

Why Every Browser Harness Wrapper Is on Borrowed Time
Six hundred lines of code, no abstractions, and the argument that every wrapper around the LLM is on borrowed time.

TL;DR - Richard Sutton’s “bitter lesson”, that general methods leveraging compute consistently beat handcrafted abstractions over the long run - applies more aggressively to browser harnesses than to almost any other part of the agent stack. Twelve months of evidence suggests the abstractions teams have built between the language model and the browser are not durable: NL-DSLs are being absorbed into foundation-lab computer-use models, planner-validator multi-agent topologies are being absorbed into longer-horizon model loops, and the carefully-curated tool definitions that ship with Stagehand, browser-use, and Skyvern are being out-competed by raw Chrome DevTools Protocol access. The most architecturally honest harness shipped in 2026 is browser-use’s Browser Harness, roughly 600 lines of code that hold a CDP websocket, expose a workspace where the agent writes its own helpers mid-task, and persist those helpers as a domain skill. The argument is uncomfortable for the SDK layer of this market and worth taking seriously anyway: the harness layer survives the next cycle only by becoming thinner.
The bitter lesson, restated for harnesses
Sutton’s original 1,143-word essay made a simple empirical observation about AI research over seventy years: methods that leverage general-purpose computation, search and learning, consistently outperform methods that encode human domain knowledge. The pattern repeated in chess, Go, speech recognition, computer vision, and language modeling. Researchers built increasingly clever feature engineering and increasingly intricate domain-specific abstractions; general methods with more compute beat them every time.
The translation to harness engineering is sharper than it looks. A browser harness sits between two compute layers: the language model on one side, the browser substrate on the other. The harness’s job is to mediate between them. Every primitive the harness exposes is, in Sutton’s terms, an encoding of human domain knowledge about how the model and the browser should interact. Every cache key is an encoding of which signals the harness thinks matter for determinism. Every accessibility-tree extraction is an encoding of which page representation the harness thinks the model can reason about.
The bitter lesson, applied to harnesses, is the prediction that all of those encodings will be outperformed by general methods - that is, by the language model talking to the browser substrate directly, with the harness providing only the substrate access and not the semantic interpretation.
The evidence for this prediction has been accumulating for twelve months. The interesting question is not whether the harness layer survives. It does. The question is what the durable subset of that layer looks like, and where the inevitable collapse leaves teams that built on the wrong abstractions.
What got commoditized in twelve months
The clearest evidence comes from the trajectory of foundation-lab computer-use models against the trajectory of harness-shipped abstractions over the past four quarters.
In Q2 2025, the harness layer had three structurally distinct topologies: code-first, NL-DSL, vision-CUA, each producing measurably different outcomes on common benchmarks. Stagehand’s act, extract, and observe primitives were genuinely additive over raw Playwright. Skyvern’s planner-and-validator multi-agent architecture moved the WebVoyager score from 45% to 85.8%. Browser Use’s Agent.run(task=...) was a primitive nobody else had.
By Q4 2025, the foundation labs had absorbed most of that surface. Anthropic’s Claude Sonnet 4.5 shipped with a computer_20250124 tool definition and an OSWorld score of 61.4%, up from Sonnet 4’s 42.2% just four months earlier. That 19-point jump was achieved with no harness-layer changes. The model itself got better at grounding actions in screenshots, planning over multi-step horizons, and recovering from intermediate failures. OpenAI’s o3-based computer-use-preview — exposed in the Responses API at $3/$12 per million tokens, scored 87% on WebVoyager out of the box. Google’s Project Mariner added Teach & Repeat as a primitive: learn a workflow once, replay it deterministically. That is what Stagehand v3 caching, Anchor’s b0.dev, and Skyvern’s workflow recording are. The foundation lab built it into the browser extension directly.
By Q1 2026, the most architecturally interesting open-source release in the harness space was a deliberate stripping-away of abstractions: browser-use’s Browser Harness, at roughly 600 lines of code. The team published their reasoning in The Bitter Lesson of Agent Harnesses, the argument that every layer of wrapping is a constraint on a model that was already pretrained on millions of CDP tokens. Strip the wrapper away. Expose the substrate. Let the model build the abstractions it needs at runtime, in code, on disk, in a persistent workspace it can read and write.
Twelve months. Three distinct topologies converged to the same conclusion: less wrapping is better.
