

Agents Can’t Sign Up, Demos Can’t Ship: Lessons from The AI Runtime Meetup
Two talks, one diagnosis — the infrastructure layer between AI capability and enterprise production is the bottleneck, and it isn’t being built by the model labs.

TL;DR - Two recent talks at The AI Runtime meetup converged on the same point from opposite ends. Ray Liao, co-founder of Inkbox, showed why every existing authentication system fails agents — login forms, email confirmations, social logins, manual API-key provisioning — and demonstrated agent-led self-registration with tiered, claim-based verification. Michael R. Schulte, an AI Builder at Harvard Business School, did a live build into the cal.com codebase and showed why the gap between demo and production is almost never a coding problem — it’s policy, security perimeter, and governance. The two talks address different layers of the same stack: Liao’s at the identity-and-onboarding layer, Schulte’s at the development-and-deployment layer. Both are saying the same thing: the infrastructure that turns AI capability into enterprise production doesn’t exist yet, and the practitioners building it are the ones doing the load-bearing work the field most needs. This piece walks both talks, draws the through-line, and lands on the operational takeaway for anyone shipping agentic features.
The setup
The AI Runtime meetup series brings together practitioners building production AI systems — engineers, founders, architects whose work involves shipping agentic features into real environments with real users, real audit trails, and real consequences when something breaks.
Two talks from the most recent meetup are worth treating together. The first, from the Inkbox co-founder, addresses a question that almost nobody is asking out loud yet but everyone deploying agents is hitting: how does an autonomous agent sign up for the services it needs to do its job? The second, from a builder at Harvard Business School, addresses a question that everyone has felt and few have framed correctly: why does a demo that works on a weekend take six months to ship inside an organization?
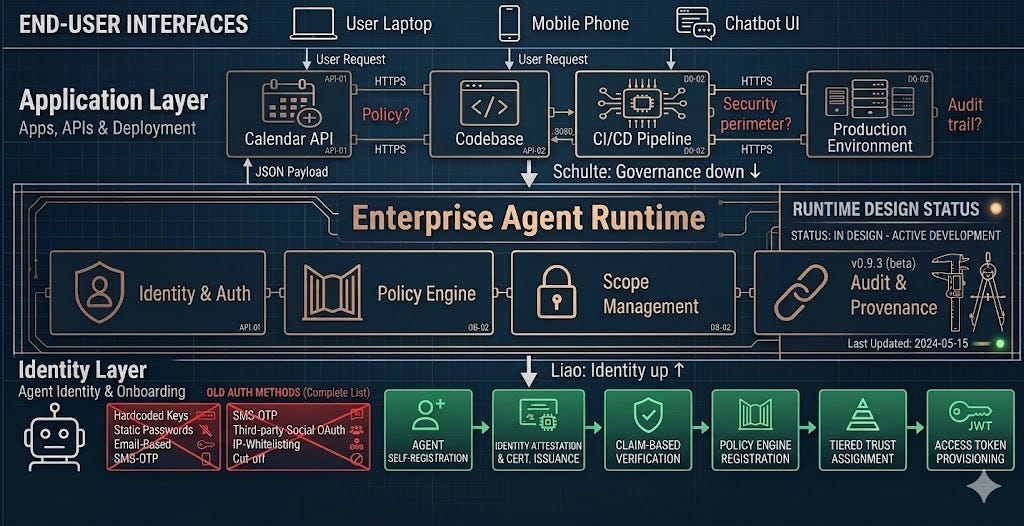
Treated separately, they’re two competent talks. Treated together, they’re a coordinated diagnosis: the production gap in agentic AI isn’t a model problem. It’s a plumbing problem. And the plumbing is being invented in real time by the people building infrastructure for agents at one end and shipping AI into enterprise codebases at the other.
Talk one: the human-shaped auth wall
Most web services today require a login flow designed for humans. Email signup with confirmation. Password creation with complexity rules. Social login through Google or GitHub. Optional 2FA. Welcome screen with a CTA tour. Account dashboard with billing setup. Every step of that flow assumes a human is present, has a mouse and a screen, can read a graphical interface, can wait for a confirmation email, can solve a CAPTCHA when the system gets suspicious. (See approximately 1:19–2:47 of the meetup video.)
