

Your ETL Pipeline Won’t Save You. Your AI Data Stack Will.
The data engineer’s guide to building an AIfolio that proves you’ve made the leap from pipeline plumber to AI infrastructure architect.

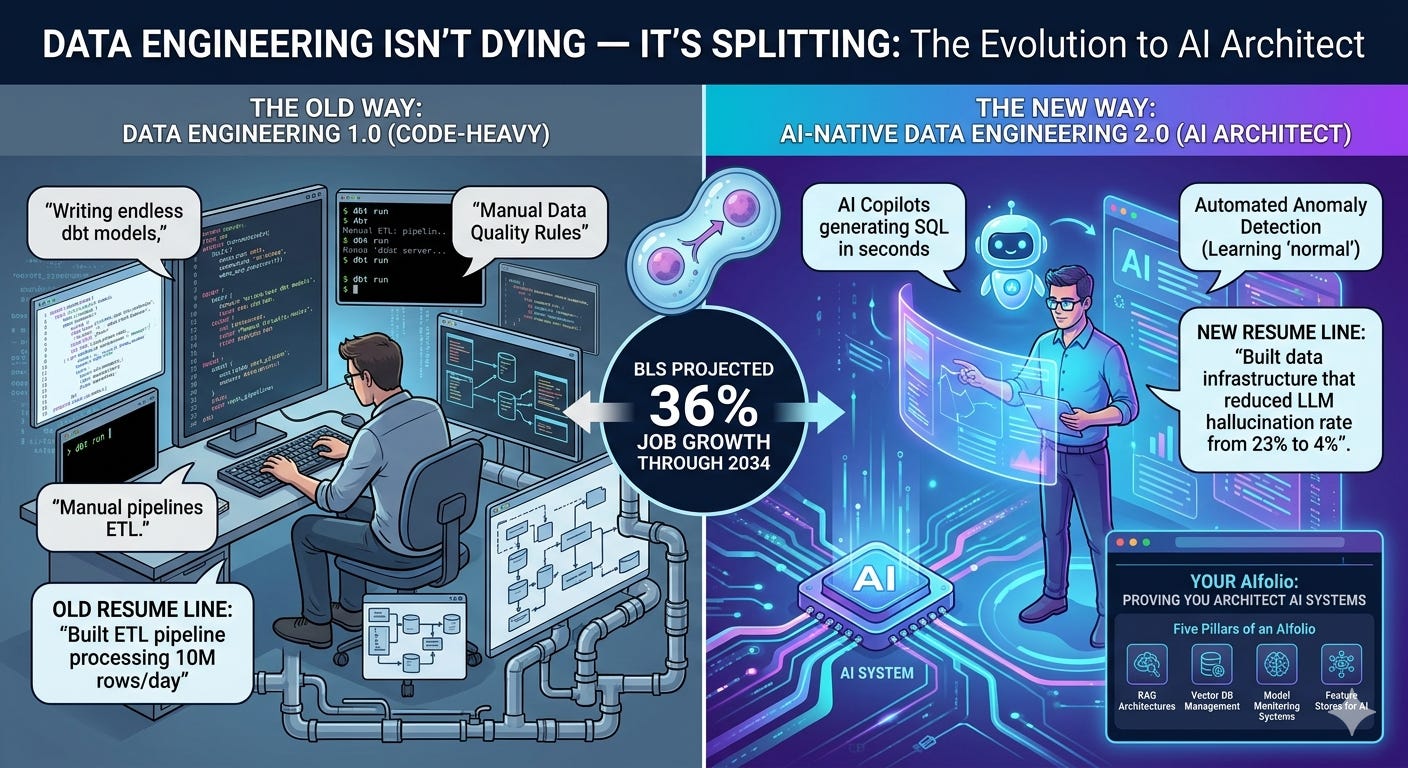
TL;DR: Data engineering isn’t dying — it’s splitting. The BLS projects 36% job growth through 2034, one of the fastest rates in tech. But the work is unrecognizable. AI copilots now generate boilerplate SQL in seconds, anomaly detection tools learn “normal” without hand-written rules, and natural-language interfaces let business users build their own simple pipelines. The data engineers who thrive in 2026 aren’t the ones writing more dbt models — they’re the ones designing the data infrastructure that makes AI systems actually work. In my last article, I introduced the concept of an AIfolio — a portfolio built around AI-native projects that prove you can architect AI systems, not just code. That article was aimed at developers broadly. This one is for data engineers specifically, because your version of an AIfolio looks fundamentally different — and your existing skills give you an unfair advantage in building it. The old resume line was “built ETL pipeline processing 10M rows/day.” The new one is “built the data infrastructure that reduced our LLM hallucination rate from 23% to 4%.” Here are the five pillars of a data engineer’s AIfolio, the exact tools to build them with, and the presentation layer that makes hiring managers say yes.
