

Context Engineering for Code Agents: A Four-Level Spectrum
Context Engineering for code agents is the discipline of deciding what the model knows about a codebase, its conventions, and the organization at inference time.

TL;DR. The productivity outcome of a coding agent is dominated by the context pipeline that wraps it, not by which frontier model it runs. The same Claude or GPT, embedded in a snippet-aware harness, behaves as a passive autocomplete; in a repo-aware harness, as a useful collaborator; in an org-aware harness, as something approaching a teammate. The model did not get smarter between those scenarios. The pipeline around it did.
Context Engineering for code agents is the discipline of deciding what the model knows about a codebase, its conventions, and the organization at inference time. This deep-dive maps four levels - snippet-aware, file-aware, repo-aware, org-aware and what fails at each, then walks through the concrete tools and practices a team can use to move up. The bottleneck for the next twelve months of coding-agent productivity is retrieval quality, not raw model capability. The recommendation: audit where a team sits on the spectrum and invest in the next level up rather than the next model upgrade.
What is Context Engineering for code agents?
Context Engineering for code agents is the discipline of deciding what information about a codebase reaches the model at inference time. Most of the variance in coding-agent output quality across teams using the same model traces to differences in this pipeline. This article defines four levels of context, explains where most production tools sit, identifies what fails at each, and lays out the concrete moves a team can make to reach the next level.
The inversion: same model, different harness
In a 2023 randomized trial conducted with GitHub Copilot, developers given Copilot completed an HTTP server task 55.8% faster than the control group. The task was to implement an HTTP server in JavaScript from scratch. There was no existing codebase to be wrong about, no team conventions to violate, no internal modules to import correctly.
In a 2025 randomized trial published by METR, 16 experienced developers working on mature open-source repositories, averaging more than a million lines of code, on projects they had contributed to for an average of five years, were 19% slower with AI tools than without. Participants predicted they would be 24% faster before the study. After the study, they still estimated they had been 20% faster. The tools allowed were Cursor Pro with Claude 3.5 and 3.7 Sonnet, the frontier configuration at the time.
A February 2026 METR follow-up complicated the picture. A new cohort showed a 4% point estimate of speedup (within a confidence interval of -15% to +9%), and the subset of original participants who returned for the late-2025 study showed an 18% speedup. METR also noted that 30 to 50% of invited developers declined to participate without AI access, a selection effect that biases the sample. The early-2025 slowdown was likely real for that setting, and late-2025 tools probably help, but the underlying productivity numbers depend heavily on the context regime, not just the model release.
The two trials are not in tension. They measure two different things. The GitHub setup required no codebase context. The METR setup required everything: cross-file dependencies, project conventions, decade-old architectural decisions, undocumented quirks. The model did not change between settings. The context regime did.
The pattern shows up in benchmarks too. Anthropic’s published evaluation of Claude Opus 4.5 on SWE-bench Pro reports a resolve rate of 52.0%, run under Anthropic’s own scaffolding with a 200k context window. Scale AI’s standardized SEAL evaluation of the same Opus 4.5 weights, running the mini-swe-agent harness with a 250-turn limit, returns 45.9%. Roughly six points of measured performance, on identical model weights, attributable to how the surrounding agent retrieves context and orchestrates tool calls. Neither lab is wrong. They are measuring the same model in two different context regimes.
Context Engineering, restated for code
Context Engineering - covered at length in the Model Reliability Engineering chapter on Context Reliability, is the discipline of deciding what reaches the model at inference time. For code agents, that decision operates on a four-level spectrum:

Each level adds context the previous level cannot see. Each level eliminates a class of failure the previous level produces. Each level introduces new failure modes that the next level addresses. The remainder of this piece walks the four levels in order.
Model Reliability Engineering: Who Owns It When the AI Is Confidently Wrong?