None of that is a natural interface for an AI agent. Agents read text. Agents call APIs. Agents handle JSON. Agents do not have inboxes — or rather, they don’t have human inboxes; until very recently, they didn’t have inboxes at all. Agents do not have phone numbers. Agents cannot click “I agree” in a modal dialog without a browser-automation harness that itself depends on a human-shaped DOM.
The Inkbox co-founder framed this as the existing authentication stack being categorically wrong for the agent era. Not too restrictive. Not too permissive. Wrong. Built on the assumption that the actor is a human and that the artifacts of identity (email, phone, password, 2FA) are human-controlled.
The practitioner consequence is that almost every agentic workflow ends up needing a human in the loop precisely at the points where the agent is most productive — at signup, at credential rotation, at 2FA challenges, at scope-elevation prompts. The human becomes a synchronous dependency for the agent’s autonomy. Which means the agent isn’t autonomous. It’s a human-with-extra-steps.
The Inkbox answer: agent-led registration with claim-based verification
The Inkbox approach inverts the assumption. Instead of a human setting everything up before the agent runs, the agent handles its own onboarding. The mechanics, as demonstrated in the talk (approximately 3:16–5:25):
The agent reads a documentation file — Inkbox publishes a markdown index of its docs explicitly designed for agents to consume.
The agent sends a request to a public API endpoint to register itself.
The agent receives a scoped API key and can begin operating immediately.
There is no signup form, no email confirmation flow, no password to remember, no welcome modal. The artifact the human sees is a verification email — which is the point of human oversight, not the point of signup.
This is where the design gets subtle. Allowing autonomous registration without verification is an obvious vector for abuse. So Inkbox implements a tiered permission model (approximately 6:00–6:55 in the talk):
Before verification: the agent has scoped capability — for example, a maximum of ten sends per day and the ability to send only to the agent owner’s email address. The agent can do enough to be useful for prototyping and self-testing. It cannot do enough to be a serious abuse vector.
After verification: a human supervisor “claims” the agent by entering a six-digit code (or approving the agent in the Inkbox console). The agent’s capabilities expand — in Inkbox’s documented case, from ten sends per day to five hundred and from owner-only sending to sending anywhere — and resources from the unclaimed workspace transfer into the supervised environment (7:36–8:10).
The pattern is recognizable to anyone who has built a customer-facing product. It’s the email-verification flow, inverted: instead of an unverified human getting limited capability until they confirm an email, an unverified agent gets limited capability until a human confirms it. Same trust-graduation pattern. Different actor model.
More than an API key
A second move in the talk is harder to summarize and arguably more important. To function as first-class actors, agents need more than code execution and API keys. They need the artifacts of digital identity that humans take for granted: a place to receive messages, a number that can be called, a vault for secrets that survives across sessions.
Inkbox provisions virtual phone numbers and email inboxes as scoped resources tied to an agent’s identity. The agent can receive a 2FA code by SMS or email, in the same way a human would. The agent can be reached by a real person who needs to follow up. Conversations persist across channels - an agent that placed a call can follow up by email with full context - which is the consumer-grade communication primitive that backend integrations have never had to think about.
The secrets vault is the most operationally interesting piece. Inkbox’s zero-knowledge encrypted vault handles credentials, API keys, SSH keys, and TOTP secrets, with the explicit guarantee that Inkbox itself never sees the plaintext. This matters because the failure mode the whole industry is sleepwalking toward is that agents end up with broadly scoped credentials hardcoded in environment files or, worse, in prompts. A secrets-vault primitive designed for agents - with client-side encryption and per-agent scoping - is the kind of plumbing that is invisible until it isn’t there.
Why this matters beyond Inkbox
The agent identity space is being recognized as foundational infrastructure across the broader ecosystem. The OpenID Foundation published a whitepaper on AI agent identity challenges in October 2025 calling for evolution of existing frameworks. RSAC 2026 coverage flagged AI agent identity and next-generation enterprise authentication as one of the most prominent vendor themes of the show. Established identity providers like Auth0 are building agent-aware token vaults and fine-grained authorization for RAG pipelines. The convergence is unambiguous: the identity layer is being rebuilt for the agent era, and the open question is which patterns win.