The Tectonic Shift Nobody Warned You About
Here’s the thing about data engineering in 2026: the profession is simultaneously booming and being hollowed out from the inside.
AI-Native Data Engineer
The demand numbers look fantastic on the surface. The O’Reilly 2025 Tech Trends Report showed data engineering skills grew 29% year-over-year. The BLS projects 36% growth through 2034. Median salaries sit comfortably between $120K and $200K. By every macro measure, data engineering is thriving.
But zoom into what data engineers are actually doing day-to-day, and the picture shifts dramatically. Snowflake launched Cortex Code in February 2026 — a CLI that generates dbt models from natural language, reads your actual schema (no hallucinated table names), and supports Claude Opus 4.6 and GPT-5.2 as underlying models. Describe what you want in plain English, and it writes the SQL, the schema YAML, and the tests. Databricks has Agent Bricks running at 250K+ queries per second for structured extraction and text transformation. GitHub Copilot, at $19-$39 per seat per month, is already standard on most data teams.
The result? A study examining 285,000 companies found that hiring for senior positions is still increasing while hiring for junior positions is decreasing. The pattern is identical to what happened in software engineering — AI doesn’t replace the experienced architect, it eliminates the apprenticeship that creates experienced architects.
If you’re a data engineer whose primary value is “I write SQL and Python to move data from point A to point B,” you’re in the blast radius. If your value is “I design the data systems that make AI applications reliable, governable, and cost-effective,” you’re in the most in-demand job market in a decade.
The question is: which one are you building toward?
The Data Engineer’s Role Has Inverted
Think about how a hospital pharmacy works. A decade ago, pharmacists spent most of their time physically counting pills and putting them in bottles — the mechanical act of fulfillment. Today, automated dispensing machines handle that. Pharmacists didn’t disappear. They moved up the stack — clinical consultations, drug interaction analysis, treatment optimization. The mechanical work was automated; the judgment work became more valuable.
Data engineering is undergoing the exact same inversion.
The old job: Write ingestion scripts. Build transformation logic. Schedule pipelines. Monitor for failures. Debug broken DAGs at 2 AM.
The new job: Design the data architecture that powers AI applications. Build embedding pipelines for RAG systems. Implement data quality frameworks that prevent AI models from making dangerous decisions on bad data. Create semantic layers that let LLMs understand organizational knowledge. Govern the data estate so AI adoption doesn’t create compliance nightmares.
Erik Duffield, co-founder of data platform company Ascend, captured it precisely: we’ve moved from a world where 80% of data is served to human analysts through traditional BI tools to one where machines are the primary data consumers. When your main customer was a human looking at a dashboard, “good enough” data quality was often fine. When your main customer is an LLM making autonomous decisions, “good enough” can be catastrophic.
This inversion creates a massive opportunity for data engineers who see it coming — because you already have the foundational skills (SQL, Python, cloud infrastructure, orchestration) that AI engineers typically lack. You understand data modeling, schema design, governance, and operational reliability. The gap isn’t in your foundations. It’s in your AI application layer.
Here’s how to close it.
Why Data Engineers Need a Different AIfolio
In the AIfolio article, I laid out four pillars for a developer’s AI portfolio: RAG pipelines, multi-agent systems, MCP integrations, and persistent memory. Those pillars are calibrated for software engineers crossing into AI.
Data engineers need a different set of pillars. Not because the AIfolio framework is wrong — but because your superpower is different.
An AI engineer’s AIfolio proves: “I can architect systems that think.”
