

The Anatomy of an AI Legal Agent
The leading AI legal research tools still hallucinate on up to a third of queries, so the production answer in law is not a better model but a harness built to assume the model is wrong.

TL;DR. In every other vertical, a wrong answer costs money. In law, a wrong answer that reaches a court costs a sanction, a malpractice exposure, and sometimes a license. That asymmetry is why the deployable unit in legal AI is never the model. It is the harness around it: the grounding layer that forces every legal proposition back to a retrieved primary source, the verification gate that refuses to pass an unverifiable citation, and the checkpoint router that decides which work product a human must sign. The two best-funded legal agents on the market, valued at eleven billion and two billion dollars, are not selling models. They are selling that harness. Before a legal agent ships, run one audit: take its last twenty outputs and try to trace every legal claim to a source it actually retrieved. The fraction you cannot trace is the real reliability number.
A legal agent is a production AI system whose defining component is verification, not generation. The model drafts; the harness proves. Across the leading deployments, the architecture converges on the same shape: retrieval grounded in primary law, a citation-verification gate that blocks unprovable claims, a checkpoint router that assigns a human reviewer by task risk, and an audit trail that survives discovery. The model is the smallest part. What surrounds it is what separates a tool a partner will sign behind from a tool that ends a career.
Why legal is the hardest reliability problem in vertical AI
Most vertical agents operate where errors are recoverable. A misrouted support ticket gets reassigned. A mispriced transaction gets reversed. Legal work has no such buffer once it reaches a tribunal. A fabricated citation in a filed brief is not a bug report; it is a Rule 11 violation.

The reference incident is already three years old and still defines the field. In June 2023, the Southern District of New York sanctioned two attorneys five thousand dollars after they filed a brief containing six judicial opinions that did not exist. A general-purpose chatbot had generated the cases, complete with names, citations, and quoted passages, and when one of the attorneys asked the tool to confirm the cases were real, it said yes. They were not. What looked at the time like an isolated embarrassment turned out to be the first documented instance of a structural failure mode. By late summer 2025, one count put the number of documented AI-hallucination legal filings above three hundred, with more than two hundred recorded in 2025 alone. The pattern was not confined to one tool or one court: a different general-purpose chatbot surfaced fabricated citations in a high-profile matter, and by early 2024 a federal appeals court had referred an attorney to a grievance panel for filing nonexistent AI-generated cases.
The profession’s governing body responded with a rulebook. In July 2024 the American Bar Association issued its first formal ethics opinion on generative AI, Formal Opinion 512, mapping the technology onto existing duties: competence under Model Rule 1.1, confidentiality under 1.6, candor to the tribunal under 3.3, and supervision under 5.3. The opinion’s operational core is that verification is not optional and not uniform. The required level of independent review is factually specific and depends on the tool and the task: generating ideas demands less scrutiny than reviewing a document, and in no case can the tool substitute for a lawyer’s own competent judgment. Because forty-nine of fifty states have adopted the core structure of the Model Rules, that opinion functions as a de facto national baseline rather than advice a firm can ignore.
Two duties beyond candor shape the deployment itself. Confidentiality under Model Rule 1.6 protects all information relating to a representation, which means a legal agent cannot route privileged material to a model endpoint that retains or trains on its inputs absent informed client consent. Data isolation is a precondition of the architecture, not a configuration toggle. Privilege and work-product doctrine compound the point: the audit trail the harness keeps to prove its own outputs is itself potentially discoverable, so how it is scoped and retained is a legal decision before it is an engineering one.
In law, verification is not a feature of the product. It is the legal duty the product exists to discharge.
This is the constraint every legal agent inherits. The duty to verify cannot be delegated to the thing producing the output. So the architecture has to externalize verification into a layer the model does not control.
The reliability floor no model has cleared
The instinct is to assume the problem is solved by retrieval. Wire the model to a database of real cases, ground every answer in retrieved text, and the fabrications stop. The vendors who built exactly that marketed it as the cure. The first independent measurement found otherwise.