What the thin-CDP harness actually does
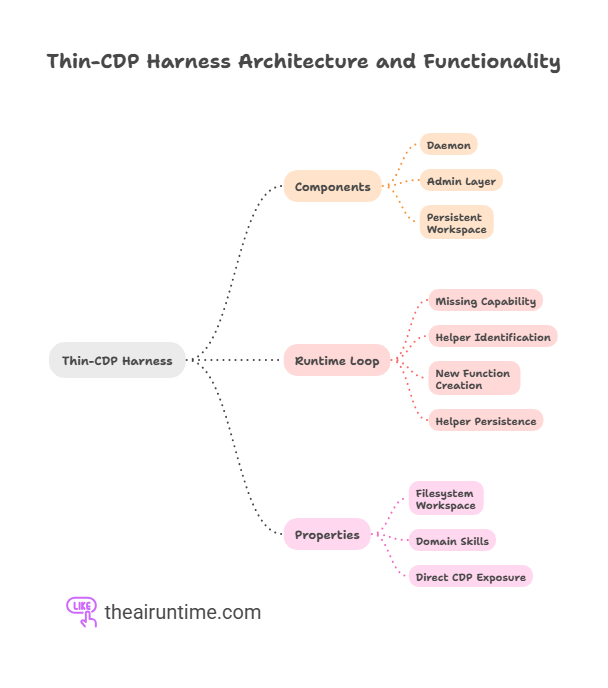
Browser Harness is short enough to read in an afternoon, but the architectural decisions inside it are doing a lot of work. The system has three components: a daemon that holds the CDP websocket open, an admin layer that surfaces helpers in agent-workspace/agent_helpers.py, and a persistent workspace under agent-workspace/domain-skills/<domain>/ where the agent’s authored functions accumulate over time.
The runtime loop is unusual. When the agent encounters a missing capability, drag-and-drop, file upload, dialog handling, iframe traversal, it does not call a pre-built helper from a framework. It reads the existing helpers, identifies the pattern, writes a new function following the same conventions, and immediately uses it. The helper persists across the session and, on subsequent runs against the same domain, becomes part of the working surface the agent inherits.
This is not new code-generation. It is a structural argument: the abstractions worth having are the ones the model can author and maintain at runtime against the specific surfaces it encounters, not the ones a framework author tried to anticipate in advance.
Three properties make the pattern non-trivial.
The workspace is a filesystem, not a vector store. The agent reads other helpers as raw source code, with comments and patterns intact. The model’s pretraining included hundreds of millions of source files; reading source code is what it does best. A vector-indexed memory layer would optimize the wrong dimension, semantic retrieval over symbol-level inspection.
Helpers persist as domain skills, not session state. A successful flow against availity.com writes to agent-workspace/domain-skills/availity.com/. The next session against the same domain inherits the accumulated helpers. Over time, the workspace converges toward a working library for the surfaces the team automates, which is exactly what a hand-written Playwright codebase converges toward, except the model authored it.
The daemon exposes CDP directly, not Playwright. Every layer of intermediation is a layer the model has to learn around. The model already knows CDP from pretraining. Adding Playwright between the model and CDP is adding human-curated semantic interpretation over a substrate the model can reason about natively. Sutton’s lesson applied to API surface area.
What this means for Stagehand, browser-use, Skyvern, Libretto
The honest read is that none of the major harness frameworks are dead, and none of them are durable in their current form.
Stagehand v3 is the strongest counter-argument to the thin-CDP thesis. Browserbase’s response to the commoditization risk was to rebuild Stagehand on top of CDP directly (dropping Playwright as a hard dependency), make the LLM provider swappable through a Model Gateway, and ship aggressive caching at the SDK and server layers. The architecture is no longer “wrap Playwright with NL primitives.” It is “wrap CDP with NL primitives, cache the resolutions, fall back to LLM on cache miss.” That is meaningfully closer to the thin-CDP position than to the v2 architecture. The remaining commoditization risk for Stagehand sits in the act, extract, and observe primitives themselves, if Sonnet 4.5 or its successor can ground an action in a screenshot reliably, the NL layer becomes optional. Browserbase’s bet is that caching plus Browserbase Cloud’s infrastructure makes the package durable even if the SDK layer alone is not.
Browser Use has clearly read the bitter lesson and is hedging across both positions. The original Agent.run(task=...) Python SDK is still the public-facing surface. But the same company shipped Browser Harness as a separate repo specifically to articulate the thin-CDP argument. The bu-ultra hosted model (89.1% on WebVoyager) is the bet that full-stack optimization, own browser infrastructure, own stealth, own CAPTCHA solving, own filesystem, own tool orchestration, is the durable moat even as the SDK abstraction commoditizes.
Skyvern is the most exposed. The planner-validator multi-agent architecture that took Skyvern from 45% to 85.8% on WebVoyager is exactly the kind of carefully-engineered domain abstraction that the bitter lesson predicts will be out-competed by general methods. The 19-point Sonnet 4.5 jump on OSWorld in four months is the relevant trajectory. Skyvern’s Web Bench publication, 5,750 tasks across 452 live sites, is a smart move precisely because it shifts the comparison to harder benchmarks where the multi-agent topology still matters. But the underlying compute-vs-abstraction trade is not going to reverse.