A data engineer’s AIfolio proves: “I can build the data infrastructure that makes those thinking systems reliable, accurate, and governable.”
Most AI engineers build impressive demos on toy datasets, then watch them crumble when fed real-world data at scale. They don’t know how to handle schema evolution, data contracts, incremental processing, or data quality monitoring. They’ve never debugged a pipeline that silently dropped 12% of records at 3 AM.
You have. That’s your edge.
A data engineer’s AIfolio doesn’t replace the four original pillars — it complements them. Where the AI engineer builds the RAG application, you build the pipeline that keeps its knowledge base fresh, accurate, and governed. Where the AI engineer designs the agent workflow, you build the feature store and embedding infrastructure that powers it. Where the AI engineer wires up MCP, you build the semantic layer it queries.
The combination is absurdly valuable — and almost nobody has both sides. Here are the five pillars of a data engineer’s AIfolio.
The Five Pillars of a Data Engineer’s AIfolio
Pillar 1: A RAG-Ready Data Pipeline (Your Foundation Project)
Every AI application needs data, and most AI engineers are terrible at data engineering. This is your superpower — if you know how to wield it.
A RAG-ready data pipeline doesn’t just move data. It ingests unstructured documents (PDFs, Confluence pages, Slack threads, API responses), parses them intelligently, chunks them with semantic awareness, generates embeddings, and loads them into a vector store — all with the orchestration, monitoring, and data quality checks you’d apply to any production pipeline.
This is where your existing skills translate directly. You already know how to build reliable ingestion pipelines. You already understand idempotency, backfills, and incremental processing. You just need to add the AI-specific layers: document parsing, chunking strategy, embedding generation, and vector database management.
What this proves to a hiring manager: You understand that RAG systems live or die based on data quality — not model quality. A brilliant LLM with a poorly chunked knowledge base will hallucinate. A mediocre LLM with a well-engineered data pipeline will be reliable. You’re the person who builds the reliable version.
The tech stack:
For orchestration, use what you know — Airflow, Prefect, or Dagster. The pipeline structure is familiar: extract documents from source systems, transform them through parsing and chunking stages, load embeddings into a vector store. The DAG looks like any ELT pipeline; the transformations are just different.
For document parsing, LlamaParse handles PDFs with tables, nested headers, and images. For simpler documents, LangChain’s document loaders cover most formats.
For chunking, start with RecursiveCharacterTextSplitter (predictable, tunable) and graduate to semantic chunking when you’re ready. Chunk size matters enormously — too large and you dilute relevance, too small and you lose context. Production systems in 2026 typically use 200-1,000 token windows with 10-20% overlap.
For vector databases, Postgres with pgvector is the secret weapon for data engineers. You already know Postgres. pgvectorscale benchmarks show strong throughput even at 50M vectors. For dedicated vector stores, start with Chroma (zero-config, embedded) and graduate to Qdrant (production-grade, Rust-based) or Pinecone (fully managed).
For embedding models, use OpenAI’s text-embedding-3-small for prototypes. For production, consider open-source models from Hugging Face that you can self-host — eliminating per-token costs entirely.
The repos to study:
NirDiamant/RAG_Techniques (~26K stars) — 30+ advanced RAG implementations. Start here to understand the patterns before building your own pipeline around them.
infiniflow/ragflow (~73K stars) — Production-grade RAG engine with deep document understanding. Study this to understand what “production RAG” looks like from a data engineering perspective.
HKUDS/LightRAG (~30K stars) — Graph-based RAG that builds knowledge graphs from documents. Building a LightRAG pipeline over a real corpus is the kind of project that makes data engineering and AI engineering teams lean forward.
The AIfolio differentiator: This is where your version diverges from the standard AIfolio. Don’t just build a RAG pipeline. Add the data engineering discipline that most AI engineers skip — data quality checks on your chunks (are they coherent? do they preserve table structure?), monitoring on embedding drift, automated re-indexing when source documents change, and lineage tracking from source document to vector store to LLM response. An AI engineer’s RAG demo says “look, it answers questions!” Your RAG pipeline says “look, it answers questions correctly, reliably, with auditability from source to response.“ That’s the difference.