Researchers at Stanford’s regulatory lab and human-centered AI institute ran the first preregistered empirical evaluation of the proprietary legal research tools that sit at the center of practice. The study, later peer-reviewed and published in the Journal of Empirical Legal Studies, tested the retrieval-augmented systems from the two dominant legal publishers across more than two hundred hand-scored legal queries. The conclusion was blunt: the providers’ claims are overstated. The tools hallucinated between seventeen and thirty-three percent of the time. Broken out, one publisher’s tool erred on roughly one in six queries and the other on roughly one in three, against forty-three percent for the raw general-purpose model used as a baseline.
Two findings inside that result matter more than the headline. First, retrieval helps and does not cure. Grounding the model in real law cut the error rate roughly in half versus the bare model, but a one-in-three failure rate on a tool sold as hallucination-free is not a rounding error. Second, the errors are not only invented cases. They include mischaracterizing a real case, citing inapplicable authority, and misstating what a rule says, which are harder for a busy associate to catch than a citation that simply does not resolve.
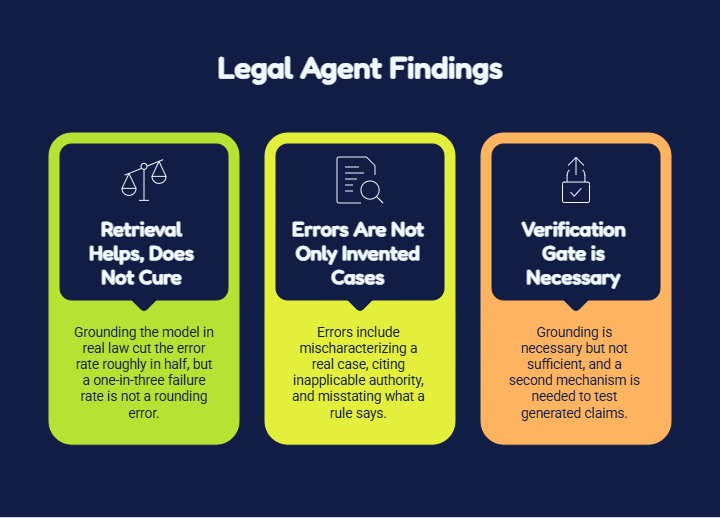
The architectural lesson is precise. If retrieval alone leaves a double-digit error rate, then grounding is necessary but not sufficient, and the harness needs a second mechanism downstream of retrieval whose only job is to test whether each generated claim is actually supported by the retrieved source. That mechanism is the verification gate, and it is the component that distinguishes a legal agent from a legal chatbot.
What a legal agent actually is
A production vertical agent decomposes into seven layers wrapping the model, the reference architecture set out in Vertical Agent Anatomy. Three of those layers carry almost all the weight in law, because the legal constraint loads them in a way no other vertical does.
The first is grounding. A legal agent does not answer from parametric memory. It retrieves the controlling authority, statute, regulation, case, or contract clause, and constrains generation to what it retrieved. This is table stakes, and as the Stanford measurement showed, it is also not enough on its own.
The second is the verification gate, and this is the layer that defines the vertical. After the model drafts, the harness re-derives every legal proposition against the retrieved corpus before anything reaches a human. Does the cited case exist. Does it say what the draft claims. Is it still good law. Is the quoted passage real. A claim that fails any check is flagged or dropped, not surfaced as a confident answer. The reason a verification gate is non-negotiable here and optional elsewhere is that the duty of candor makes an unverified citation a professional violation regardless of whether anyone catches it.
The third is the checkpoint router. Legal work is not uniformly risky, so the harness does not apply uniform review. It routes by task: a first-draft research memo for internal use carries different review than a brief headed for filing. The clearest articulation of this pattern comes from the field’s most rigorous benchmark effort, which frames deployment as a question of whether an agent can do all, some, or none of a given task and assigns the human review tier accordingly. The router is where the ABA’s task-specific verification standard becomes code.