Libretto is in an interesting position because it has chosen the topology least exposed to the bitter lesson. Code-first deterministic generation is not an abstraction over the model. It is an abstraction over the output. The model still authors the code, but the runtime is deterministic Playwright with version-controlled selectors and auditable behavior. As the model gets better at authoring code, Libretto’s value increases rather than decreases. The trade-off is the topology’s narrower applicability: regulated industries, bounded counterparty lists, audit-trail-critical workflows.
The two surviving patterns
If the bitter lesson is even directionally right, two harness patterns survive the next eighteen months and a third does not.
Pattern one: the model authors deterministic code, the harness runs the code. Libretto’s pattern. The model is in the loop at build time and at repair time. At runtime, no model inference happens. Selectors are committed, version-controlled, and auditable. As foundation-model code-generation improves, the harness gets more powerful without the harness needing to change. The risk is narrow applicability: this pattern only works where determinism is more valuable than flexibility, which is true for regulated industries but not for the long tail of consumer and exploratory workloads.
Pattern two: the harness is a thin substrate access layer, the model authors abstractions at runtime. Browser Harness’s pattern. The substrate is CDP, the workspace is a filesystem, the abstractions are agent-authored helpers that persist as domain skills. As foundation-model capability grows, the harness’s surface area shrinks rather than expanding. The risk is build cost on the first run against a new surface and the absence of guardrails for teams that need them.
Pattern three: wrap the model with NL primitives and ship them as the durable interface, is the one the bitter lesson predicts will not survive in its current form. Stagehand’s response is to push the abstraction down to CDP and ship caching plus infrastructure as the moat. Skyvern’s response is to push to harder benchmarks where the multi-agent topology still matters. Browser Use’s response is to hedge across both positions simultaneously. None of these are wrong responses. But they are responses to a structural problem that the SDK layer was not architected for.
What this means for the next eighteen months
The implications, in order of confidence.
The harness layer is not going to disappear. State, replay, auth, observability, anti-bot, and concurrency are not problems that the model solves. They are problems the system around the model solves. The infrastructure layer of this market - Browserbase, Steel, Anchor, Hyperbrowser, Bright Data, Apify, has structural durability that the SDK layer does not.
The SDK layer is becoming a customer-acquisition channel for the infrastructure layer. Stagehand exists primarily to feed Browserbase. Browser Harness exists primarily to feed browser-use Cloud. Skyvern OSS exists primarily to feed Skyvern Cloud. Pure-OSS SDK companies will have a hard time monetizing without a coupled paid backend, and the SDK abstractions themselves are not the durable IP.
Regulated industries are a safe harbor. The thin-CDP pattern is not a fit for healthcare, banking, insurance, or legal because the audit-trail problem is not solved by “the model authored a helper at runtime.” Libretto’s code-first pattern is durable in these verticals specifically because the bitter lesson does not apply where determinism is the requirement.
The agent-authored skill pattern is going to spread beyond browsers. The idea that the model writes domain-specific helpers that persist as a skill, and that subsequent sessions inherit those helpers, generalizes to any opaque surface - desktop applications driven by computer-use, internal portals, RPA targets, vendor consoles. Browser Harness’s agent-workspace/domain-skills/<domain>/ directory layout is the prototype of a pattern that other surfaces will copy.
The interesting axis of competition is shifting. Cache validation strategies, fallback model selection, recovery primitives, and credential-handoff protocols are where the differentiation lives now. The topology argument, code-first vs NL-DSL vs vision-CUA vs thin-CDP is going to look quaint by mid-2027.
The contrarian read
There is a respectable counter-argument worth naming. The bitter lesson is an empirical observation, not a theorem. It has been wrong before, in specific cases, for sustained periods.
The strongest counter to the thin-CDP thesis is that browsers are not chess positions. The substrate is adversarial. Sites change weekly. Bot detection runs ML on mouse curves and timing. CAPTCHAs evolve. The infrastructure around the model - proxies, fingerprinting, residential IP rotation, CAPTCHA solving, is genuinely hard to reduce to “more compute against a general method.” The harness has to absorb that complexity somewhere, and the SDK layer is one defensible place to put it.
The second counter is that audit trails and reproducibility are first-class requirements in production. A workflow that runs differently each time because the model authored its helpers differently is not deployable in any regulated context, and is hard to debug even in unregulated ones. Determinism is a feature, not a constraint. The patterns that survive may be the ones that preserve determinism most aggressively, not the ones that strip the most wrapping away.