Pillar 2: AI-Powered Data Quality Monitoring (Your Competitive Advantage)
This is the pillar that screams “I’m a data engineer who understands AI” rather than “I’m a data engineer who’s trying to become an AI engineer.” It plays directly to your strengths.
Traditional data quality monitoring requires writing explicit rules for every check: this column should never be null, this value should be between X and Y, this count should match within 5% of yesterday’s. It’s exhausting, brittle, and never comprehensive enough.
AI-powered data quality flips the script. Instead of writing rules, you train anomaly detection models that learn what “normal” looks like for each dataset and alert only on meaningful deviations. The system notices when weekend sales patterns suddenly match weekdays, when a typically stable metric shows unusual variance, or when subtle correlations between datasets shift — things hand-written rules would never catch.
What this proves to a hiring manager: You understand the production reality that most AI projects ignore — that AI systems are only as good as the data feeding them. You can build the monitoring layer that prevents garbage-in-garbage-out at scale.
The tech stack:
For anomaly detection, start with statistical methods (z-scores, interquartile range) on your most critical tables, then graduate to ML-based detection using isolation forests or autoencoders. Great Expectations gives you the rule-based foundation; layer learned anomaly detection on top.
For metadata management, look at open-source data catalogs like DataHub or OpenMetadata. These tools track lineage, auto-generate documentation, and increasingly integrate AI for data discovery.
For observability, Monte Carlo is the industry leader (integrates with Snowflake, Databricks, dbt, and Airflow), but building your own lightweight version is the AIfolio project. The goal is a system that monitors freshness, volume, schema changes, and distribution shifts — and distinguishes between acceptable variations and genuine problems.
The AIfolio differentiator: Build a pipeline that ingests real data (public datasets work — NYC taxi data, weather data, stock prices), monitors it continuously for quality issues, and automatically alerts when anomalies occur. Add a dashboard showing historical data quality scores, detected anomalies, and resolution status. Then — here’s the move that elevates this from “project” to “AIfolio pillar” — intentionally inject data quality issues and show that your system catches them before they corrupt downstream AI models. Deploy it with a live link a recruiter can interact with. This is the kind of project you can only build if you understand both data engineering and AI failure modes.
Pillar 3: A Semantic Layer with MCP Integration (The Architecture Pillar)
This is the pillar nobody else is building yet — and it’s the one that will define data engineering’s next chapter. It also directly extends the MCP pillar from the original AIfolio framework, but from the data infrastructure side.
The problem: every company deploying LLMs needs those models to understand organizational data. But LLMs can’t query your data warehouse directly. They don’t know your business logic, your metric definitions, or which tables to join. Natural-language-to-SQL translation is better than it was, but it’s still unreliable for complex queries.
A semantic layer solves this by creating a structured, governed interface between LLMs and your data. It defines metrics, dimensions, and relationships in a way that both humans and machines can understand. Think of it as the “API” for your data — instead of letting AI tools write arbitrary SQL against raw tables, they query through a semantic layer that enforces business logic and access controls.
What this proves to a hiring manager: You think at the system design level. You understand that AI applications need governed, structured access to data — not just raw table scans.
The tech stack:
For the semantic layer itself, dbt’s semantic layer (via MetricFlow) is the production standard — it defines metrics as code that can be version-controlled, tested, and governed. Cube is another option that adds a caching and API layer.
For the LLM integration, build an MCP server (Model Context Protocol) that exposes your semantic layer to AI assistants. This means Claude, Copilot, or any MCP-compatible AI can query your organizational data through a governed interface — asking questions in natural language that get translated to semantically correct queries.
The repos to study:
modelcontextprotocol/python-sdk (~22K stars) — The official Python SDK for building MCP servers. FastMCP lets you build a working server in under 20 lines of code.
modelcontextprotocol/servers (~76K stars) — Reference implementations. Study the database server examples.
The AIfolio differentiator: Build an MCP server that wraps a dbt semantic layer. An AI assistant asks “What was our revenue last quarter by region?” and your server translates that through the semantic layer into a governed, correct query — with access controls, audit logging, and metric definitions enforced automatically. Document the governance model alongside the technical architecture. This single project sits at the intersection of data engineering, AI infrastructure, and data governance — exactly where the profession is heading. In the original AIfolio, MCP was about connecting AI to tools. In a data engineer’s AIfolio, MCP is about connecting AI to your organization’s data — safely.