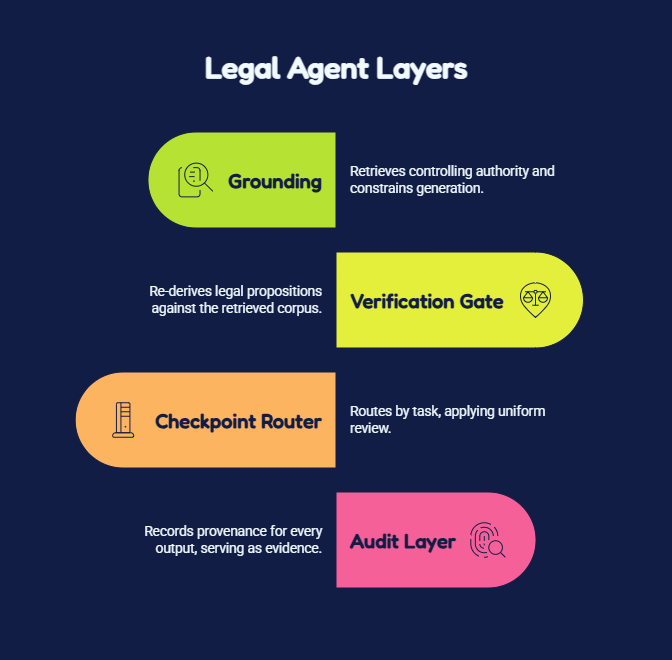
Around those three sits the audit layer, which records provenance for every output: what was retrieved, what the model generated, what the gate verified, who reviewed it. In a vertical where work product can be subpoenaed, the audit trail is not telemetry. It is evidence.
The production landscape
The market has already priced this thesis. The two highest-valued legal agents are explicit that the moat is the harness.
The research-and-drafting platform most associated with large law firms reached an eleven-billion-dollar valuation on the strength of an architecture it benchmarks obsessively. Its team built and published its own evaluation suite, and in May 2026 released an open-source legal agent benchmark containing more than twelve hundred tasks across twenty-four practice areas, graded against more than seventy-five thousand expert-written rubric criteria, with backing from every major frontier lab. The benchmark is structured to mirror how work is assigned and reviewed at a firm: an instruction, a client matter with real materials, and a work product that a human must sign off on. On the company’s own internal suite, vendor-published results put the strongest frontier model above ninety percent (these are the vendor’s own benchmark and methodology, not an independent measurement). The instructive part is not the score. It is that a company at this valuation spends its research budget building the measurement layer, because in legal the harness improves only as fast as the firm can measure where it fails. The same team’s research-specific benchmark goes further still: built with a data-labeling partner, it requires a model to use search tools, locate relevant context, and return cited responses end to end, which is the verification gate expressed as a test rather than left to run silently at inference time. The company has said it is expanding that public benchmark more than fivefold across global law, practice areas, and legal research, a sustained investment in measurement that only makes sense if the harness, not the model, is the thing being engineered.
The drafting side tells the same story from a different vertical slice. The category leader in personal injury raised a hundred and fifty million dollars in October 2025 at a valuation above two billion, bringing total funding to three hundred and eighty-five million. Its platform runs a proprietary model trained on hundreds of thousands of injury cases and millions of medical records, drafting demand letters and case documentation that human attorneys review. The company reports its case volume roughly doubling to ten thousand cases per week in six months (a vendor-reported operating figure), in a personal injury market it sizes at sixty-one billion dollars. The lead investor was a firm whose prior rounds it had already joined, and the round included the venture arm of the company that owns one of the legal research publishers the Stanford study measured, a strategic alignment worth noting when reading any single vendor’s reliability claims. The depth of the segment is visible in the company that raised a hundred and three million dollars for the plaintiff side the same week.
