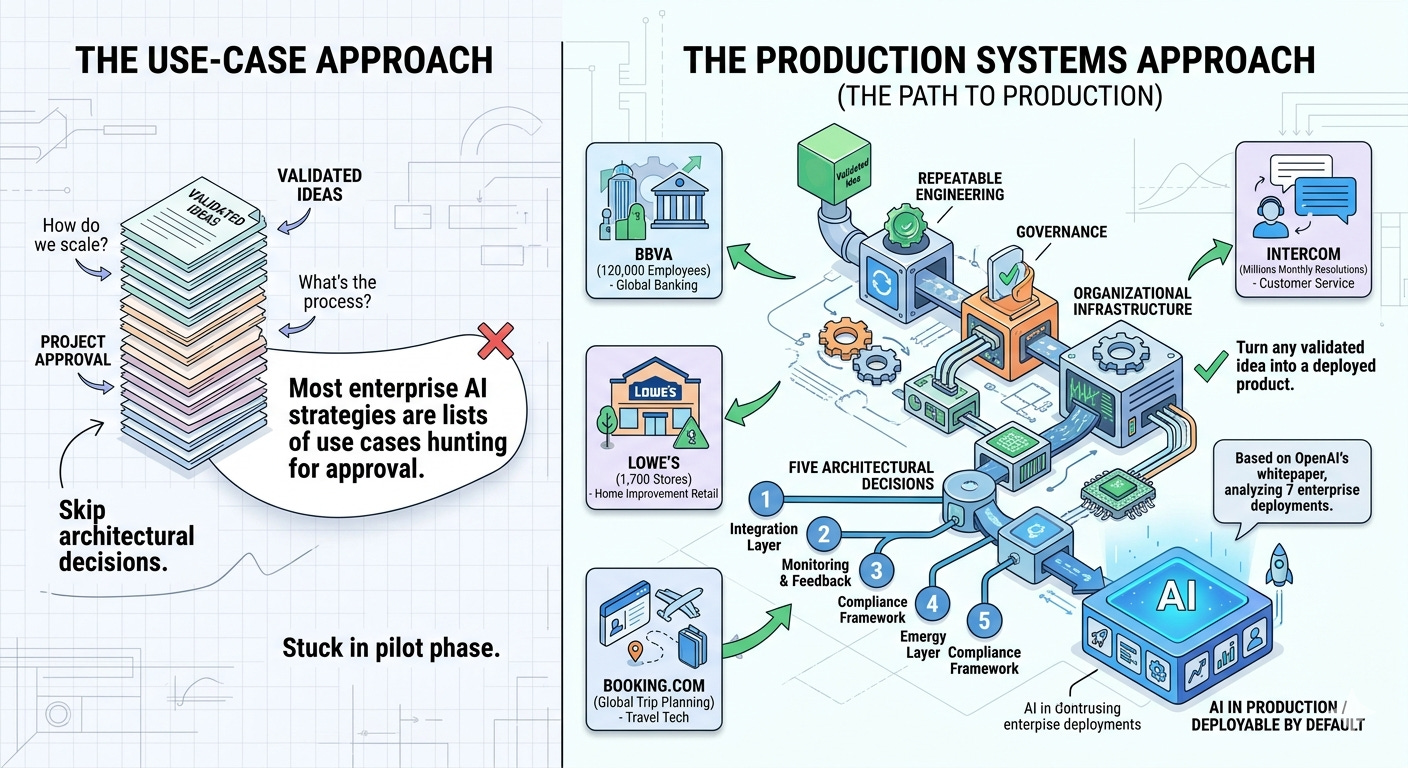
Pilot to Prod
Decision 1: Build the Production Infrastructure Before You Need It
The companies that reached to production with AI fastest didn’t wait for a use case to justify infrastructure investment. They built the production path first.
Figma created a “compliance fast path” — pre-classified data, pre-defined guardrails, pre-approved experiment categories — so that any team could test AI tools without triggering a per-project compliance review. The governance infrastructure existed before the use cases that needed it.
BBVA established data boundaries, security protocols, and a Center of Excellence before expanding from 3,000 to 11,000 licenses. By the time they were ready to scale to 120,000, the infrastructure was battle-tested.