Pillar 4: A Feature Store and Real-Time Embedding Pipeline (The ML Infrastructure Pillar)
Every company building recommendation engines, fraud detection, or personalization needs a feature store. Every company deploying LLMs needs an embedding pipeline. These are data engineering problems wearing AI costumes — and they’re the infrastructure that AI engineers assume “someone else” builds.
A feature store ensures consistent feature computation across training and serving — preventing the dreaded “training-serving skew” where your model was trained on features calculated one way but serves predictions using features calculated slightly differently. An embedding pipeline continuously generates and updates vector representations of your data as it changes.
What this proves to a hiring manager: You understand ML infrastructure — the plumbing that makes models work reliably in production, not just in a Jupyter notebook.
The tech stack:
For feature stores, Feast (open-source) is the standard for learning. It handles both batch features (computed in your warehouse) and real-time features (computed from streaming data). Tecton is the enterprise option if you want to demonstrate awareness of the commercial landscape.
For the embedding pipeline, build a Kafka-based streaming pipeline that generates embeddings in near-real-time as new data arrives — documents added, records updated, content changed. Embeddings flow into your vector store, keeping your RAG system current without full re-indexing.
For streaming infrastructure, Apache Kafka is still the backbone. Combine it with Flink or Spark Structured Streaming for the processing layer.
The AIfolio differentiator: Build a feature store that serves features for a simple recommendation model, and an embedding pipeline that keeps a vector store current. Show that when new data arrives via Kafka, embeddings are generated and searchable within seconds — not hours. Then connect this to your Pillar 1 RAG pipeline. Now you have two AIfolio projects that work together as a system, not isolated demos. This compound effect — projects that reference and extend each other — is what separates an AIfolio from a list of disconnected repos.
Pillar 5: A Data Governance Framework for AI (The Senior-Level Pillar)
This is the pillar that signals staff/principal-level thinking. It’s less about code and more about systems design — and it’s the most underbuilt layer in the entire AI ecosystem.
Every organization racing to adopt AI is creating a governance nightmare. Business teams launch AI initiatives with zero regard for data lineage, access controls, or compliance. AI models are trained on data that may contain PII. LLMs access data stores without audit trails. The EU AI Act requires audit trails for model-training data. Nobody’s building the governance infrastructure to handle any of this.
What this proves to a hiring manager: You understand the organizational and regulatory dimensions of AI — not just the technical ones. You’re the engineer who prevents the compliance disaster, not the one who creates it.
The implementation:
Build a governance-as-code framework that includes data classification (automatically tagging PII, sensitive, public data), access control policies (who and what systems can access which data, with audit logging), lineage tracking (from raw source through transformations to AI model training data), and data contracts between producing and consuming teams.
Implement it using open-source tools: OpenMetadata or DataHub for the catalog, Great Expectations for data contracts, and your orchestrator’s built-in lineage tracking. Add a policy layer that automatically enforces classification-based access rules.
The AIfolio differentiator: Write a companion blog post explaining how your framework maps to EU AI Act requirements and organizational data governance policies. This transforms a technical project into a business-level asset. The original AIfolio article emphasized “documenting your design decisions” — this pillar is that principle taken to its logical extreme. You’re not just building infrastructure; you’re publishing the governance blueprint that other organizations can learn from. That’s the kind of thought leadership that gets you noticed by hiring managers and builds your professional reputation.