Map these to the architecture and the pattern is clean. The research platform’s benchmark obsession is the verification gate and the checkpoint router, instrumented. The drafting platform’s proprietary model trained on case-specific data is the grounding layer, specialized. Neither company’s pitch is that its model is smarter than a frontier model. The pitch is that its harness turns a frontier model into something a firm will deploy.
Where the harness saturates
The strongest argument against this thesis is that the model is catching up. A 2025 randomized controlled trial found that modern AI tools measurably improved lawyers’ work relative to working without them, and vendor benchmarks now show frontier models clearing ninety percent on firm-grade tasks. If the model reaches the point where it almost never fabricates, does the verification gate become dead weight.
It does not, for a reason specific to the vertical. In a domain where a single fabricated citation is sanctionable, the cost function is not the average error rate. It is the tail. A model that is right ninety-nine percent of the time still produces a fabricated authority once every hundred filings, and one fabricated authority in a filed brief is a Rule 11 problem no matter how good the other ninety-nine were. The verification gate is not insurance against a bad model. It is the mechanism that converts a probabilistic system into one whose output a human can attest to under a duty of candor. That requirement does not relax as the model improves; it is structural.
There is a real saturation risk, but it runs the other way. Pile on enough gates, retrieval constraints, and mandatory human checkpoints and the system stops being an agent at all. It becomes a deterministic retrieval-and-citation-check pipeline with a model bolted on for phrasing, the point of Harness Saturation. For low-risk, high-volume drafting that may be exactly right. For genuinely novel legal reasoning it is a ceiling. The design question for any legal agent is not how many gates to add. It is which tasks tolerate near-total gating and which need the model’s judgment to survive contact with the harness. The benchmark that grades tasks as all, some, or none is, read correctly, a map of where on that spectrum each workflow sits.
There is a second-order trap the Stanford measurement exposed. The tool with the higher error rate also produced markedly longer answers than the more reliable one, and more words mean more falsifiable propositions and more surface area for a claim to be wrong. A harness tuned to produce thorough, expansive output inflates its own verification burden. Concise grounded answers are not only easier to read; they are cheaper to verify, which in this vertical is the same as saying cheaper to trust.
FAQ
Do AI legal research tools still hallucinate?
Yes. The leading independent study found the major retrieval-augmented legal research tools hallucinate between seventeen and thirty-three percent of the time, well below the raw model baseline but far above any rate acceptable for unverified use. Retrieval reduces the problem; it does not remove it.
What is the review pattern in legal AI?
It is the deployment model where an agent produces a work product and a human reviews it before use, with the depth of review set by task risk. The most developed benchmark formalizes this by grading whether an agent can do all, some, or none of a task, which tells a firm where to set the checkpoint.
Does a better model remove the need for verification?
No. Because a single fabricated citation in a filing is sanctionable under Rule 11 and the duty of candor, the cost is driven by the worst output, not the average. Verification is what lets a human attest to the output, and that obligation is structural, not a function of model quality.
What does the ABA require for AI use in legal work?
Formal Opinion 512 maps generative AI onto existing duties of competence, confidentiality, candor, and supervision, and requires verification calibrated to the tool and the task. It is advisory, but functions as a national baseline because most states share the Model Rules structure.
What to do Monday
Take the last twenty outputs your legal agent produced. For each one, try to trace every legal proposition, every case, every rule, every quoted passage, back to a source the system actually retrieved. Count the propositions you cannot trace. That fraction is your hallucination exposure, and it is a more honest deployment signal than any benchmark score, because it measures the layer that determines whether a human can sign the work. If the number is not near zero, the gap is not in the model. It is in the gate.
The Anatomy of a Production Vertical Agent

TL;DR - Production AI agents in regulated industries — clinical documentation at Abridge, prior authorization at Anterior, patient engagement at Hippocratic, customer experience at Sierra, mortgage origination at Rocket and Tavant — have converged on a seven-component architecture. The LLM is the smallest of those seven. The other six do the load-bearin…