TL;DR: Companies deploying LLMs in production are discovering a reliability gap that none of the existing engineering disciplines — SRE, MLOps, AI Safety — are designed to close. Infrastructure stays up. Pipelines keep running. Models keep generating. But the outputs users depend on can be wrong, inconsistent, or unsafe, and no team owns that problem. W…
Level 0: Snippet-aware
At the bottom of the spectrum, the model sees only what is highlighted or typed at the cursor. Paste a function into ChatGPT and ask for a refactor: that is snippet-aware. The original GitHub Copilot completion, before workspace integration, was effectively snippet-aware, a small window of surrounding code and nothing else.
Snippet-aware tools are useful for self-contained problems. Writing a Fibonacci function. Rewriting a loop as a list comprehension. Generating an HTTP server in JavaScript from scratch. This is the regime in which the 55%-faster claim lives.
The failure modes are predictable. The model hallucinates import paths because it has no view of which modules exist in the project. It uses naming conventions that contradict the rest of the codebase. It suggests patterns that are plausible in general but wrong here. None of these are model failures. They are context failures: the model was asked to write code for a system it cannot see.
Level 1: File-aware
One step up, the model gets the entire current file along with the cursor position. Most production IDE integrations work this way for inline completions. GitHub Copilot uses a technique called fill-in-the-middle, sending both the prefix - code before the cursor, and the suffix, code after, so the model completes the middle. File-aware context handles intra-file consistency well. The model sees the imports already in use, the local naming conventions, the types declared higher in the file.
The failures show up at file boundaries. The user object referenced three files away has a username field, not name, but the model does not know that, because the user definition lives in a file it cannot see. The middleware that wraps every route handler in the project is not in the current file, so the model writes a route handler that bypasses it. These are not edge cases. They are most of real software work.
Level 2: Repo-aware
The middle of the spectrum is where most production coding tools sit in 2026. The model gets retrieved context from across the repository: relevant files, related symbols, similar implementations. The implementation varies, but three dominant approaches are worth distinguishing because they fail differently.
Embedding-based retrieval. The repository is chunked into semantically meaningful pieces, each chunk is converted into a vector embedding, and the embeddings are stored in a vector database. At query time, the user’s question is embedded and a nearest-neighbor search returns the most similar chunks. Cursor’s implementation is the canonical example: a Merkle tree detects which files have changed so that only changed chunks need re-embedding, embeddings are cached by chunk content, and the resulting vectors are stored in Turbopuffer for fast nearest-neighbor retrieval. Sourcegraph Cody layers BM25 keyword ranking alongside embeddings to handle exact-match queries that pure embedding search would miss.
Graph-based retrieval. Instead of treating code as text, this approach parses the codebase into syntax trees, extracts definitions and references, and builds a directed graph where edges connect symbols that reference each other. Aider was the first widely adopted tool to take this approach: it uses tree-sitter to extract a “repo map,” runs PageRank over the reference graph, and selects the most structurally important code into the context window within a token budget. The token budget is configurable, defaulting to a small allocation that Aider dynamically resizes as the chat evolves.
Agentic search. The newest approach lets the model decide what to read. Claude Code, GitHub Copilot’s agent mode, and Cursor’s agent mode all give the model file-reading and search tools and let it iterate. Rather than pre-computing relevance, the agent issues searches, reads files, and accumulates context as it works. The trade-off is latency and cost: agents that search well spend a substantial fraction of their wall-clock time searching rather than generating, and that search time is what closes most of the gap between standardized and agent-driven SWE-bench scores.
Repo-aware retrieval eliminates the file-boundary failures of Level 1. It does not eliminate the rest. The index is bounded by the default branch, feature branches and uncommitted work usually fall outside it. Cross-repository dependencies are typically invisible. Most critically, the index knows what the code is, not what the team thinks about it: which patterns are blessed, which are deprecated, which paths require human review.
Level 3: Org-aware
The top of the spectrum is the level most teams claim to be at and very few actually reach. Org-aware context extends beyond the repository to include the conventions, constraints, runbooks, incidents, and policies that govern how an engineering organization actually works.