The Inkbox pattern — agent self-registration with tiered, claim-based verification, plus a vault of identity artifacts (email, phone, secrets) scoped per agent — is one credible answer. The point is that somebody has to build this, and the practitioners shipping it now are doing it ahead of standards bodies, not in response to them.
Talk two: the greenfield delusion
The second talk, from the AI Builder at Harvard Business School, took on a different production-gap question: why do impressive AI demos so rarely make it to production?
The frame was sharp. Anyone with two hours and a current frontier model can build a slick demo over a weekend. The gap between that demo and a production-ready application running inside an organization is not a coding gap. The model can write the code; the engineer can review the code; the code can pass tests. That part is fast. What kills deployment is everything around the code: policy, security perimeter, infrastructure, audit, environment isolation, deployment workflow.
The speaker called this the “greenfield delusion” — the assumption that production deployment looks like the empty project folder where the demo was built. Production looks nothing like that. Production has a CISO. Production has a deploy pipeline with security review. Production has secrets that cannot be read by the AI assistant even when the developer asks nicely. Production has rollback requirements, audit logs, change-management approvals, and integration points that the demo never touched.
The talk made the point through a live build into the cal.com codebase — the open-source scheduling project often described as a Calendly alternative. Cal.com is a real, substantial Next.js codebase with an active community, multiple integrations, and the messy reality of a mature open-source product. It’s a perfect test bed because it has all the production texture (.env files with API keys, third-party integrations, multiple deployment paths) that a greenfield demo doesn’t have.
The four layers of the production gap
The talk walked four operational disciplines that bridge the demo-to-production gap. They are not novel — each has been written about in some form — but the synthesis is useful, and the demonstrated mechanics matter.
Guardrails and policy as system configuration. The first layer is preventing the agent from doing destructive things by default. The talk showed using a managed-settings.json file — the Claude Code mechanism for organization-wide policy that, per Anthropic’s documentation, cannot be overridden by user or project settings — to define what the agent is and isn’t allowed to do (approximately 2:57–3:44). The deny rules in this configuration are evaluated before allow rules and provide a hard security boundary for sensitive operations — file access patterns, command execution scopes, MCP server whitelists.
The point is structural: agent guardrails belong in a configuration layer that the developer cannot disable in the heat of a debugging session. The same way an organization wouldn’t let a developer disable SSO because it was inconvenient, it shouldn’t let a developer turn off disableBypassPermissionsMode because the agent kept asking for confirmation. Per the Anthropic Claude hardening guide, allowManagedPermissionRulesOnly: true ensures users cannot add their own allow rules to weaken the central policy.
Safe environments with secrets protection. The second layer is what the agent can read, not just what it can do. The talk demonstrated configuring access so the agent could not read sensitive files like .env, which in a real codebase like cal.com contains API keys and database passwords. Even if asked. Even if the developer wanted to give the agent enough context to debug a configuration issue.
This is more counterintuitive than it sounds. Most developers, in the moment, want to give the agent access to the failing file. The right architecture inverts that: the agent gets the kind of access it needs to do the work, not the specific files the developer happens to think it needs. Secrets are categorically excluded. Deny rules block them. The configuration is centrally managed.
Iterative planning with high-reasoning models. The third layer pulls the workflow back from “just generate code” to “plan, then execute.” The talk demonstrated using a planning phase with high-reasoning models - Claude Opus was the worked example - to define outcomes and tests before executing code modifications. The plan becomes the artifact the developer reviews. The code generation is the easy part. The plan is where judgment lives.
This is operationally the same insight that mature engineering organizations have always applied to risky changes: the design review, the RFC, the architecture diagram. The agent era doesn’t eliminate the need for these — it raises the cost of skipping them, because the agent can generate ten thousand lines of code in the time the developer can read two thousand.
Deployment workflow as security infrastructure. The fourth layer is the deployment process itself. The talk drew a sharp distinction between the consumer “click-and-publish” workflows that some AI-development tooling assumes and the real enterprise production reality. Real enterprise deployment involves security audits, containerized testing (Docker was the demonstrated example), and local verification before anything goes live.