The third counter is the time horizon. Sutton’s lesson is a decade-scale observation. The current foundation-lab trajectory might continue for eighteen months and then stall - at which point the harness abstractions that look quaint today look essential again. Markets are not always efficient at pricing in long-term technical curves.
These counters are real. The architecturally honest position is to take the bitter lesson seriously without committing to a single topology. Build the deterministic skeleton in code-first or NL-DSL. Cache aggressively. Fall back to thin-CDP for the long tail. Plan for the SDK abstractions to commoditize without betting that they will.
The architectural ask
For an engineering team building or rebuilding a browser harness in 2026, the most useful framing is not which topology to commit to. It is which abstractions to expose to the model versus which to handle below the model.
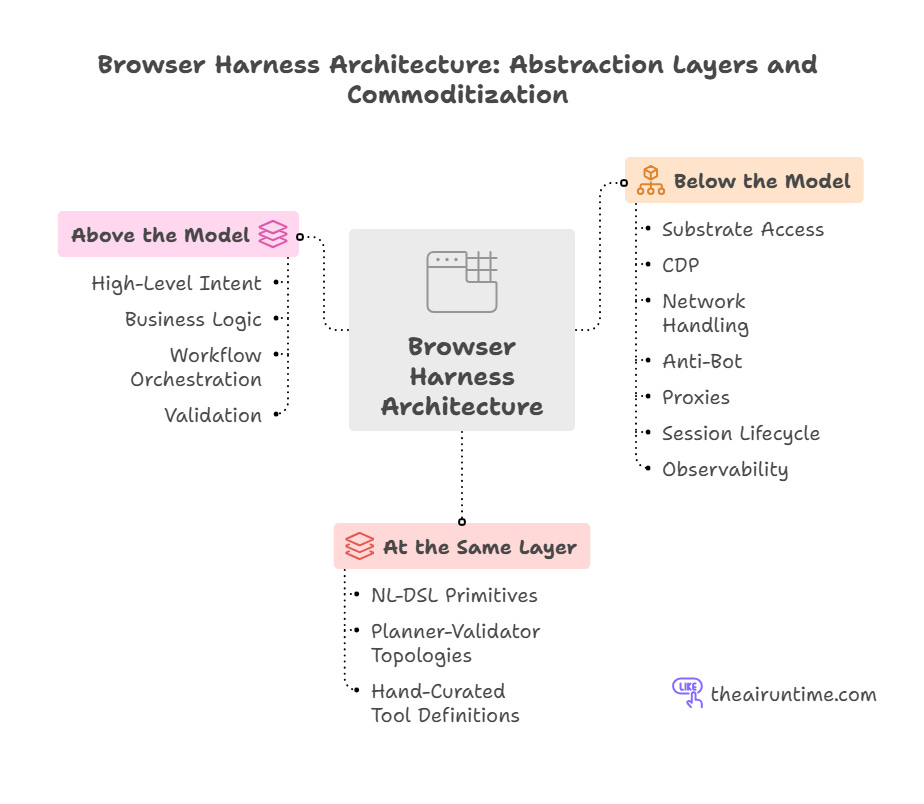
The abstractions that should sit below the model - substrate access, CDP, network handling, anti-bot, proxies, session lifecycle, observability - are not commoditizing. The infrastructure problem is genuinely hard and getting harder.
The abstractions that should sit above the model - high-level intent, business logic, workflow orchestration, validation, are application-layer concerns and have always been the team’s responsibility.
The abstractions that sit at the same layer as the model - NL-DSL primitives, planner-validator multi-agent topologies, hand-curated tool definitions — are the ones the bitter lesson predicts will commoditize. These are the load-bearing abstractions in Stagehand, Browser Use, and Skyvern. They are also the ones the foundation labs are absorbing fastest.
The pragmatic move is to ensure that the team’s harness investment is structured so that commoditization at the same-layer-as-the-model abstractions does not invalidate the below-the-model infrastructure investment or the above-the-model application logic. Hybrid topologies, aggressive caching, replay primitives, and decoupled provider gateways are the architectural patterns that survive that commoditization without rebuilding from scratch.
The Complete Field Guide to Browser Harnesses in 2026

TL;DR - The market for browser harnesses - the engineered layer between an autonomous agent and a live web page, has crystallized into four topologies in the last twelve months: code-first deterministic (Libretto, Healenium), NL-DSL hybrid (Stagehand v3, Browser Use, AgentQL), vision-LLM CUA (Skyvern, Anthropic Computer Use, OpenAI Operator, Project Mar…
Primary sources: Sutton, “The Bitter Lesson” (2019), browser-use Bitter Lesson of Agent Harnesses, Browser Harness repo, Stagehand v3 launch post, Anthropic Claude Sonnet 4.5 announcement, OpenAI Computer-Using Agent, Skyvern 2.0 and Web Bench, Libretto repo.