The mechanism most consistently exposed in production tools today is hierarchical instruction files. Claude Code reads CLAUDE.md files in a priority order — enterprise policy, project memory, user memory, with higher-priority files loaded first and lower-priority files building on them. GitHub Copilot reads .github/copilot-instructions.md at the repository root and applies it to every chat interaction. These are not retrieval indexes. They are persistent, always-loaded instructions that travel with every prompt. Used well, they encode “always run bun test before committing,” “this monorepo uses Workspace, never Project,” “the payments service uses event sourcing, the catalog service does not.”
The deeper layer - runbook integration, incident-linked retrieval, ownership-aware routing, audit trails of which context shaped which output — is genuinely frontier. The teams reaching it are combining a repo-aware backbone with Model Context Protocol servers that surface internal documentation, ticket history, and policy databases. The failure modes here are organizational, not technical: instruction overload (models stop reliably following arbitrarily long instruction lists), conflicting priorities across instruction sources, and no clean way to audit which piece of context produced which line of code.
A Level 3 pipeline gives the model not only what the code is but why it is that way - which patterns were deliberate, which paths require human review, what happens when a downstream call fails, who owns the service the change is touching.
The diagnostic: where is your team?
Three questions surface a team’s actual level.
When the AI suggests an import, does it ever name a module that does not exist in the project? If yes, you are operating at Level 0 or 1. The model has no view of which modules are available.
When the AI suggests a pattern, does it sometimes use a convention from a sibling service that does not apply in the service being edited? If yes, you are at Level 2 - indexed across boundaries that should be scoped. This is the dominant failure mode of repo-aware tools in monorepos.
When the AI writes code that touches a production-adjacent system, does it know what happens if the call fails - what the retry policy is, who owns the downstream service, whether there is a runbook entry for the failure mode? If no, you are below Level 3, regardless of which tool you are using.
Most teams sit at the boundary between Level 2 and Level 3, with tools capable of indexing the repository but with little or no organizational context wired in. Most teams also believe they are higher on the spectrum than they actually are.
Why the next model will not fix this
Within a model generation, scaffolding now matters more than model selection. The Anthropic-versus-Scale comparison above is one instance of a broader pattern: the same model weights produce materially different SWE-bench Pro scores depending on the scaffolding wrapped around them. Context retrieval is the bottleneck the next release will not fix, because the bottleneck is upstream of the model.
This has a strategic implication for any team budgeting AI productivity gains. The next model release will be marginally better at the work the current model already does well, and approximately as bad at the work the current model does badly - because the badness is a context-pipeline problem, not a model problem. The investments that compound are upstream: indexing quality, retrieval ranking, structured organizational context, audit trails. The investments that do not compound are model upgrades, with each new release delivering smaller deltas than the last.
Building the pipeline: practices and tools for teams starting out
The investments compound from Level 0 upward. Each transition has a small number of concrete moves.
Getting from Level 0 to Level 1 is the cheapest move available. Stop pasting code into chat windows. Use an IDE-integrated tool that has access to the file being edited and the cursor position. GitHub Copilot, Cursor, Continue.dev, and Sourcegraph Cody all support this baseline in their free or low-cost tiers. The practice that matters more than the tool: keep open in the editor the files the model will need to see. Most tools include currently open files in context first, so the developer’s tab management is itself a context-engineering decision.
Getting from Level 1 to Level 2 requires turning on workspace or codebase indexing and choosing a retrieval strategy. Three viable paths:
Embedding-based retrieval. Cursor’s
@Codebase, Sourcegraph Cody, and Continue.dev with repository indexing all fall here. Best suited to unfamiliar codebases where natural-language queries over the code carry value, and where exploration is part of the workflow.Graph-based retrieval. Aider is the open-source canonical option, using tree-sitter parsing and PageRank-ranked symbol graphs; Sourcegraph Cody’s Code Graph runs a similar layer alongside its embedding pipeline. Best suited to codebases where structural relationships — who calls what, who defines what — carry more signal than text similarity.