The operational lesson is uncomfortable for vendors selling “from prompt to production in minutes”: that workflow is not what shipping into a real organization looks like, and pretending otherwise is the gap that kills demos in their third week of “almost there.”
The unifying lesson
Read the two talks side by side and the same diagnosis appears at both layers of the stack.
At the identity-and-onboarding layer, the existing infrastructure was built for human users. It assumes the actor has an inbox a human checks, a phone number a human answers, hands that can solve a CAPTCHA. When the actor is an agent, none of that is true, and every signup flow becomes a synchronous human dependency that defeats the agent’s autonomy. Inkbox’s answer is to build agent-first identity primitives — self-registration, tiered claim-based verification, a vault for the artifacts of identity (email, phone, secrets) - that treat agents as first-class actors rather than as humans-with-extra-steps.
At the development-and-deployment layer, the existing infrastructure was built for human-only engineering teams. It assumes a single accountable engineer who reviews every change, owns the credentials, knows the codebase intuitively, and operates under the security perimeter the organization has spent years defining. When the engineer is augmented by an AI agent that can read files, execute commands, and call external services, every assumption needs to be re-examined. The answer is to build agent-aware engineering primitives - managed policy configurations that the developer can’t override, environment isolation that excludes secrets categorically, planning phases that put judgment before code generation, deployment workflows that preserve the security audits and containerized testing the organization already requires.
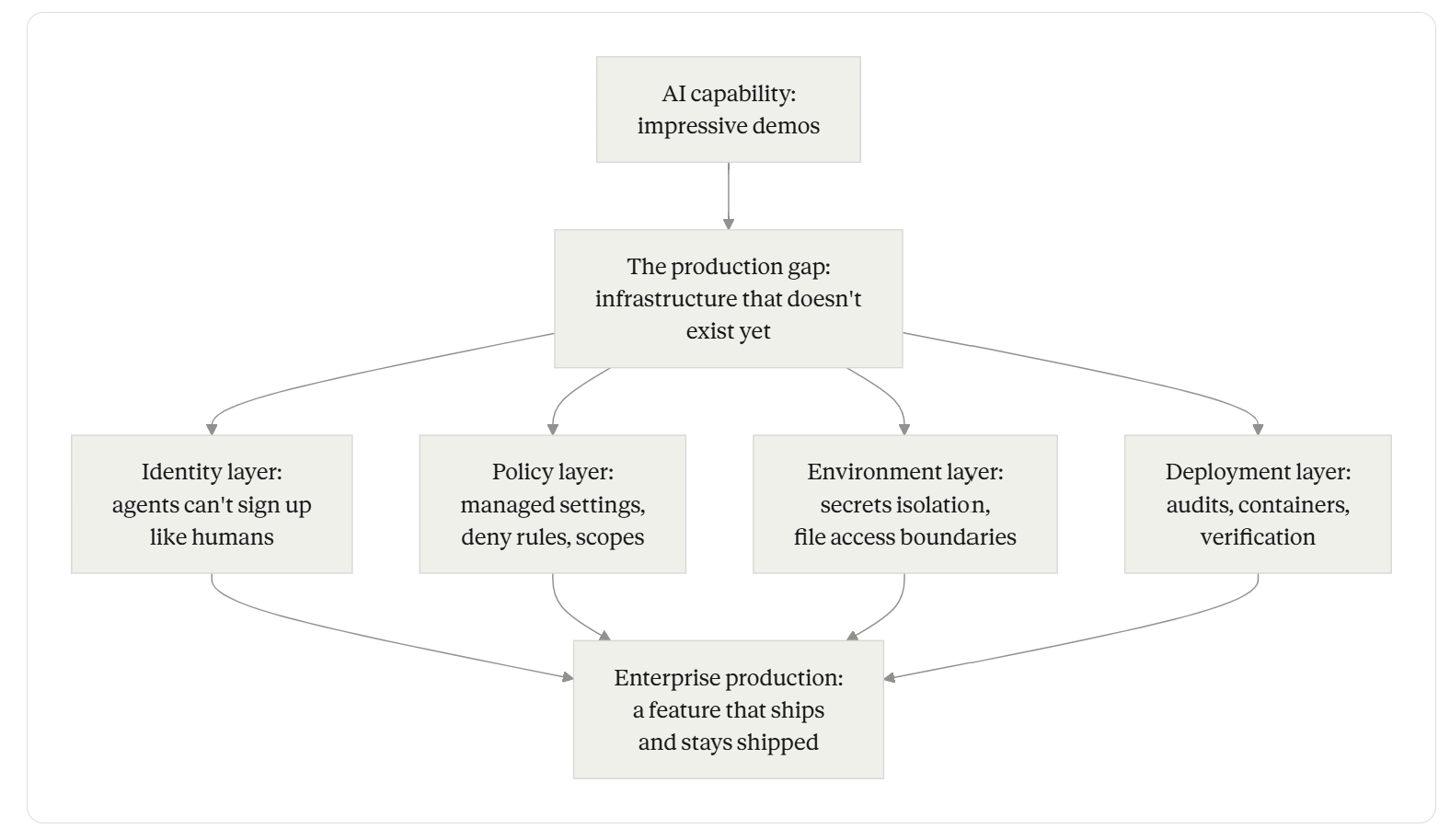
Both talks are saying the same thing: the production gap in agentic AI isn’t a model capability problem. It’s a plumbing problem. The models are good enough. The agents work. What’s missing is the layer underneath - the identity primitives, the policy configurations, the environment isolation, the deployment discipline - that turns a working agent into a shippable feature inside a real organization.
This is the unglamorous part. It’s not new model launches. It’s not benchmark beats. It’s the configuration files, the verification flows, the scoped credentials, the managed settings, the deploy pipelines. It’s exactly the kind of work that the model labs are not doing - because it’s the deployer’s responsibility, not the provider’s - and that most teams shipping agents are not yet doing systematically - because the field is still pretending the model is the bottleneck.
The production-gap diagram
What to build
For practitioners shipping agentic features, the takeaways from both talks compress into four actions you can take this week.