What this means for your strategy: Before you prioritize your top 10 use cases, answer these five infrastructure questions:
Data readiness — Which datasets are classified and approved for AI use? What’s the process for approving new ones? How fast can a team get access to production data for a validated use case?
Governance framework — What types of AI experiments are pre-approved? What triggers a full review? Who has decision rights, and what are the escalation paths?
Evaluation infrastructure — Do you have an eval framework that any team can plug into? Can you define and measure behavioral SLOs before launch?
Deployment pipeline — Can a team go from approved prototype to production deployment without building custom infrastructure? Is there a standard path with gated checkpoints?
Monitoring — Once deployed, who owns ongoing behavioral reliability? What gets measured, how often, and what triggers intervention?
If you can’t answer these questions, your first AI project isn’t a use case — it’s building this infrastructure. Every subsequent use case becomes faster and cheaper because the path already exists.
Decision 2: Treat AI Fluency as Engineering Capacity, Not HR Training
The whitepaper from OpenAI frames AI fluency as a training and culture initiative — workshops, champion networks, hackathons. That framing misses the most important dimension: engineering fluency determines your production velocity.
Intercom’s ability to migrate models in days comes from engineers who deeply understand their evaluation pipeline. Booking.com shipped a prototype in 8-10 weeks because their engineers could integrate OpenAI’s API with existing ML infrastructure without rearchitecting. BBVA’s 3,000+ custom GPTs were built by employees who understood enough about prompt engineering to create useful tools without engineering support.
What this means for your strategy: Fluency investment should be tiered:
Tier 1: Universal literacy. Everyone in the organization understands what AI can and can’t do, when to use it, and how to interact with it effectively. This is the workshop-and-hackathon layer.
Tier 2: Builder capability. Product managers, analysts, and domain experts can build custom GPTs, design prompts, and evaluate AI outputs against domain-specific quality standards. BBVA’s “wizards” operate at this tier.
Tier 3: Production engineering. Engineers can build, evaluate, deploy, and monitor AI systems in production. They can design evaluation suites, implement guardrails, instrument observability, and run behavioral regression tests against model updates. This tier determines how fast you can ship.
Most enterprise AI strategies invest heavily in Tier 1, modestly in Tier 2, and almost nothing in Tier 3. Then they wonder why pilots don’t reach production. The bottleneck is almost always Tier 3 engineering capacity — not use-case ideas, not executive sponsorship, not data access.
Decision 3: Prioritize Reuse Over Innovation
The whitepaper advises designing “for reuse from the start.” This understates how transformative reuse-first thinking actually is.
Lowe’s built one AI foundation and deployed it as two products — customer-facing Mylow and associate-facing Mylow Companion. Same knowledge base, same model, different interfaces. The second product was dramatically cheaper and faster than the first because the foundational engineering was already done.
BBVA’s internal GPT Store means solutions built by one team are immediately available to the entire organization. A legal team’s document analysis GPT becomes a compliance team’s document analysis GPT with minimal modification.
What this means for your strategy: When prioritizing use cases, the highest-value next project isn’t always the highest-impact standalone idea. It’s often the one that shares the most infrastructure with what you’ve already built.
Score each candidate use case on two dimensions: standalone value (impact if built in isolation) and infrastructure leverage (how much existing code, data pipelines, evaluations, and governance it can reuse). The use case that scores highest on the product of both dimensions is your next build — not the one with the highest standalone value.
Concretely: if you’ve already built a retrieval pipeline, evaluation framework, and guardrail system for an internal knowledge Q&A tool, your next use case should probably be another knowledge Q&A tool for a different domain — not a completely different architecture that requires building everything from scratch.
This feels counterintuitive because organizations reward novelty (”we’re building something new!”) over leverage (”we’re deploying what we already have to a new domain”). But leverage is what compounds. Novelty is what creates one-off pilots.
Decision 4: Measure Causally, Not Correlatively
Uber ran controlled experiments comparing AI-augmented workflows with traditional ones. OpenAI’s internal sales assistant was measured against corrections from top performers. Booking.com tracked engagement time, search-to-booking conversion, and support ticket volume against baselines.