Agentic search. Claude Code, GitHub Copilot’s agent mode, and Cursor’s agent mode let the model decide what to read at runtime. Latency and cost rise, but cross-file reasoning improves substantially. Best suited to longer tasks where the model needs to chase references across many files.
Two practices matter at this level regardless of which family is chosen. Configure .cursorignore, .copilotignore, or the equivalent so that generated code, vendor directories, build artifacts, and lock files are excluded from indexing — feeding these to the retriever pollutes the result ranking. And scope the index to a single coherent unit. In a monorepo, indexing across service boundaries produces the dominant Level 2 failure mode: completions that import or pattern-match from sibling services with different conventions.
Getting from Level 2 to Level 3 is the highest-leverage move and the most under-invested. Three concrete starting points:
Hierarchical instruction files. For Claude Code, write a project-level
CLAUDE.mdat the repository root capturing the conventions that matter: test runner, naming rules, error-handling patterns, what not to modify without review. The CLAUDE.md hierarchy layers enterprise policy, project, and personal levels. For Copilot, the equivalent is.github/copilot-instructions.md, with path-specific*.instructions.mdfiles for subdirectories that have different conventions. An emerging cross-tool convention isAGENTS.md, which a growing number of agents read alongside their native instruction files.MCP servers for organizational context. Model Context Protocol servers expose internal data sources, ticket trackers, internal documentation, runbook stores, ownership databases, to any coding agent that supports the protocol. The teams furthest along on Level 3 today are wiring MCP servers to incident records, on-call documentation, and architectural decision records, so the agent has access to why the code is the way it is, not just what it is.
Path-specific or service-specific rules. Different parts of a codebase often have different conventions. Path-specific instructions — Copilot’s
*.instructions.mdwithapplyToglobs, or directory-levelCLAUDE.mdfiles — let teams encode “the payments service uses event sourcing; the catalog service does not” without polluting unrelated work.
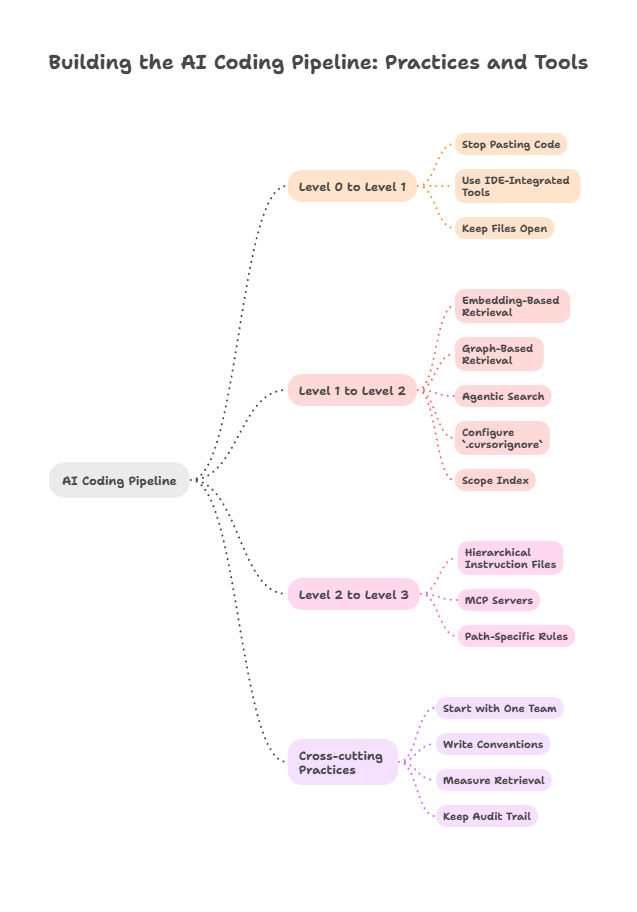
Cross-cutting practices that apply at any level:
Start with one team and one repository. Org-wide rollouts before the pipeline works produce the disappointment that gets blamed on the model in the next quarterly review.