Treat identity infrastructure as a first-class engineering decision. Don’t bolt a human signup flow onto an agent and call it integration. Decide whether your agent needs a persistent identity - an inbox to receive replies, a phone number to be called back, a secrets vault that survives session restarts. If it does, treat that decision the way you’d treat any identity-stack decision: with auth model, scope model, and verification flow specified before the integration goes live. The Inkbox primitives are one shape this can take. The broader pattern - agent self-registration with tiered, claim-based verification - is reusable regardless of vendor.
Push agent policy into configuration, not into prompts. Prompt instructions are not security boundaries. Deny rules in a centrally managed configuration are. If your team is using Claude Code or a comparable agentic coding tool, deploy a managed-settings.json with deny rules for .env files, for sensitive directories, for write access to production paths, and with allowManagedPermissionRulesOnly: true so individual developers cannot weaken the policy. This is the cheapest unit of production hardening available right now, and the most consequential one organizations are skipping.
Categorically exclude secrets from agent context. Even when the agent says it needs them. Even when the developer thinks giving access is faster than debugging. The architectural rule is that secrets live in the vault the agent can interact with at runtime (via a scoped credential, a TOTP secret stored client-side encrypted, an injected environment variable available only to the executing process) - never in the files the agent reads as context.
Preserve the deployment discipline you already have. A working demo is not a working feature. A working feature is one that has passed the security audit, run in a containerized test environment, been verified locally, and graduated through the deploy pipeline the organization built before AI was in the picture. The agent accelerates the work inside this pipeline. It does not replace the pipeline.
Closing
Both speakers were building plumbing - at different layers, in different companies, with different vocabularies. The work is unglamorous, deeply specific, and almost certainly the most leveraged thing being done in agentic AI right now. New models will keep launching. New benchmarks will keep getting beaten. But the gap between AI capability and enterprise production won’t close because of any of that. It will close because somebody, somewhere, wrote the configuration file that lets the agent sign up safely, or shipped the deny rule that prevented the agent from reading the secret, or built the deployment workflow that put the agent inside the audit trail instead of outside it.
That’s the lesson from the trenches. The plumbing wins.