The Data Engineer’s AIfolio Tech Stack Cheat Sheet
You don’t need to learn everything. Here’s the focused stack, organized by what you actually need:
Your Core (Keep and Deepen): SQL, Python, dbt, Airflow/Prefect/Dagster, Snowflake or Databricks or BigQuery, Kafka
Add for AI Readiness: Vector databases (pgvector for Postgres teams, Qdrant or Pinecone for dedicated), embedding models (OpenAI API for prototypes, Hugging Face for self-hosted), LangChain/LlamaIndex for RAG orchestration, MCP SDK for AI integration layers
Add for Observability: Monte Carlo (study the concepts even if you use open-source), Great Expectations + custom anomaly detection, OpenMetadata or DataHub for AI-era data cataloging
Add for Streaming AI: Kafka + Flink for real-time embedding pipelines, Feast for feature stores
AI Copilots to Master Now: GitHub Copilot (universal), Snowflake Cortex Code (if on Snowflake), Altimate Code (open-source, dbt + SQL native)
Deployment (Your AIfolio Needs Live Links): Streamlit Community Cloud or Hugging Face Spaces (free, zero-config — for dashboards and demos), Vercel + Supabase (full-stack AI apps with pgvector), any major cloud free tier for containerized services
What Separates a Good Data Engineer’s AIfolio From a Great One
Building the five pillars is necessary but not sufficient. The original AIfolio article laid out a presentation layer that applies just as forcefully here — with some data-engineering-specific additions.
Every project needs a README that sells — with architecture diagrams. Hiring managers spend less than two minutes on a GitHub repo. For data engineers specifically, an architecture diagram isn’t optional — it’s the first thing they look for. Show the full pipeline: sources → ingestion → transformation → vector store → retrieval → LLM response. Show the monitoring layer. Show the governance layer. A clean Mermaid diagram in your README communicates more architectural thinking than a thousand lines of code.
Deploy everything with a clickable link. A pipeline without a live demo is a pipeline that doesn’t exist. Deploy your RAG pipeline’s query interface to Streamlit. Deploy your data quality dashboard. Deploy your MCP server and show an AI assistant querying your data live. Hugging Face Spaces, Streamlit Community Cloud, and Supabase all offer generous free tiers. There’s no excuse.
Add observability — especially on your data pipelines. This is where data engineers have a natural advantage over AI engineers building AIfolios. You already think about monitoring, alerting, and debugging in production. Integrate Langfuse or LangSmith for AI observability, and combine it with your existing pipeline monitoring. Show metrics: latency per query, retrieval precision, embedding freshness, data quality scores over time. This is the kind of production thinking that makes a hiring manager think “this person can build real systems.”
Document your design decisions — with trade-off reasoning. Why did you choose pgvector over Qdrant? Why did you set chunk size to 500 tokens with 15% overlap? Why did you use semantic chunking for some document types and recursive splitting for others? Write this up — in a blog post, a detailed README section, or even a short companion article. The original AIfolio article made this point for all developers: the reasoning reveals more than the code. For data engineers, the specific trade-offs you’ve navigated (cost vs. performance, freshness vs. computational overhead, governance strictness vs. developer velocity) are the exact conversations hiring managers want to have in interviews.
Be explicit about AI tool usage. Note in your documentation: “Used Cortex Code to generate initial dbt model definitions, then customized the chunking logic and added data quality tests manually” or “Used Copilot to scaffold the Airflow DAG structure, then wrote the embedding generation and quality monitoring operators by hand.” This signals a modern mindset. As one engineering leader put it: the goal isn’t to pretend you don’t use AI — it’s to show you use AI to accelerate the routine work so you can spend your time on the architectural decisions that matter.
Connect your pillars into a system. This is the meta-move that elevates a data engineer’s AIfolio above a list of disconnected projects. Your RAG pipeline (Pillar 1) feeds into your data quality monitoring (Pillar 2). Your semantic layer and MCP server (Pillar 3) provides governed access to the same data. Your embedding pipeline (Pillar 4) keeps the RAG system current in real-time. Your governance framework (Pillar 5) wraps the entire system in compliance and auditability. When a hiring manager can trace the connections between your projects and see a coherent data architecture rather than five isolated repos — that’s when they know you think like a staff engineer.
What Actually Gets You Hired
The pillars give you the what to build. The presentation layer gives you the how to show it. But after conversations with founders and hiring leaders at companies building AI-native data infrastructure, four traits emerged that determine whether you get the offer.
1. You understand that machines are the new data consumer. The shift from human-facing dashboards to AI-facing data infrastructure is the defining change of this era. Every architectural decision you make — schema design, data quality thresholds, freshness requirements, access patterns — should account for the fact that your primary consumers are increasingly models, not analysts. When you can articulate how this changes your design decisions, you signal that you’ve internalized the shift.