Write instructions as conventions, not theory. “Use the BaseRepository pattern for new persistence layers” beats “follow SOLID principles.” Concrete project-specific guidance is what models can apply; abstract principles get paraphrased into nothing.
Measure retrieval before output. When the model produces wrong code, instrument what it retrieved before it generated. Most output failures trace to a retrieval failure upstream, and most output improvements compound from retrieval improvements.
Keep an audit trail of which context shaped which output. The lightweight version is logging which files were in the model’s context window per session. The heavier version uses MCP server logs and agent-mode tool-call traces, so that a code review can answer “what did the model see when it wrote this?”
Operating the pipeline: ownership when requirements change
A working Context Engineering pipeline introduces three responsibility questions that did not exist before the agent was in the loop.
Who owns the code the agent produced?
The developer who accepted the suggestion owns it. The agent has no accountability; the developer does. In principle this changes nothing about PR review. In practice, it changes what the reviewer needs to see. A reviewer approving an AI-influenced change without knowing what the agent had in its context window is approving code without knowing what informed it. The audit trail practice above, logging which files were in the context per session, persisting agent-mode tool-call traces, is what makes that review tractable. Treat it as a requirement of any Level 2 or Level 3 rollout, not an optional add-on.
Who keeps the context current when requirements change?
This is the under-discussed cost of the pipeline. A CLAUDE.md written six months ago and never revised is worse than no CLAUDE.md at all, it confidently encodes assumptions that no longer hold, and the model will follow them. When a feature or requirement changes, a payment provider swap, a deprecated module, a new error-handling convention, a renamed service, someone has to update the instruction files that reference the old behavior, invalidate or re-index the relevant chunks if the retrieval layer caches by content hash, refresh the data sources behind MCP servers when they point to authoritative docs that have changed, and communicate the change to other teams whose path-specific instructions may reference the same convention.
This responsibility belongs to whoever owns the convention being changed. The service owner whose team renamed a module owns updating the instructions that mention it. The platform team that deprecates a library owns flagging it in the relevant *.instructions.md files. Rolling out AI tooling without this maintenance loop produces agents that confidently suggest deprecated patterns for months after a migration.
Who is accountable when requirements change mid-flight?
For agentic tasks, Claude Code running unattended, Cursor agent mode chewing through a backlog, scheduled agent runs against a CI pipeline, the question of who notices when a requirement changes mid-task is non-trivial. The default answer is the developer who kicked off the agent, but for longer-running work this answer is insufficient. The practice emerging in production is the human checkpoint: pre-defined points in the agent’s flow where it pauses for review before proceeding. This is partly harness design and partly process design. The harness has to support it; the team has to define where the checkpoints sit; the developer has to be available to clear them.
A four-role operating model.
Teams that explicitly assign the following roles outperform teams that treat the pipeline as something that runs itself:
Pipeline owner - usually an architect or staff engineer. Owns which retrieval strategy is sanctioned, what tools are approved, what gets indexed, what does not.
Convention owner - usually a tech lead per service or area. Owns the section of the instruction files that governs their service and updates them when conventions change.
Code author - the developer in the session. Owns the code that ships, including the code the agent produced.
Reviewer - the PR reviewer. Owns verification, and can only verify what the audit trail makes visible.
The roles are not new responsibilities so much as old ones made explicit. Code authors and reviewers already exist in any mature engineering organization. The pipeline owner and convention owner are the roles that often go unnamed when a coding-agent rollout begins and the absence is the reason most rollouts plateau at Level 2 with a static, decaying instruction file at Level 3.
Closing
The four-level spectrum is not a maturity ladder to be climbed once. It is a continuous engineering surface: every new repository starts somewhere on it, and every change to the codebase, the tooling, or the team’s conventions moves the effective level up or down. Treating context as infrastructure measured, versioned, audited is what separates a team whose AI tooling compounds over time from a team that re-discovers the same failure modes with every model release.