Most companies measure AI adoption metrics: number of users, messages sent, satisfaction surveys. These metrics can show adoption without proving value. A tool that’s widely used but subtly wrong — plausible but inaccurate answers, faster-but-lower-quality outputs — will show positive adoption metrics while degrading actual business outcomes.
What this means for your strategy: Define your measurement architecture before you deploy:
Causal measurement — Can you run controlled comparisons? A/B tests between AI-augmented and traditional workflows? Before/after analysis with matched cohorts? If you can’t establish causation, you’re optimizing for adoption, not impact.
Business outcome metrics — What business metric does this use case actually move? Not “time saved” (self-reported) but “resolution speed” (measured). Not “user satisfaction with the tool” but “customer satisfaction with the outcome.”
Counterfactual tracking — What would have happened without the AI? This is the hardest measurement to build and the most important. Without it, you attribute every improvement to AI and every failure to something else.
Cost-per-outcome — What does each AI-generated outcome actually cost, including compute, human review, error correction, and organizational overhead? Lowe’s discovered that 68% of their queries didn’t need their flagship model — a discovery only possible with per-query cost instrumentation.
The goal isn’t to measure everything. It’s to measure the right things with enough rigor to make deployment and expansion decisions based on evidence rather than enthusiasm.
Decision 5: Assign Production Ownership Before Launch
The whitepaper describes building cross-functional teams with “engineers, SMEs, data leads, and executive sponsors.” What it doesn’t specify — and what matters most — is who owns the system after launch.
In traditional software, this is obvious: the engineering team that built it operates it, with SRE support. In AI products, it’s ambiguous. The model changes without you deploying anything. The data changes without you modifying anything. The behavior changes without you touching anything. Someone needs to own this.
What this means for your strategy: Before any AI product launches, assign three ownership roles:
Behavioral reliability owner — monitors behavioral SLOs (faithfulness, relevance, safety), detects drift, coordinates response to behavioral incidents. This is the MRE function, whether you call it that or not.
Model management owner — tracks model provider updates, runs regression tests on new versions, manages model selection and routing decisions. This role prevents the “silent model update breaks production” failure mode.
Business value owner — monitors the causal metrics from Decision 4, determines whether the product is still delivering the value that justified deployment, and decides when to expand, refine, or sunset.
These can be the same person on a small team, but they can’t be no one. The most common failure mode in enterprise AI isn’t a spectacular crash — it’s a slow, invisible degradation where the model gets slightly worse over weeks and nobody notices because nobody is watching.
Building Your Path-to-Production Document
If you’re a CTO, VP of Engineering, or AI lead, here’s the strategic document you should build — not a list of use cases, but a production system specification:
Page 1: Infrastructure readiness assessment. Where do you stand on data classification, governance framework, evaluation infrastructure, deployment pipeline, and monitoring? What’s the gap between current state and production-ready?
Page 2: Fluency investment plan. How are you building Tier 1 (literacy), Tier 2 (builder), and Tier 3 (production engineering) capabilities? What’s the timeline for each, and how do you measure progress?
Page 3: First three use cases, scored on standalone value × infrastructure leverage. Not your ten best ideas — your three best first ideas, chosen because they build infrastructure that makes everything after them faster.
Page 4: Measurement architecture. For each use case, what’s the causal measurement strategy? What business outcomes are you tracking, and how are you establishing counterfactuals?
Page 5: Ownership model. Who owns behavioral reliability, model management, and business value for each deployed product? What’s the incident response playbook?
This document isn’t a strategy deck that gets presented once and forgotten. It’s a living system specification that evolves with every deployment. Each new product strengthens the infrastructure, expands the evaluation framework, deepens organizational fluency, and makes the next deployment faster.
The companies in OpenAI’s whitepaper didn’t scale AI because they had better ideas. They scaled because they built production systems that turn good ideas into deployed products — repeatedly, reliably, and with compounding returns.
Your AI strategy should do the same.
Building your own path-to-production document? I’m collecting examples of enterprise AI production system designs for a future AIEW deep-dive. Reply with what you’re building — anonymized details welcome.