2. You have a point of view on data architecture trade-offs. “Should we use a dedicated vector database or pgvector?” is a question every data team is debating. Having a specific, defensible answer — backed by your actual project experience — matters more than having built the project in the first place. “I started with pgvector because our team already knew Postgres, and at our scale (under 10M vectors) the performance was comparable to dedicated solutions. I’d switch to Qdrant if we hit 50M+ vectors or needed sub-5ms p99 latency.” That answer gets you hired. Your AIfolio is the evidence that your opinions are earned, not theoretical.
3. A learning mindset that’s visible in the work. Does your commit history show iteration — not just “initial commit” and “final version,” but a progression of experiments, dead ends, and improvements? Does your README explain what you tried that didn’t work? Did you start with fixed-size chunking, measure the retrieval quality, switch to semantic chunking, and document the improvement? A data engineer’s AIfolio that shows measured, iterative improvement signals something tutorials never can: you know how to diagnose and fix problems in production AI systems.
4. You think about governance before someone makes you. The organizations that will win the AI race are the ones that can deploy AI without creating compliance disasters. Data engineers who proactively build governance frameworks — data contracts, lineage tracking, access controls, PII classification — are the ones who end up in the room where strategic decisions are made. You stop being a cost center and start being a profit enabler. Your AIfolio’s Pillar 5 is the proof.
Your Minimum Viable Data Engineer’s AIfolio
If you’re a data engineer reading this and feeling overwhelmed, here’s the path in order:
Month 1-2: Build Pillar 1 — your RAG-ready data pipeline. Install pgvector on your Postgres instance. Learn how embeddings work. Build a RAG pipeline over real documents (legal docs, technical documentation, research papers — not toy datasets) using your existing Airflow/dbt setup for orchestration. Add data quality checks on your chunks. Deploy the query interface to Streamlit or Gradio. One project, deployed, with a clean README and architecture diagram.
Month 3-4: Build Pillar 2 — AI-powered data quality. Add anomaly detection to your most critical tables. Start with statistical methods, then layer in ML-based detection. Connect it to your Pillar 1 pipeline so it monitors the data feeding your RAG system. Document what your system catches that hand-written rules miss. Deploy the monitoring dashboard.
Month 5-6: Build Pillar 3 — your semantic layer with MCP. Create an MCP server that exposes your data warehouse through a governed semantic layer. Show that an AI assistant can query your data correctly and safely. This is the pillar that makes hiring managers lean forward — almost nobody has built this yet.
When ready: Build Pillars 4 and 5. Add a real-time embedding pipeline (Pillar 4) to keep your RAG system current without full re-indexing. Build the governance framework (Pillar 5) when you’re ready to make the case for staff-level roles.
Throughout: Master an AI copilot for data engineering. Use Copilot for your daily SQL and Python work. Try Cortex Code if you’re on Snowflake. The productivity gains are real — developers report 88% productivity increases — and showing that you use AI as a power tool signals a modern mindset.
The hand-coded ETL pipeline is the new to-do app. It proves you completed a tutorial. It signals nothing about whether you can design the data infrastructure that AI systems depend on.
The original AIfolio replaced the traditional developer portfolio with proof that you can architect AI systems. A data engineer’s AIfolio goes one layer deeper — proof that you can build the data infrastructure those AI systems can’t function without.
Your pipelines don’t end at a dashboard anymore. They end at a vector store. At a feature store. At an LLM’s context window. At a governed semantic layer that lets AI systems understand organizational knowledge without creating compliance nightmares.
The data engineers who build this AIfolio won’t just survive the AI era. They’ll own the infrastructure layer that makes the entire AI era possible.
That’s not a bad position to be in.
Start building.
Very informative. I am not a Data Engineer but I work with folks who are. This shift is real. I see two specific things in my day to day work:
1. The best data engineers are increasing thinking about systems and interdependencies
2. They are learning to work with and identify gaps in AI native tooling.
AIfolio is a solid resource.
Thanks Neha, Every space is evolving, I have recently had multiple such conversations with Data folks who are building, learning and exploring. All the questions converges to How AI is being leveraged and how it is being involved in Data lens. I am sure there is more coming as well