

Dario Amodei’s “Policy on the AI Exponential” Describes a World Banking AI Already Lives In
His new essay asks regulators to build an FAA for AI models. If you ship AI inside a bank, you already work in that regime, and there is a five-minute test that tells you whether your agent is as far

The short version: Anthropic’s CEO just published Policy on the AI Exponential, asking for an FAA-style regulator that tests frontier models and blocks the unsafe ones before release. For most of the industry that is a new idea. For anyone building AI inside a bank, it describes the regime they have worked in since 2011, under a rule called SR 11-7. The interesting part is not the policy. It is that banking already has a working maturity curve for regulated AI agents, the acceptance criteria are published, and most teams sit two levels lower than they claim. Below is how to score your own agent, including a counterfactual test that exposes the most common lie a regulated AI tells.
Banking already built the thing the essay asks for
His argument is that AI moves faster than policy can react, so frontier models should be tested by qualified third parties and blocked if they fail. The coverage fixated on the FAA comparison.
Banks have run a version of it for fifteen years. In 2011 the Federal Reserve and the OCC issued SR 11-7, the supervisory guidance on model risk management, later adopted by the FDIC. It rests on three pillars: sound development and use, independent validation, and governance with board accountability. The load-bearing idea is effective challenge, meaning critical analysis of a model by objective, competent people whose job is to find its limits. Examiners treat it as a baseline expectation, not a best-practice suggestion, and it covers machine learning, not just regression.
So if you build AI in a bank, the FAA the essay wants is not your future. It is the room you already stand in. Which makes the useful question simple: how mature is your agent inside that room, measured honestly?
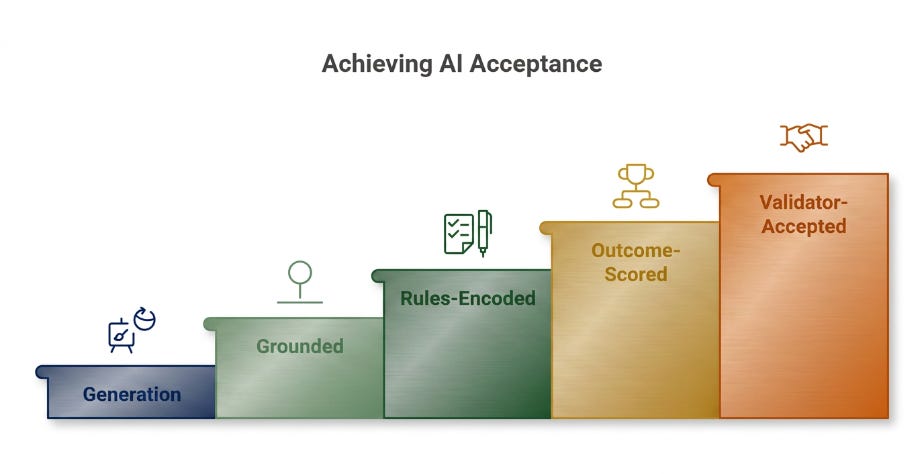
The five levels, and the test that proves each one
Think of a credit-decisioning agent or an AML investigator as climbing five levels. The point of the levels is not the label. It is that each one has a specific eval that proves you are actually on it. If you cannot run the eval, you are not on the level.
Level one: it writes. A fluent credit memo or suspicious-activity narrative from a prompt, with nothing real underneath. No eval needed, because there is nothing to verify.
Level two: it is grounded. Every claim in the output traces to a record: the financials, the bureau pull, the transaction history, the bank’s own policy. The eval is a groundedness rate. Sample outputs, extract each factual claim, and check how many trace to a source. Anything below near-total is a hallucination problem, and a validator will find it before you do.
Level three: it follows the rules. The output carries the regulatory format: adverse-action reason codes that satisfy ECOA and Regulation B, the required SAR elements, SR 11-7 documentation. The eval is a schema pass rate. Run a structured validator over a few hundred outputs and check that every required field is present and every reason code comes from the approved set. Most bank AI tooling reaches here, and here is where teams stop, because the output finally looks finished.
Level four: the establishment grades it, not you. Your eval set is now owned by the people who challenge your model. Validation pass rate: how often does effective challenge accept the model versus send it back. Adverse-action dispute rate. AML alert precision, filed SARs over alerts raised, against a baseline where roughly 95% of rule-based alerts are false positives. You are no longer measuring whether the document reads well. You are measuring what the regulator and the validator do with it.
Level five: it is accepted as evidence. The validator, then eventually the examiner, takes the model’s own output as proof rather than redoing the work. The model’s stated reason becomes the legally sufficient denial reason. No bank is fully here, and the essay is, in effect, arguing the whole industry should build toward it.
The eval that earns the share
Here is the test most regulated AI fails, and the one worth running first.
The CFPB stated in 2022 that a black-box model does not excuse a lender from giving a specific, accurate reason for every denial, and that a reason approximated after the decision is not enough, because it has to reflect the factors actually used. Read as an engineer, that is a faithfulness requirement on the explanation, and it is testable.
Take a denial where your system told the applicant the main reason was, say, debt-to-income. Change only that input, push debt-to-income into the approving range, hold everything else fixed, and re-score. If the decision does not flip, debt-to-income was not actually driving it. The reason you gave the applicant was a plausible story, not the cause, which is exactly the post-hoc approximation the CFPB rejects.
Run that counterfactual across a sample of denials and you get a reason-faithfulness rate: the share of stated reasons that actually move the decision. Most teams have never run it, and most are shocked by the result, because their reason codes come from a feature-importance library bolted on after the model, not from the decision itself. A level-three system passes the format validator and fails this test. That gap, looks compliant, is not faithful, is the single most useful thing to measure in regulated AI, and it is invisible to every demo.
This is also why level four matters more than it looks. Wiring the counterfactual check, the validation-survival rate, and the dispute rate back as your evaluation set is the move from grading your own homework to letting the establishment grade it. SR 11-7’s demand for effective challenge by independent validators is the same idea written into law: your model has to survive evaluation by an adversarial party you do not control. The thing Dario is asking regulators to impose on frontier models, banking already imposes on its own.
Why this is not only a banking problem
The pattern repeats wherever an external body owns acceptance: a regulator, an independent validator, a court. The value of your agent is capped by how much of that body’s judgment your harness has internalized, and the only honest measure of progress is their response, not your output. Pharma teams are watching the FDA write those criteria now. Banking has had them since 2011. The curve is identical. Only the establishment changes, which means the bank team that nails the counterfactual reason test is building the playbook insurance, legal, and healthcare teams will copy.
The honest catch
There is a fair argument that the top level never arrives. A regulator that accepts a model’s self-explanation as sufficient has given up some of the judgment it exists to apply, and the CFPB’s whole point was to distrust the black box. Weigh the messenger too: the person urging regulators to formalize AI testing runs an AI company, published the essay the day after shipping a new model, and critics have already called the broader proposal regulatory capture.
It does not change the practitioner takeaway. Even if no regulator ever accepts raw model output as standalone evidence, the criteria they enforce decide how much work your system is allowed to carry, and banking has the clearest published version of those criteria anywhere. The teams that read them as eval specs, not compliance paperwork, are the ones who will still be standing when the audit comes.
Where this leaves you
Score your most important regulated agent on the five levels, then run the counterfactual reason test on a sample of its outputs. If the stated reasons do not move the decisions, you are not where you think you are, no matter how clean the output looks. The banks that measure faithfulness instead of fluency are quietly building the standard every regulated industry will inherit when its own FAA finally arrives.
